简介
一转眼在去哪儿网玩乐事业部工作快4年了,经历了数据团队的组建和发展,回顾一下整体过程,经历了很多坎坷,普通而不简单。下面是大事记
- 2014年(系统搭建):开发报表平台、接入HADOOP、搭建调度系统
- 2015年(数据集市):搭建数据集市、开发数据同步工具
- 2016年(数据应用):系统定价、多维分析
- 2017年(数据重构):重构底层、数据分级、元数据、数据质量
- 2018年(数据化运营):实时系统、用户画像、模型搭建
2014年(系统搭建)
2014年组建数据团队,整体结构如下:
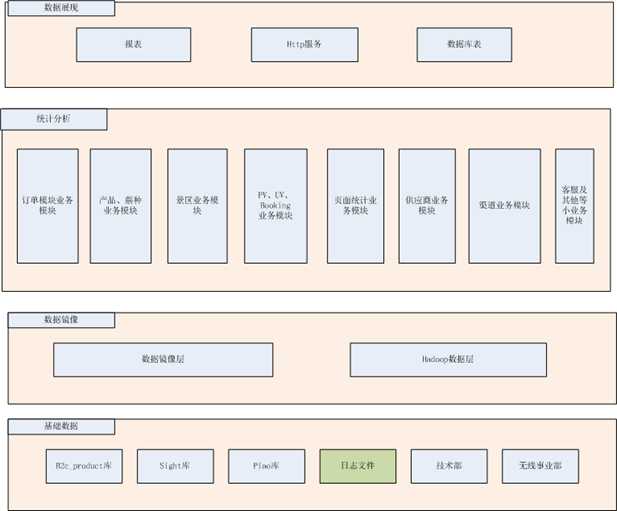
当时迅速区理解了业务,并区分出来了核心主题,并且主要工作是产出数据,也就是数据报表。 2014年大数据还是比较新鲜的,部门非常重视,配置了NB的产品和技术,老大在很多重要场合宣称部门要转向数据化运营,产品和运营的KPI由数据产考核,并且为此搭建了CRM系统。
按理说数据团队应该策马奔腾迈向小康社会了。但是蜜月期很短,几个月后就逐步出现了问题。最主要的表现是BOSS、产品、运营看见的数据不准确、不一致、不及时....
2015年(数据集市)
蜜月期过了之后,BOSS经常在重要场合表达对数据团队的失望,我记得非常清楚的话是:“你们知道我为了TMD数据团队背后做了多少努力吗?我咨询了XXX个公司,XXX说咱们的数据,TMD1个月就能搭起来”。或者是:“你们到底要做什么,难道就是一个提数的吗?好,你们就做一个提数的工具吧!”。当时的情况:http://www.cnblogs.com/liqiu/p/4869748.html
重新审视了数据的问题之后,决心从底层做起,搭建数据集市(数据宽表)。效果确实很好,缓解了数据一致性、数据及时性、数据准确性的问题。大家对数据团队的期望基本稳定了,系统也随之稳定了下来。
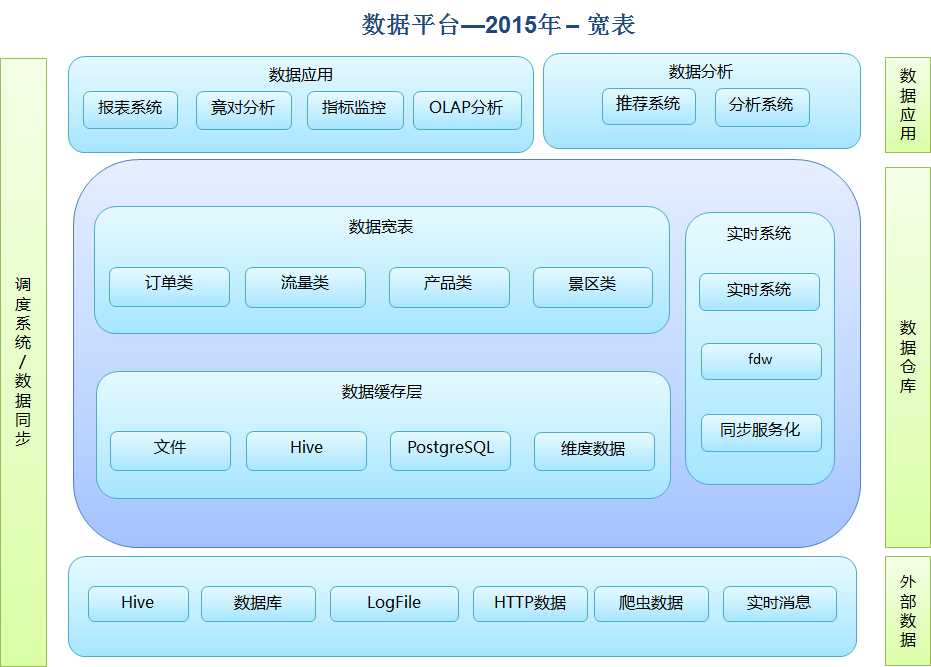
2016年(数据应用)
数据稳定之后,希望做一些有意思的东西出来,首先就是解决数据同步的问题,业界有sqoop、dataX,但是对于PG支持的不好,特别是PG的扩展属性,比如hstore支持的有限,所以决定自己开发。
1 数据同步
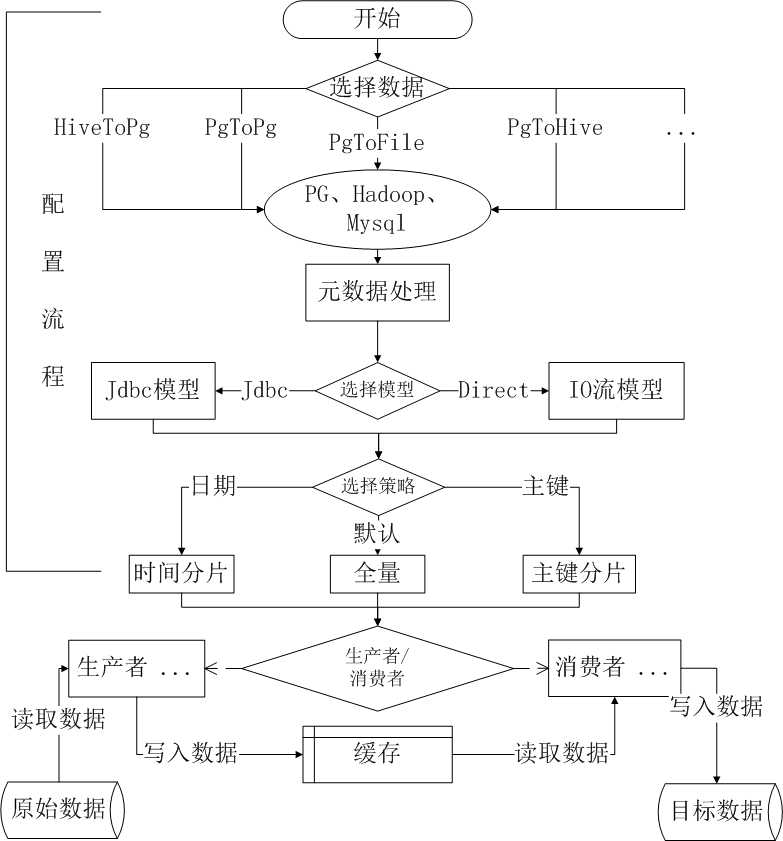
项目名称是synchronous,它的设计借鉴了DATAX的插件设计理念,DATAX的文档:https://github.com/alibaba/DataX。synchronous和DATAX的技术上区别是:代码小巧,精炼,易懂易读,有兴趣的同学可以快速深入,读懂了synchronous有助于快速理解DATAX。
下面偏重流程方面介绍一下synchronous:
- 选择同步的双方:插件的好处就是扩展性强,可随时增加数据源
- CHECK元数据:至少两边的数据字段要一致
- 选择数据分片:数据量可能很大,需要分片处理
- 同步数据:采用多线程的生产者消费者模型
详细设计过程可见:http://www.cnblogs.com/liqiu/p/4882821.html ; 代码在:https://github.com/autumn-star/synchronous。
2 系统定价
去哪儿以前是taobao的模式,只提供平台和流量。后来有了自营产品,随着业务的发展,自营产品越来越多,定价就是问题了。按照一般的策略是保证利润率的情况下,比竞对低一点。
3 自动化接口
经常需要给外部提供数据,如果每个都写dao、dto、service和controller,开发和维护成本特别高,所以研发了一个系统,配置SQL直接吐出数据接口数据,比如一个接口需要统计一段时间每个产品的订单量和份数,那么数据表里面保存这样一个记录,主键id是1:
SELECT product_id, --产品id SUM(quantity) as quantity, --份数 COUNT(1) as order_num --订单量 FROM table1 WHERE stat_date between @{start_date} and @{end_date} GROUP BY product_id
访问的时候,带着参数就可以,比如:url?id=1&start_date=2017-01-01&end_date=2017-10-01。这样就吐出了时间在2017-01-01~2017-10-01之间的数据。
4 多维
为了将开发从无休止的SQL需求中解救出来,搭建了多维系统,就是数据立方体。当时用的是saiku+kylin,可是saiku需要持久的前端投入,kylin对少量维度支持的还好,维度达到几十个之后就出现问题了,所以这个项目就暂定了。但是底层数据还在,我们转而推出一个页面转成SQL的简易方案(不支持上卷、下钻、跨天和图形对比),虽然交互性差,但由于成本极低,一直支持长尾的数据需求。
2017年(数据重构)
年初遇到了一些问题,技术方面:1、部分数据产出延迟;2、维护成本高,人员流动性高;3、宽表不能完全满足需求,随之关联了几十上百张数据表;业务方面没有明确的收益预期;
调研了携程、阿里的数据体系之后,决定先重新搭建数据仓库,解决提升数据质量和降低人力成本,然后再发展个性化应用。步骤如下:
1. 协调资源
所谓资源,就是要人和时间。向BOSS说明兄弟部门投入多少多少人力和时间达到了什么效果,反观咱们只有那么点点...当然由于众志成城、团结一心,可以只用XX成本就能达到那个效果...
成功之后,自己也认识到了差距,确实起点比较低,历经N次电话会议,逐步理解了数据仓库的搭建方案和应用细节
2. 搭建仓库
首先选型,kimball还是inmon,区别就不多说了。选择的是Kimball,为了让运营和产品用的更方便,也产出了宽表,这样宽表可以覆盖90%的需求,宽表+维度表可以覆盖剩下的需求。
2017的数据仓库结构图如下:
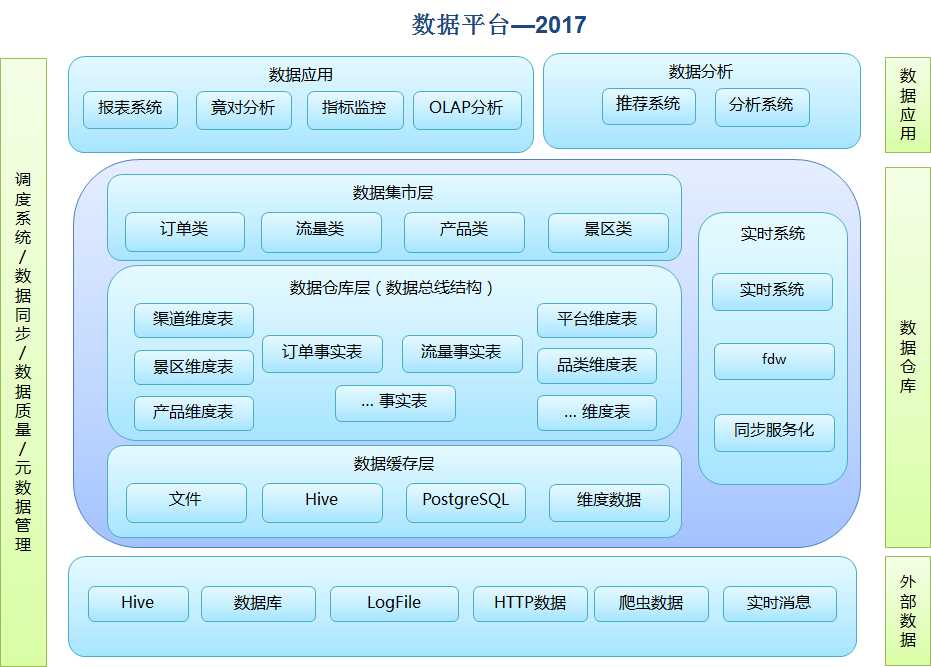
3. 维护
数据仓库要准确、及时的产出数据,由于数据分散人力有限,不可能保证所有数据都百分百符合预期,所以要对数据进行分级。首先BOSS关心的报表,以及依赖的数据表是一级重要,要实时的严格校验,这里叫强一致性校验,如果发现问题需要在任何时候电话+qt+邮件预警。财务和运营的KPI数据次之,白天qt+邮件预警即可,最后是其他的数据。
数据仓库的迭代周期也很关键,业务主要使用的是宽表,我们总结了以往的经验后,发现业务经常遇到新需求就希望在宽表增加字段,避免关联的烦恼,随着字段的增加,又不控制必然会重新陷入到到自然演化体系的困局。所以采用的办法是建立一个原则:准确+常用。如果符合这个原则的属性,是以月为单位排期加入到宽表里面,这样宽表就有了生命力
2018年(数据化运营)
这是正在进行的,仅介绍一下愿景,随着精细化运营的来临,必然对数据提出更细致更及时的要求,那么以离线为主T-1的瓶颈更加凸显出来,所以要搭建实时的数据仓库。另外随着分析经验的积累,不能像以前那样粗狂的看报表,而要细分用户群,采用不同的策略,所以需要高质量的用户画像,那么今年会从实时+用户画像两个方面展开...