Description
问题的描述以及样例在这里:1458 Common Subsequence
Sample
INPUT:
abcfbc abfcab
programming contest
abcd mnp
OUTPUT: 4 2 0
思路
首先,我们可以想到用暴力法解决,一个序列的子集有 2n 个,两个子集相互比较找出相同且元素最多的子集即可。但是算法的运行时间是指数阶,肯定会TLE 的。
可以换个角度思考,从两个序列的末尾开始比较,总结出求LCS的递归式。设序列 X、Y 分别有它们的前缀串,Xm = <x1, x2, .., xm> 、Yn = <y1, y2, .., yn> ,而序列 Z = <z1, z2, .., zk> 是 X、Y 的任意 LCS。有:
1.如果 xm = yn ,则 zk = xm = ym ,且 zk-1 是xm-1、yn-1 的一个 LCS
2.如果 xm != yn,那么 zk != xm 意味着 zk 是 xm-1 、yn 的一个CLS
3.如果 xm != yn,那么 zk != yn 意味着 zk 是 xm 、yn-1 的一个CLS
举个例子, <a, b, c> 与 <a, b>,比较两序列末尾元素 c、b,发现不匹配,那么就认为它们的 LCS是 <a, b> 与 <a, b> 的LCS,或者是 <a, b, c> 与 <a> 的 LCS,至于是哪个取决于后两者 LCS 哪个大。如果末尾元素匹配了,说明找到了 LCS中的一个元素,则让LCS+1 ,继续寻找 <a, b> 、<a> 的LCS...
如果我们用 c[i][j] 代替zk 表示LCS的长度,i 表示序列X的长度,j 表示序列Y的长度,有如下递归式:
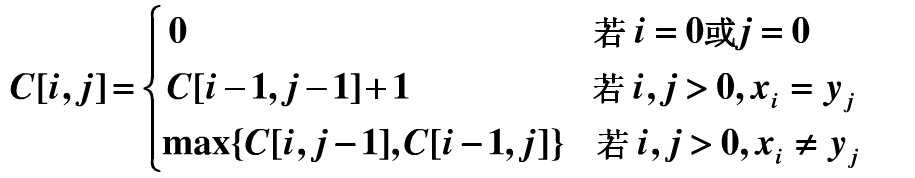
写出递归的程序,但是发现其实很多子问题是重复求解的,比如 i = 6, j = 5,C[5, 5] 就被重复求解了。像这种的树型递归,我们可以采用记忆化搜索的策略解决,通俗的将就是再写一个备忘录,把求过的解都记录在里面,下一次问题重复时直接取出其中的解即可。
这种算法的时间复杂度和互相独立的子问题个数有关,假设输入的规模是 m、n,那么相互独立的子问题有多少个呢?
m·n 个,可以这么想: c[m][n] 是一个,c[m-1][n] 又是一个,c[m][n-1] 又是一个...
所以,记忆化搜索算法的时间复杂度是O(mn)
#include<iostream> #include<string> #include<algorithm> #include<cstring> using namespace std; const int MAXSIZE = 1000; int c[MAXSIZE][MAXSIZE]; int getLCS (const string& x, const string& y,int i, int j) { //传入的是长度 if (i == 0 || j == 0) { //长度为 0 时,表示序列为空,此时LCS = 0 return 0; } if (c[i][j] >= 0) { return c[i][j]; } if (x[i-1] == y[j-1]) { //用于比较的是下标,下标= 长度 - 1 return c[i][j] = getLCS(x, y, i-1, j-1) + 1; } else { return c[i][j] = std::max(getLCS(x, y, i-1, j), getLCS(x, y, i, j-1)); } } int main(void) { string x,y; while (cin >> x >> y ) { memset (c, -1, sizeof(c)); //LCS可能是0,所以应初始化为-1 int ans = getLCS(x, y, x.size(), y.size()); cout << ans << endl; } return 0; }
其实上面的算法就是 DP 的一种,因为它满足 DP 的三个特点:
1.将原问题分解成几个子问题
2.所有问题只需要解决一次
3.存储子问题的解
但是这种自顶向下的办法,存储的空间不密集,会浪费很多空间。