<Spark快速大数据分析>主要使用java, scala和python进行讲解,因博主暂未对java和scala展开了解,所以后续总结只通过python进行展示。
Part 1 Spark简介
Spark的定位:是一个用来实现快速而通用的集群计算平台。
Spark与Hadoop的联系:Spark扩展了mapreduce计算模型,且支持更多的计算模式,包括交互式查询和流处理。
Spark的主要特点:能够在内存中进行计算,因而更快。即便是在磁盘上进行复杂的计算,Spark依然比mapreduce更高效。
Spark主要包含了如下图所示的组件:
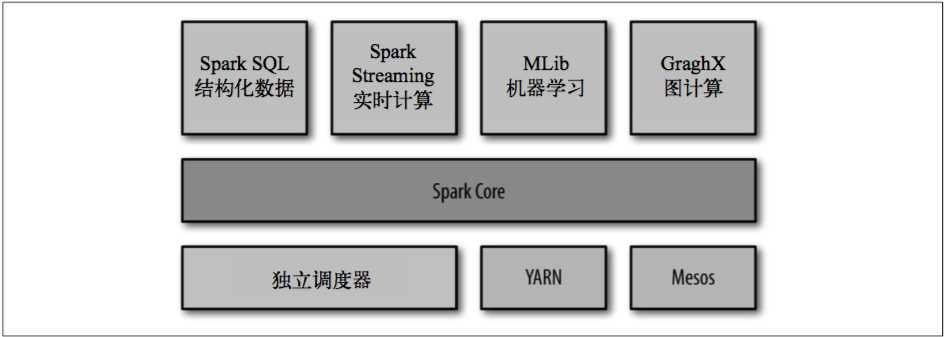
1.Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复与存储系统交互等模块,还包含了对弹性分布式数据集(Resilient Distributed Dataset)的API定义。
2.Spark SQL:是Spark操作结构化数据的程序包,通过Spark SQL可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
3.Spark Streaming:是Spark提供的对实时数据进行流式计算的组件,如生产环境中的网页服务器日志。
4.MLlib:提供机器学习功能的程序库。
5.GraphX:操作图的程序库,可以进行并行的图计算。
6.集群管理器:为了实现在多个计算节点上高效得伸缩计算,Spark支持在各种集群管理器上运行,包括Hadoop YARN、Apache Mesos以及自带的简易调度器,独立调度器,第七章部分会详细探讨管理器的差异以及如何选择合适的集群管理器。
Part 2 核心概念与基本操作
弹性分布式数据集(Resilient Distributed Dataset, 简称RDD):RDD的核心特性是分布式与不可变。
Spark中对数据的所有操作不外乎:
-
- 创建RDD
- 转化已有RDD,即转化操作(transformation):由一个RDD生成一个新的RDD
- 调用RDD操作进行求值,即行动操作(action):会对一个RDD计算出一个结果
Spark会自动将RDD中的数据分发到集群上,并将操作并行化执行。
惰性计算的特性:Spark会惰性计算RDD,意思是只有在一个RDD第一次执行行动操作时,才会真正计算
默认情况下,Spark的RDD会在每次对他们进行行动操作时重新计算,如果重用同一个RDD,可以使用RDD.persist()让Spark把这个RDD缓存下来。举例来说,有一个原始RDD1,由RDD1生成一个RDD2,再由RDD2生成了RDD3,这时如果需要用RDD3进行两个行动操作,默认情况下,系统两次都会从RDD1开始重新计算RDD3,再进行行动操作。如果在RDD3生成后,使用RDD3.persist(),则两次行动操作就会忽略RDD1到RDD3的计算过程,从而省略了1次RDD3的生成过程。类似于闯关游戏中存储进度,下次从存储位置继续玩起的动作。
每一个Spark应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作,驱动器程序通过一个SparkContext对象来访问Spark,使用python shell启动时会自动创建一个SparkContext对象,默认变量名为sc。
创建RDD的方式:
1 #1.通过已有集合生成,用于原型开发和测试 2 lines = sc.parallelize(["pandas", "i love pandas"])
1 #2.从外部存储中读取数据 2 lines = sc.textFile("/path/to/README.md")
转化操作:
#filter操作筛选出RDD1中满足条件的元素构成新的RDD,以下意为选出大于5的元素构成新RDD newRDD = oldRDD.filter(lambda x: x > 5)
#map操作对RDD1中的每个元素进行函数操作后,将结果构成新的RDD,以下意为对RDD中的每个元素进行平方构成新RDD newRDD = oldRDD.map(lambda x: x ** 2)
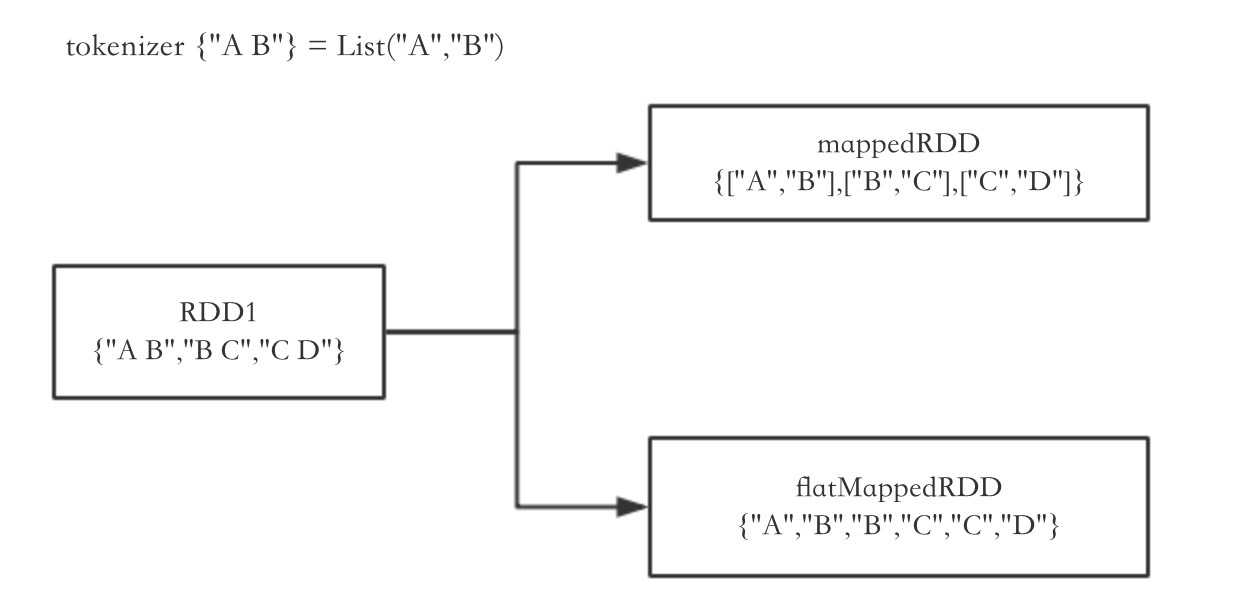
1 #flatMap操作和map操作类似,但是如果操作后的结果为一个列表,则取出列表中的元素构成新RDD,而非将列表构成新RDD 2 newRDD = oldRDD.flatMap(lambda x: x.split(" "))
其中map()和flatMap()操作的区别如下图所示: