标签:路径 51cto 用户 优化 inf 规模 懒加载 重写 shadow

随着公司业务的高速发展,公司服务之间的调用关系愈加复杂,如何理清并跟踪它们之间的调用关系就显的比较关键。线上每一个请求会经过多个业务系统,并产生对各种缓存或者 DB 的访问,但是这些分散的数据对于问题排查,或者流程优化提供的帮助有限。在这样复杂的业务场景下,业务流会经过很多个微服务的处理和传递,我们难免会遇到这些问题:
对于上面那些问题,业内已经有了一些具体实践和解决方案。通过调用链的方式,把一次请求调用过程完整的串联起来,这样就实现了对请求链路的监控。
在业界,目前已知的分布式跟踪系统,比如「Twitter Zipkin 与淘宝鹰眼」,设计思想都是来自 Google Dapper 的论文 「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」
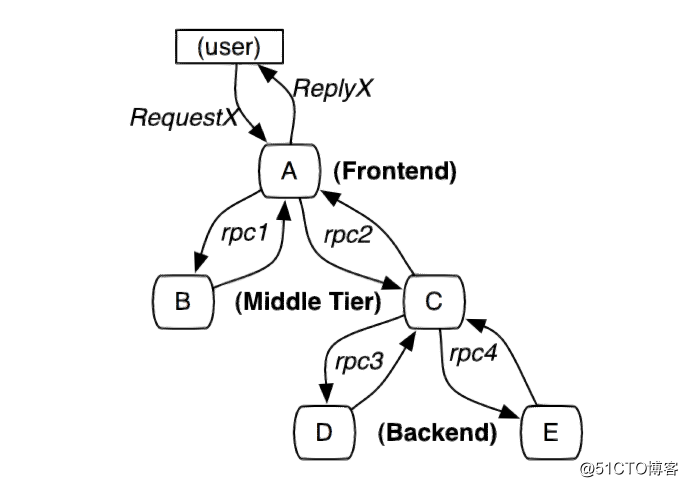
图1:这个路径由用户的X请求发起,穿过一个简单的服务系统。用字母标识的节点代表分布式系统中的不同处理过程。
分布式服务的跟踪系统需要记录在一次特定的请求后系统中完成的所有工作的信息。举个例子,图1展现的是一个和5台服务器相关的一个服务,包括:前端(A),两个中间层(B和C),以及两个后端(D和E)。当一个用户(这个用例的发起人)发起一个请求时,首先到达前端,然后发送两个 RPC 到服务器 B 和 C 。B 会马上做出反应,但是 C 需要和后端的 D 和 E 交互之后再返还给 A ,由 A 来响应最初的请求。对于这样一个请求,简单实用的全链路跟踪的实现,就是为服务器上每一次你发送和接收动作来收集与跟踪
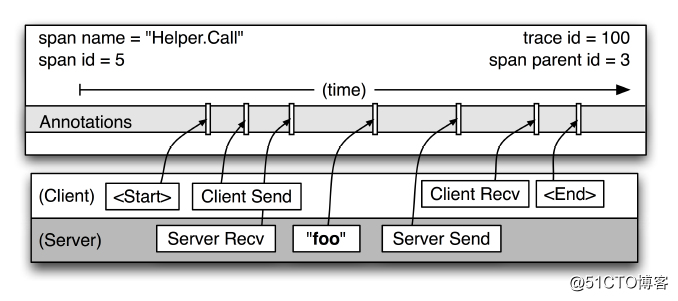
cs - CLIENT_SEND,客户端发起请求
sr - SERVER_RECIEVE,服务端收到请求
ss - SERVER_SEND,服务端处理完成,发送结果给客户端
cr - CLIENT_RECIEVE,客户端收到响应| 公司 | 选项 | 是否开源 | 优缺点 |
|---|---|---|---|
| 淘宝 | EagleEye | 否 | 主要基于内部 HSF 实现,HSF 没有开源,故鹰眼也没有开源 |
| Zipkin | 是 | 基于 Http 实现,支持语言较多,比较适合我们公司业务 | |
| 点评 | CAT | 是 | 自定义改造难度大,代码比较复杂,侵入代码,需要埋点 |
| 京东 | Hydra | 是 | 主要基于 Dubbo 实现,不适合公司 Http 请求为主的场景 |
综上,考虑到公司目前以 Http 请求为主的场景,最终决定采用参考 Zipkin 的实现思路,同时以 OpenTracing 标准来兼容多语言客户端
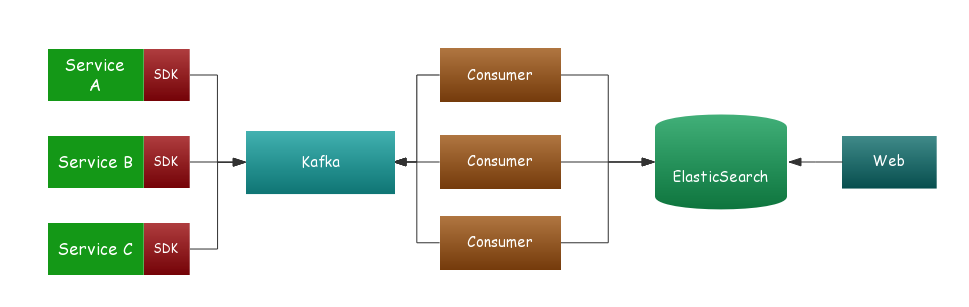
一般全链路跟踪系统主要有四个部分:数据埋点、数据传输、数据存储、查询界面
目前支持的中间件有:
我们在 SDK 与后端服务之间加了一层 Kafka ,这样做既可以实现工程解耦,又可以实现数据的延迟消费,起到削峰填谷的作用。我们不希望因为瞬时 QPS 过高而导致数据丢失,当然为此也付出了一些实效性上的代价。
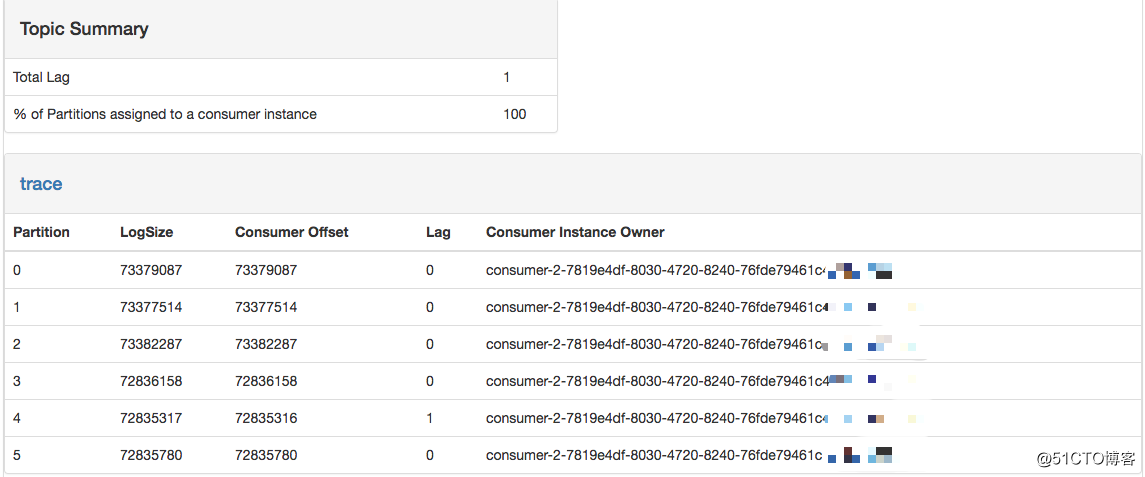
数据存储采用 ElasticSearch ,主要存储 Span 与 Annotation 相关的数据,考虑到数据量的规模,先期只保存最近 1 个月的数据。

通过可视化 Web 界面来查询分布式调用链路,同时还提供根据项目维度分析依赖聚合
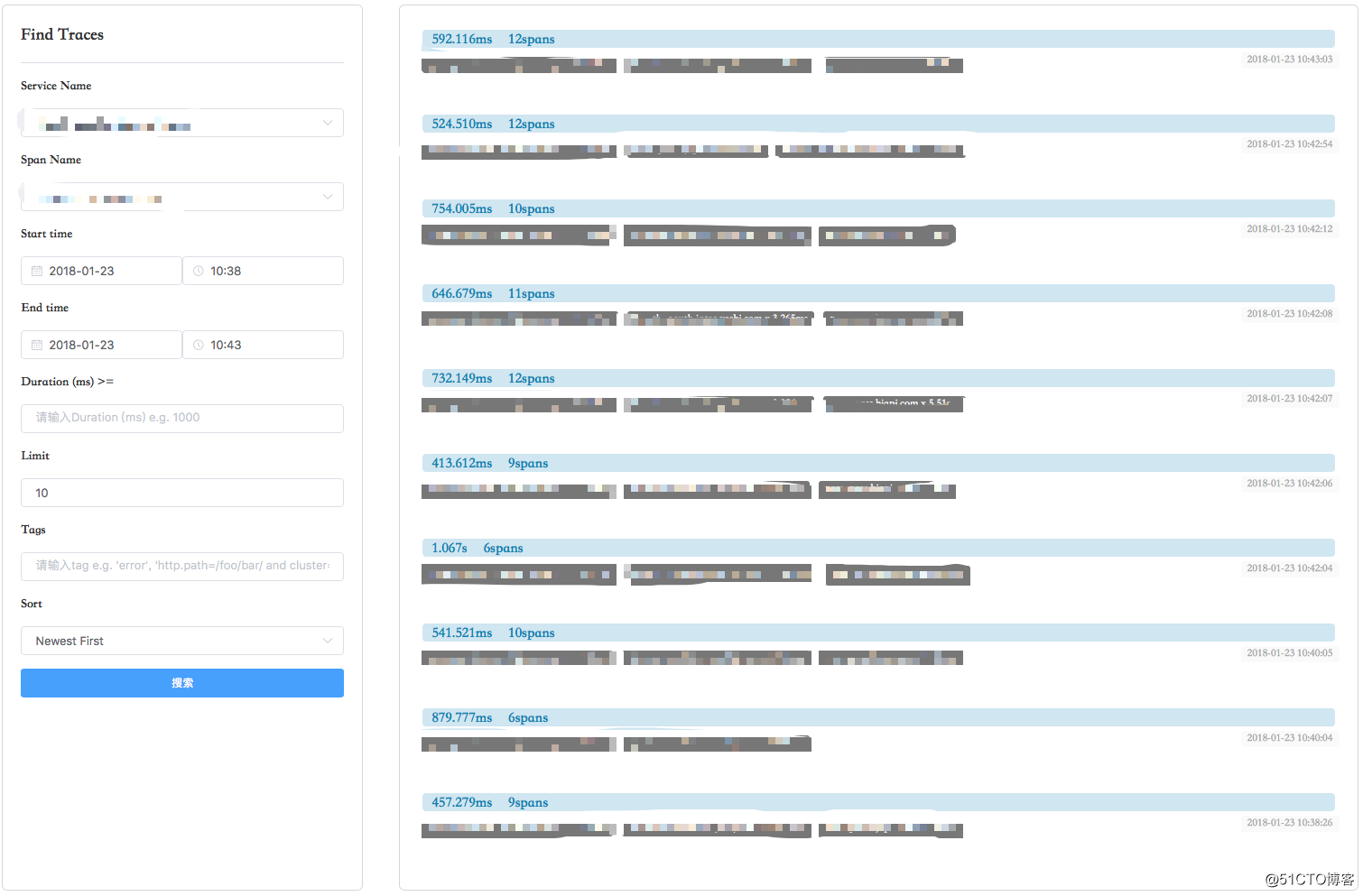
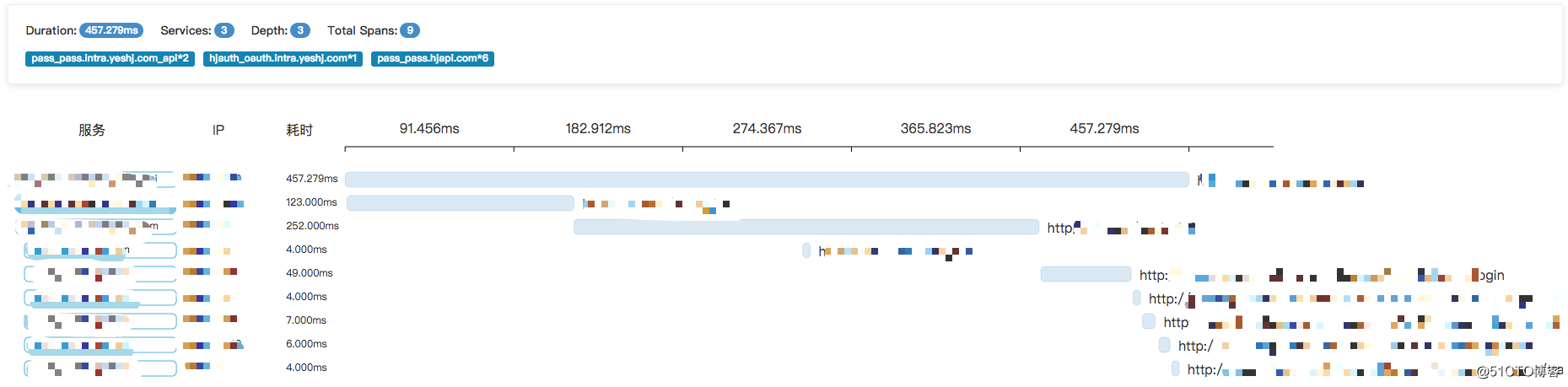
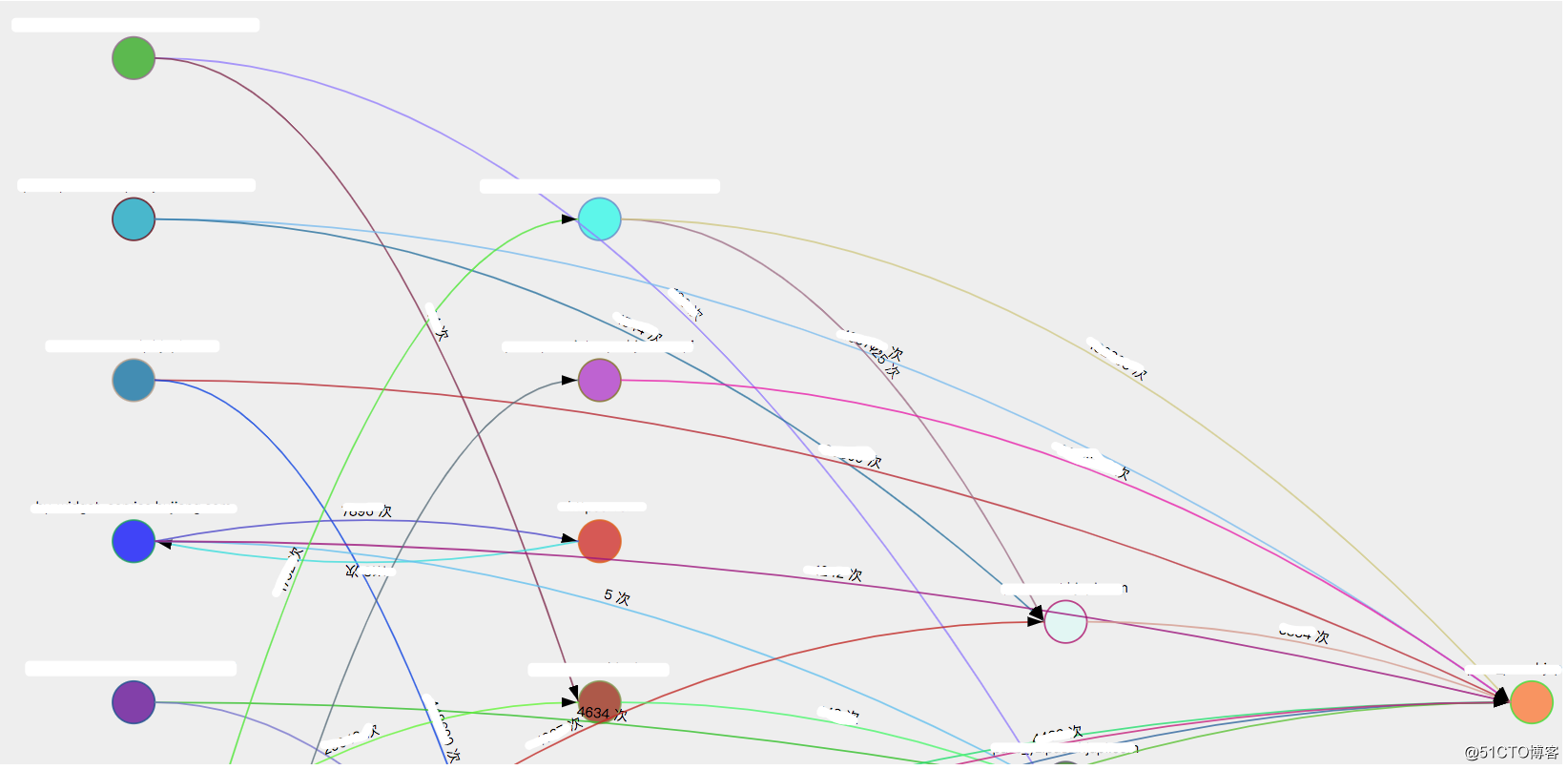
使用 Zipkin 官网 UI 的时候,会偶发性的出现业务加载超时。
原因是 Zipkin 加载页面的时候会一次性加载该项目里面所有的 Span ,当项目使用 Restful 形式的 API 时,就会产生几百万的 Span。最后,我们重写 UI 页面采用懒加载的方式,默认展示最近 10 条 Span,同时支持输入字符来动态查询 Span 的功能。
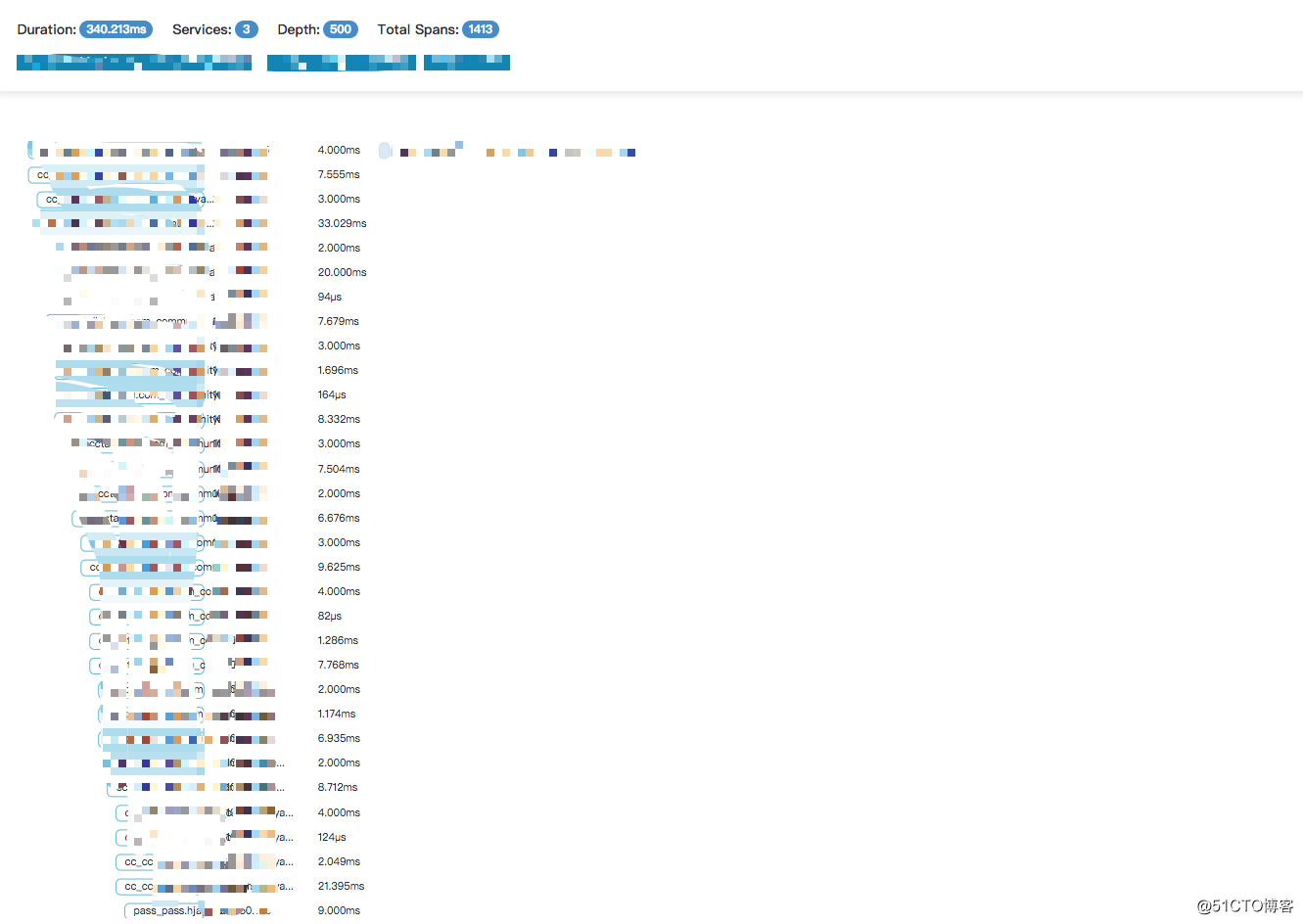
当使用页面查询 Trace 的时候,发现某个链路堆积到上千条 Span
排查下来,业务方使用 HttpClient 中间件发送 Http 请求超时的时候,SDK 并未拦截超时对应的异常,导致事件一直在存储在线程对应的 ThreadLocal 中
全链路跟踪系统关键点:调用链。
每次请求都生成全局唯一的 TraceID,通过该 ID 将不同的系统串联起来。实现调用链跟踪,路径分析,帮助业务人员快速定位性能瓶颈,排查故障原因。
标签:路径 51cto 用户 优化 inf 规模 懒加载 重写 shadow
原文地址:http://blog.51cto.com/13527416/2067846