s="你好" s_to_utf8=s.encode("utf8","ignore") print(s_to_utf8) print(type(s_to_utf8)) utf8_to_unicode=s_to_utf8.decode("utf8","ignore") print(utf8_to_unicode) print(type(utf8_to_unicode))
unicode_to_gbk=s.encode("gbk") print(unicode_to_gbk) print(type(unicode_to_gbk)) |
最近几次项目都被Python的编码折磨的要死,今天好好的编码的知识总结一下:
先说python2
py2里默认编码是ascii
文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流, 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了。在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"你好",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
再说python3
py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 但py3里,在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,显示在程序中的不是010101这样的2进制, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,能看出哪个字符对应哪段2进制么。
这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b‘\xe4\xbd\xa0\xe5\xa5\xbd‘ bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
这张图展示了字符串编码转换的过程
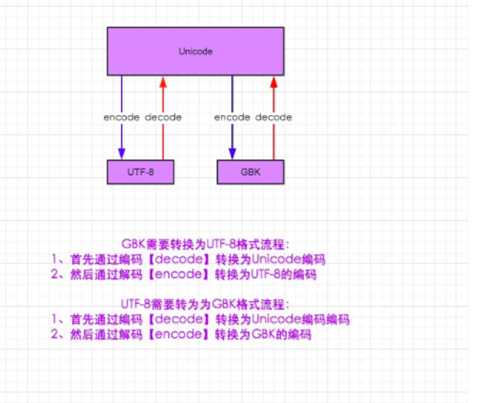
把Python3 默认的unicode 转入utf-8 格式,程序不光是解码到UTF8,还自动转成bytes类型。
s="你好"
s_to_utf8=s.encode("utf8","ignore")
print(s_to_utf8)
print(type(s_to_utf8))
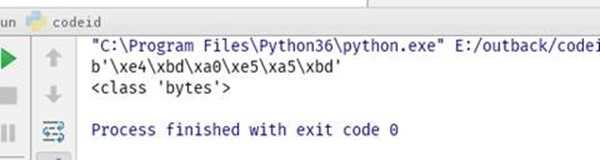
把utf8 转为unicode,python3中unicode就是str类型
utf8_to_unicode=s_to_utf8.decode("utf8","ignore")
print(utf8_to_unicode)
print(type(utf8_to_unicode))

把unicode 转为gbk
unicode_to_gbk=s.encode("gbk")
print(unicode_to_gbk)
print(type(unicode_to_gbk))
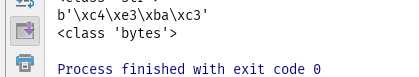
可以看出,gbk格式在Python3中也是str类型
所以字符串转码必须经过unicode,不能用utf8直接到gbk,这就是编码和解码。
其他
msg = "我爱北京天安门" #默认就是unicode,python 文件是utf-8格式,但是所定义的变量字符串是unicode格式
#msg_gb2312 = msg.decode("utf-8").encode("gb2312")
msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔
gb2312_to_unicode = msg_gb2312.decode("gb2312")
gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8")
对于文件 可以直接使用codec
Python
1 2 3 4 5 | # 使用codecs直接开unicode通道 file = codecs.open("test", "r", "utf-8") for i in file: print type(i) # i的类型是unicode的 |
关于requests库
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。其中的Request对象在访问服务器后会返回一个Response对象,这个对象将返回的Http响应字节码保存到content属性中。但是如果你访问另一个属性text时,会返回一个unicode对象,乱码问题就会常常发成在这里。
因为Response对象会通过另一个属性encoding来将字节码编码成unicode,而这个encoding属性居然是responses自己猜出来的。
官方文档:
text
Content of the response, in unicode.
If Response.encoding is None, encoding will be guessed using chardet.
The encoding of the response content is determined based solely on HTTP headers, following RFC 2616 to the letter. If you can take advantage of non-HTTP knowledge to make a better guess at the encoding, you should set r.encoding appropriately before accessing this property.
所以要么你直接使用content(字节码),要么记得把encoding设置正确,比如我获取了一段gbk编码的网页,就需要以下方法才能得到正确的unicode。
Python
1 2 3 4 5 6 | import requests url = "http://xxx.xxx.xxx" response = requests.get(url) response.encoding = ‘gbk‘
print response.text
|
详细:http://www.cnblogs.com/yuanchenqi/articles/5956943.html