本文将介绍主成分分析(Principal Component Analysis,PCA)原理,并且它如何在分类问题中发挥降维的作用。译自
简介
本文将介绍主成分分析(Principal Component Analysis,PCA)原理,并且它如何在分类问题中发挥降维的作用。
在前面我们讲到过维度灾难,分类器容易对高维的训练集产生过拟合。那么,哪些特征是更好的呢,而哪些又该从高维中除去呢
如果所有的特征向量间相互独立,我们可以很容易的去除区分度很小的特征向量,区分度小的向量可通过特征选择相关方法识别。然而,在实际中,很多向量彼此依赖或依赖潜在的未知变量。一个单一的特征可以用一个值来代表很多信息的集合。移除这样的特征将移除比所需要的更多的信息。在下一节,我们将介绍作为特征提取的解决此问题的PCA方法,并从两个不同的角度介绍它的内在工作原理。
PCA:一种去相关方法
屡见不鲜的是,特征都是相关的。例如,我们想要使用图像中每个像素的红色,绿色和蓝色分量来进行图像分类(例如侦测猫和狗),对红光最敏感的图像传感器也捕获一些蓝光和绿光。 类似地,对蓝光和绿光最敏感的传感器也对红光表现出一定程度的敏感度。 结果,像素的R,G,B分量在统计上是相关的。因此,简单地从特征向量中消除R分量,也隐含地除去关于G和B信道的信息。换句话说,在消除特征之前,我们想要转换完整的特征空间,从而得到底层的不相关分量。
下图是一个二维特征空间的例子:
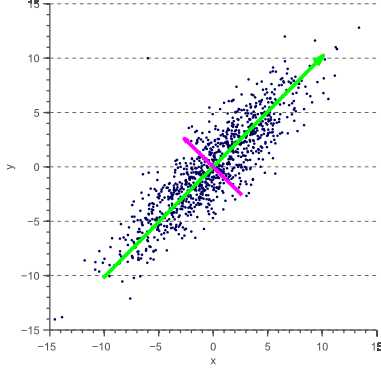 图一
图一
图中的特征x和y明显是相关的。事实上,它们的协方差矩阵是:

在前面的文章中,我们讨论了协方差矩阵的几何解释。 我们看到,协方差矩阵可以分解为在白色的不相关数据上一系列旋转和缩放操作,其中旋转矩阵由该协方差矩阵的特征向量定义。 因此,直观地看到,通过旋转每个数据点,上图所示的数据D可以被解相关,使得特征向量V成为新的参考轴:
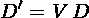
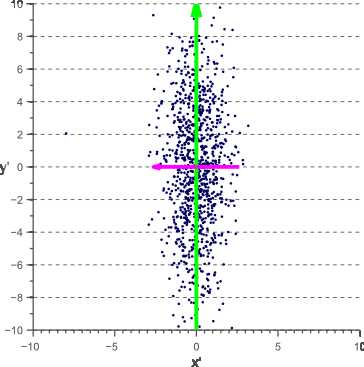 图2
图2
经旋转缩放的数据的协方差矩阵现在是对角线的,这意味着新的轴是不相关的:
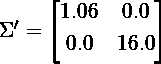
事实上,上上图中的原始数据是通过两个1维高斯特征向量x1 ~ N(0,1),x2 ~ N(0,1)的线性组合生成的:
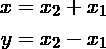
因为特征x和y是x1和x2的一些未知的潜在成分的线性组合,直接去除x或y的任意一个,都将丢失来自x1和x2的一些信息。而将数据协方差的特征向量进行旋转,会使我们直接恢复这两个独立的成分x1和x2(达到比例因子)。这可以被看作如下:原始数据的协方差矩阵的特征向量是(每列代表一个特征向量):
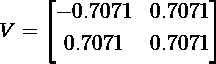
首先要注意的是,在这种情况下,V是一个旋转矩阵,对应于45度旋转(cos(45)= 0.7071),从图1中确实可以看出。其次,将V视为在新的坐标系中线性变换矩阵结果 ,每个新的特征x‘和y‘被表示为原始特征x和y的线性组合:
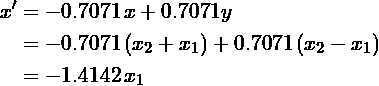
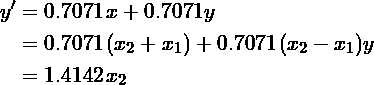
换句话说,特征空间的去相关对应于数据的未知不相关组件x_1和y_1的恢复(如果变换矩阵不是正交的,则恢复到未知缩放因子)。 一旦这些组件被恢复,通过简单地消除x_1或x_2就很容易降低特征空间的维度。
在上面的例子中,我们从一个二维问题开始。 如果我们想要降低维数,问题依然是消除x_1(从而x‘)还是y_1(从而y‘)。 尽管这种选择可能取决于许多因素,例如在分类问题的情况下数据的可分性,但PCA只是假设最有意思的特征是具有最大差异或差异的特征。 这个假设是基于信息理论的观点,因为具有最大方差的维度对应于具有最大熵的维度,因此编码最多的信息。 最小的特征向量通常会简单地表示噪声分量,而最大的特征向量通常对应于定义数据的主要分量。
然后简单地通过将数据投影到其协方差矩阵的最大特征向量上来实现通过PCA的降维。 对于上面的例子,所得到的一维特征空间如图3所示:
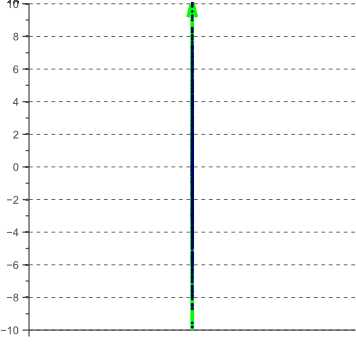 图3
图3
显然,上面的例子很容易推广到更高维的特征空间。 例如,在三维情况下,我们可以将数据投影到由两个最大特征向量所定义的平面上以获得二维特征空间,或者我们可以将其投影到最大特征向量上以获得一维特征空间。 如图4所示:
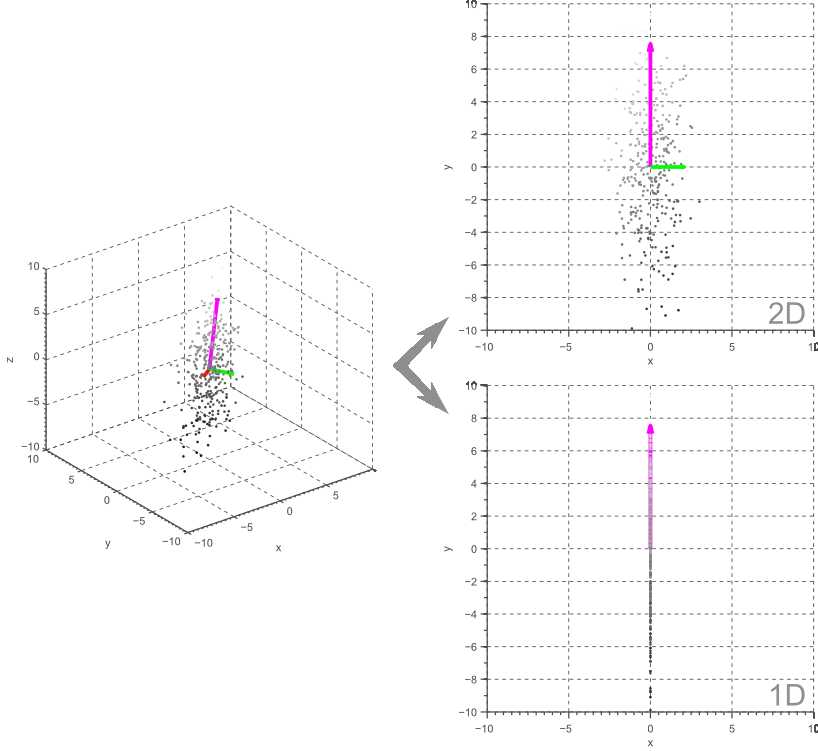 图4
图4
一般来说,PCA允许我们获得原始N维数据的线性M维子空间,其中M <= N。此外,如果未知的不相关分量是高斯分布的,则PCA实际上作为独立分量分析,因为不相关的高斯变量在统计上是独立的。 但是,如果底层组件不是正态分布的,PCA仅仅产生不相关的去相关变量。 在这种情况下,非线性降维算法可能是更好的选择。
PCA:一种正交回归方法
在上面的讨论中,我们从获得独立分量(或者如果数据不是正态分布的话至少是不相关分量)开始,以减小特征空间的维数。我们发现这些所谓的“主成分”是通过我们的数据的协方差矩阵的特征分解得到的。然后通过将数据投影到最大的特征向量来降低维数。
现在让我们暂时忘记我们希望找到不相关的组件。相反,我们现在尝试通过找到原始特征空间的线性子空间来减少维数,在这个子空间上我们可以投影数据,从而使投影误差最小化。在2D情况下,这意味着我们试图找到一个向量,以便将数据投影到该向量上,这相当于投影误差低于将数据投影到任何其他可能向量时所获得的投影误差。问题是如何找到这个最佳的向量。
考虑图5所示的例子。显示三个不同的投影向量,以及所得到的一维数据。在下面的段落中,我们将讨论如何确定哪个投影向量最小化了投影误差。在寻找一个最小化投影误差的向量之前,我们必须定义这个误差函数。
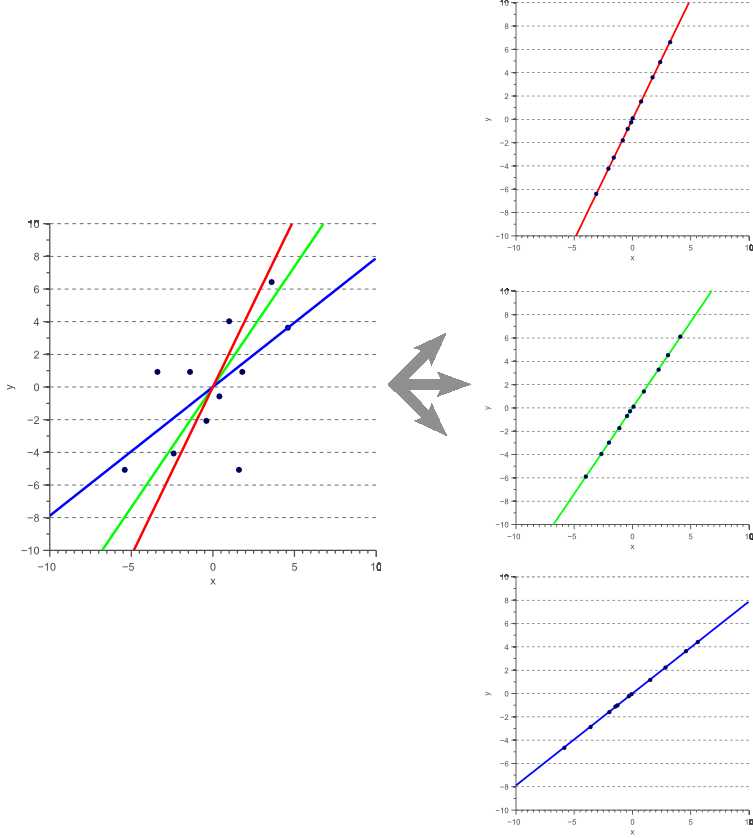 图5
图5
一个众所周知的方法来拟合2D数据是最小二乘回归。 给定自变量x和因变量y,最小二乘回归函数对应于f(x)= ax + b,使得残差平方和的总和为:sum_{i=0}^N (f(x_i) - y_i)^2被最小化。 换句话说,如果将x看作自变量,那么得到的回归函数f(x)是一个线性函数,可以预测因变量y,使得平方误差最小。 所得到的模型f(x)由图5中的蓝线表示,并且最小化的误差如图6所示。
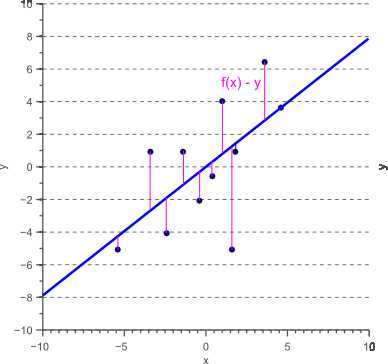 图6
图6
然而,在特征提取的背景下,人们可能会想知道为什么我们将特征x定义为独立变量,特征y是因变量。 事实上,我们可以很容易地将y定义为自变量,并且找到预测因变量x的线性函数f(y),使得 sum_ {i = 0} ^ N(f(y_i)-x_i)^ 2是最小化。 这对应于水平投影误差的最小化并导致不同的线性模型,如图7所示:
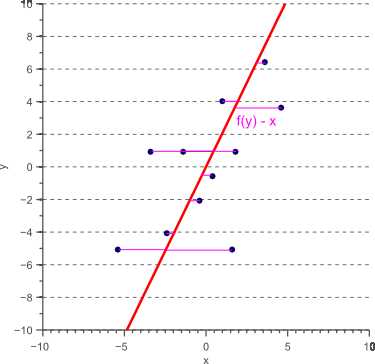 图7
图7
显然,独立变量和因变量的选择改变了所得到的模型,使得普通最小二乘回归成为非对称回归。 其原因是最小二乘回归假设自变量是无噪声的,而因变量则被认为是有噪声的。 然而,在分类的情况下,所有的特征通常是噪音的观察,使得x或y都不应该被视为独立的。 事实上,我们想获得一个模型f(x,y),同时最小化水平和垂直投影误差。 这对应于找到一个模型,使正交投影误差最小化,如图8所示。
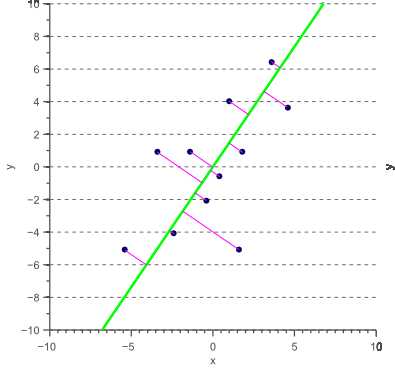 图8
图8
由此产生的回归被称为总体最小二乘回归或正交回归,并假设这两个变量都是不完美的观察。 现在有一个有趣的现象是所获得的表示使正交投影误差最小化的投影方向的矢量对应于数据的最大主成分:
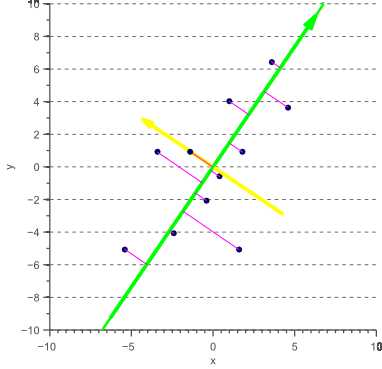 图9
图9
换句话说,如果我们想通过将原始数据投影到一个向量上来减少维数,使得投影误差在所有方向上的平方最小化,我们可以简单地将数据投影到最大的特征向量上。 这正是我们在上一节中称为主成分分析的地方,我们在这里展示了这样的投影也使特征空间去相关。
一个实际的PCA应用程序:特征脸
尽管为了可视化的目的,上述示例仅限于二维或三维,但是与训练样本的数量相比,特征的数量不可忽略时,降维通常变得重要。作为示例,假设我们想要基于标记的面部图像的训练数据集来执行面部识别,即确定图像中描绘的人的身份。一种方法可能是将图像的每个像素的亮度视为特征。如果输入图像的大小为32×32像素,则这意味着特征矢量包含1024个特征值。然后可以通过计算这个1024维矢量与我们训练数据集中的人的特征矢量之间的欧几里德距离来对新的人脸图像进行分类。最小的距离告诉我们我们正在看哪个人。
然而,如果我们只有几百个训练样本,则在1024维空间中操作会变得有问题。此外,欧几里德距离在高维空间中表现得很奇怪,正如前面的文章中所讨论的那样。因此,通过计算1024维特征向量的协方差矩阵的特征向量,然后将每个特征向量投影到最大的特征向量上,可以使用PCA来降低特征空间的维数。
由于二维数据的特征向量是二维的,三维数据的特征向量是三维的,所以1024维数据的特征向量是1024维的。换句话说,为了可视化的目的,我们可以将每个1024维的特征向量重塑为32×32的图像。图10显示了通过剑桥人脸数据集的特征分解得到的前四个特征向量:
 图10
图10
现在可以将每个1024维特征向量(以及每个面)投影到N个最大的特征向量上,并且可以表示为这些特征面的线性组合。这些线性组合的权重决定了人的身份。由于最大的特征向量表示数据中最大的方差,这些特征向量描述了信息最丰富的图像区域(眼睛,噪音,嘴巴等)。通过仅考虑前N个(例如N = 70)特征向量,特征空间的维度大大降低。
剩下的问题是现在应该使用多少个本征面,或者在一般情况下;应该保留多少个特征向量。去除太多的特征向量可能会从特征空间中删除重要的信息,而消除特征向量的太少则会给我们带来维度的灾难。遗憾的是,这个问题没有直接的答案。尽管可以使用交叉验证技术来获得对这个超参数的估计,但是选择最优维数仍然是一个问题,这个问题主要是在经验(一个学术术语,这意味着不仅仅是“试错”)方式。请注意,在消除特征向量的同时检查保留原始数据的方差有多少(作为百分比)通常是有用的。这是通过将保留的特征值之和除以所有特征值之和来完成的。
PCA实现的具体步骤
基于前面的部分,我们现在可以列出用于应用PCA进行特征提取的简单配方:
1)中心化数据
在前面的文章中,我们表明,协方差矩阵可以写成一系列线性运算(缩放和旋转)。特征分解提取这些变换矩阵:特征向量表示旋转矩阵,而特征值表示比例因子。然而,协方差矩阵并不包含任何有关数据转换的信息。事实上,为了表示转换,需要仿射变换而不是线性变换。
因此,在应用PCA旋转数据以获得不相关的轴之前,需要通过从每个数据点中减去数据的平均值来抵消任何现有的偏移。这简单地对应于使数据居中以使其平均值变为零。
2)标准化数据
协方差矩阵的特征向量指向数据最大方差的方向。但是,方差是一个绝对数字,而不是相对数字。这意味着以厘米(或英寸)为单位测量的数据差异将远大于以米(或英尺)为单位测量的相同数据的差异。考虑一个例子,其中一个特征代表以米为单位的对象的长度,而第二个特征代表以厘米为单位的对象的宽度。如果数据没有被标准化,那么最大的方差以及最大的特征向量将由第一特征隐含地定义。
为了避免PCA的这种与尺度相关的性质,通过将每个特征除以其标准偏差来规范化数据是有用的。如果不同的功能对应不同的指标,这一点尤其重要。
3)计算特征分解
由于数据将被投影到最大的特征向量上以降低维数,因此需要获得特征分解。奇异值分解(Singular Value Decomposition,SVD)是有效计算特征分解最常用的方法之一。
4)投影数据
为了降低维度,数据被简单地投影到最大的特征向量上。设V是列中包含最大特征向量的矩阵,设D是包含不同观测值的原始数据。那么投影数据D‘可以用D‘= V^(T) * D来获得。我们可以直接选择剩余维数,即V的列数,或者我们可以定义消除特征向量时需要保留的原始数据。如果只保留N个特征向量,并且e_1 ... e_N表示相应的特征值,则投影原始d维数据之后剩余的方差量可以被计算为:
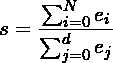
PCA的陷阱
在上面的讨论中,已经有了一些假设。 在第一节中,我们讨论了PCA如何去相关数据。 实际上,我们开始讨论时表达了我们希望恢复所观察到的特征的未知的,潜在的独立组成部分。 然后我们假设我们的数据是正态分布的,这样统计独立性就相当于没有线性相关性。 事实上,PCA允许我们解相关数据,从而在高斯情况下恢复独立分量。 但是,重要的是要注意,去相关只对应于高斯情况下的统计独立性。 考虑通过采样半个周期y = sin(x)获得的数据:
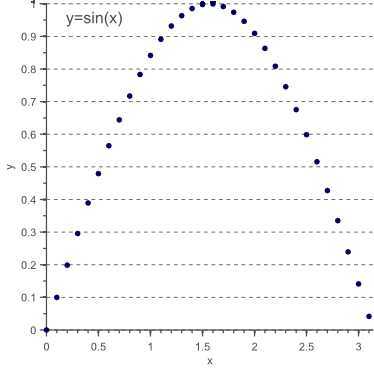 图11
图11
虽然上述数据显然是不相关的(平均来说,当x值上升时,y值增加的幅度与其降低一样多),因此对应于对角线协方差矩阵,但是两个变量之间仍然存在明显的非线性相关性。
一般来说,PCA只是不相关的数据,但不会消除统计依赖性。如果底层的组件被认为是非高斯的,像ICA这样的技术可能会更有趣。另一方面,如果明确存在非线性,则可以使用诸如非线性PCA的降维技术。但是,请记住,这些方法容易过度拟合,因为要根据相同数量的训练数据来估计更多的参数。
本文所做的第二个假设是,最有区别的信息是通过特征空间中最大的方差来捕获的。由于最大变化的方向编码最多的信息,这很可能是真实的。然而,有些情况下,鉴别信息实际上存在于方差最小的方向上,使得PCA可能极大地损害分类性能。作为一个例子,考虑图12的两种情况,其中我们将二维特征空间减少为一维表示:
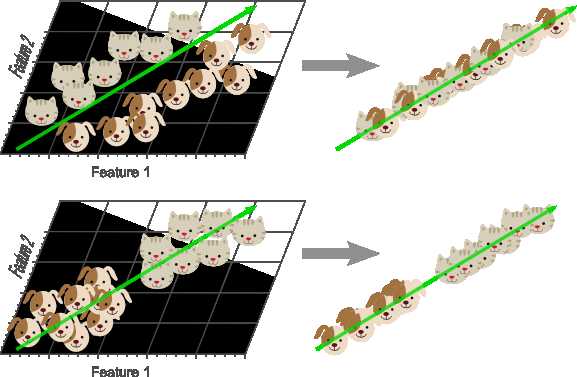 图12
图12
如果最大的判别性信息包含在较小的特征向量中,那么应用PCA可能实际上恶化了维度灾难,因为现在需要更复杂的分类模型(例如非线性分类器)来分类较低维度的问题。 在这种情况下,其他降维方法可能是有意义的,例如线性判别分析(LDA),它试图找到最佳分离两个类别的投影向量。
下面的代码片断显示了如何在Matlab中执行维度约简的主成分分析:Matlab source code
小结
在本文中,我们从两个不同的角度讨论了PCA的特征提取和降维的优点。 第一个观点解释了PCA如何使我们去掉特征空间,而第二个观点则表明PCA实际上对应于正交回归。
此外,我们简要介绍了特征脸是一个众所周知的基于PCA的特征提取的例子,我们介绍了主成分分析的一些最重要的缺点。