文件读取:
data_train = pd.read_table(‘G:\python\PYproject\Titanic/train_20171215.txt‘,header=None,encoding=‘gb2312‘,delim_whitespace=True,index_col=0)
#导入txt格式的数据
#header=None:没有每列的column name,可以自己设定
#encoding=‘gb2312‘:其他编码中文显示错误
#delim_whitespace=True:用空格来分隔每行的数据
#index_col=0:设置第1列数据作为index
train = pd.read_csv(‘G:\python\PYproject\House Prices/train.csv‘)
#读取csv文件
******************************************************************************
plt.scatter(data_train.Survived, data_train.Age)
#plt.scatte()用法:http://blog.csdn.net/qiu931110/article/details/68130199
**********************************************************************************
fig = plt.figure()
fig.set_figheight(6)
fig.set_figwidth(12)
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
ax1.hist(train.SalePrice)
ax2.hist(np.log1p(train.SalePrice))
#画直方图,明白条形图和直方图的区别,直方图中包含出现频率信息,总的面积为1,np.log1p()为球对数
****************************************************************************************************************************
Pandas所支持的数据类型:
1. float
2. int
3. bool
4. datetime64[ns]
5. datetime64[ns, tz]
6. timedelta[ns]
7. category
8. object
默认的数据类型是int64,float64.
************************************************
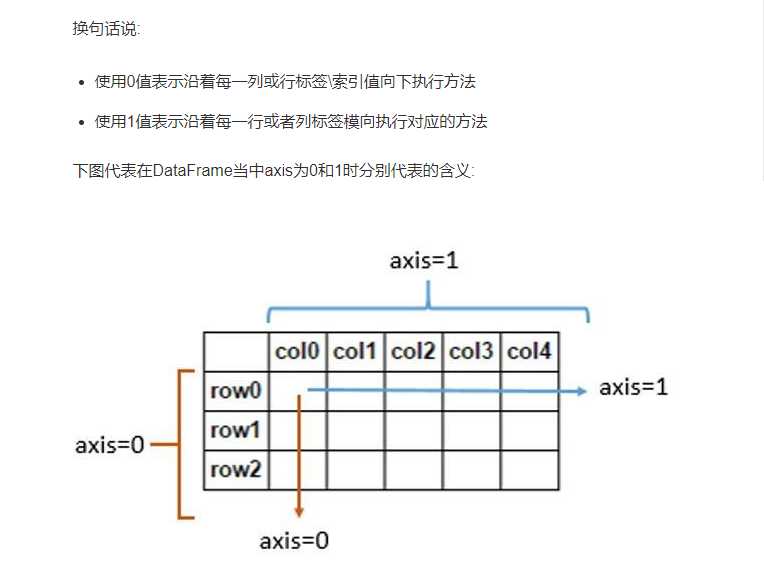
train.drop([‘date‘,‘day_of_week‘],axis=1).groupby(‘brand‘).mean()
#数据的聚合操作,删除‘date‘,‘day_of_week‘,两列,以brand为基础进行聚合求均值。
*******************************************************************