标签:blog http io 使用 java ar 文件 数据 2014
最近,一哥们在他们公司搞大数据时遇到一份比较棘手的xml文件,需要进行巧妙合理的解析,然后将数据进行封装和保存,由于文件比较大,数据比较多,格式稍微复杂一点,所以我帮他解决,刚拿到文件也觉得无从下手,因为文件中的数据格式确实有点复杂。以下给4种常见的xml文件的解析方式的分析对比:
DOM DOM4J JDOM SAX
解析XML文件的几种方式和区别答:
Dom解析 在内存中创建一个DOM树,该结构通常需要加载整个文档然后才能做工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的,树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改能随机访问文件内容,也可以修改原文件内容.
SAX解析 SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点线性解析,不能随机访问,也无法修改原文件
JDOM解析 JDOM的目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快.JDOM仅使用具体类而不使用接口。这在某些方面简化了API,但是也限制了灵活性。第二,API大量使用了Collections类,简化了那些已经熟悉这些类的Java开发者的使用。
DOM4j解析 DOM4J使用接口和抽象基本类方法。DOM4J大量使用了API中的Collections类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然DOM4J付出了更复杂的API的代价,但是它提供了比JDOM大得多的灵活性。
最后相比之下选择了dom4j对其经行解析。
下面是xml文件的一部分:
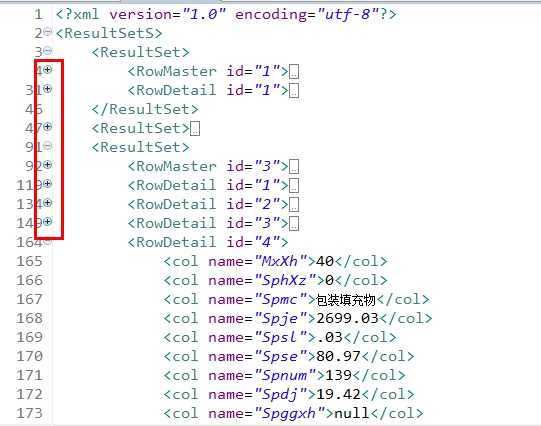

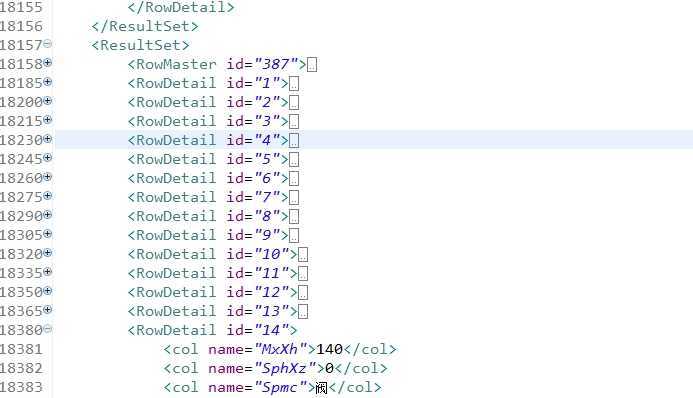
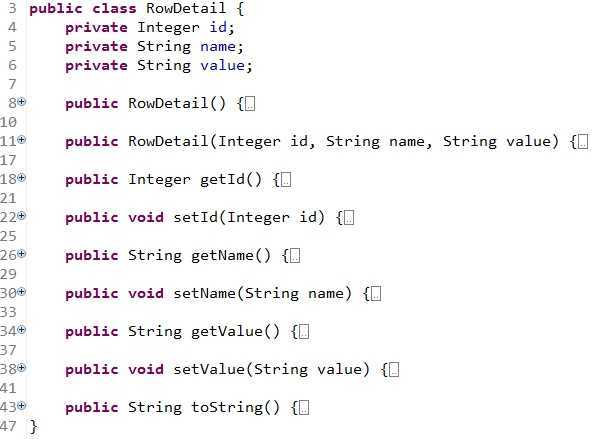
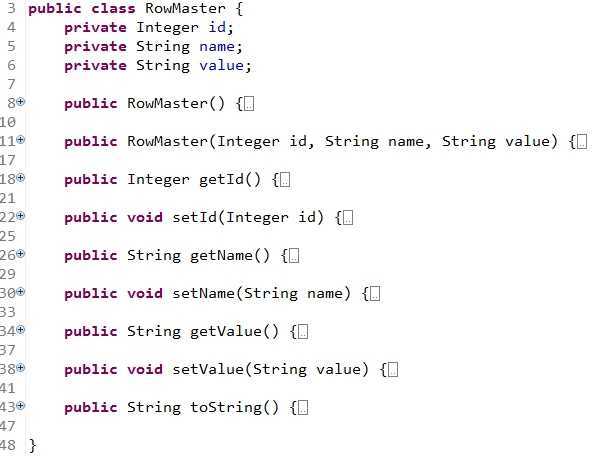
考虑到上面的复杂因素,从面向对象出发,我定义了以下三个实体类对象:
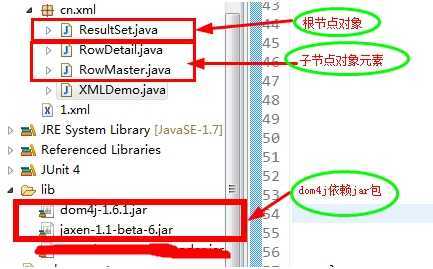
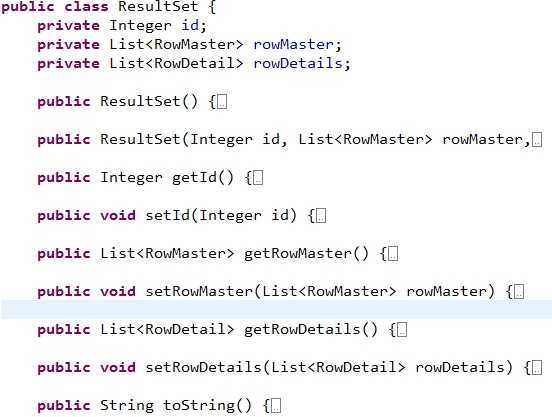
每个对象的定义都比较简单:ResultSet.class,RowDetail.class,RowMaster.class的定义分别如下:
其中用到的最为关键的技术当然是xpath表达式的书写了,详情请参考:http://www.cnblogs.com/fdszlzl/archive/2009/06/02/1494836.html,下面我就直接给出我的解析代码:
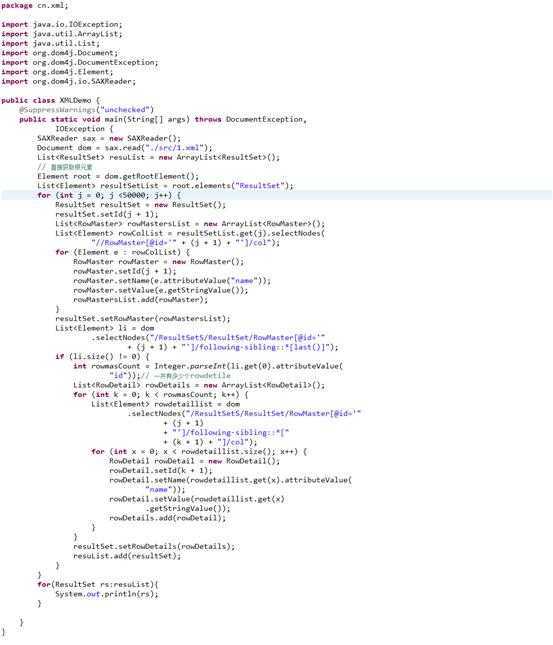
以下是测试查看List<ResultSet> resuList中部分数据的输出:

标签:blog http io 使用 java ar 文件 数据 2014
原文地址:http://www.cnblogs.com/ljhoracle/p/3980999.html