ng机器学习视频笔记(十二)
——PCA实现样本特征降维
(转载请附上本文链接——linhxx)
一、概述
所谓降维(dimensionality reduction),即降低样本的特征的数量,例如样本有10个特征值,要降维成5个特征值,即通过一些方法,把样本的10个特征值映射换算成5个特征值。
因此,降维是对输入的样本数据进行处理的,并没有对预测、分类的结果进行处理。
降维的最常用的方法叫做主成分分析(PCA,principal component analysis)。最常用的业务场景是数据压缩、数据可视化。该方法只考虑样本的特征,不考虑样本的结果标签,因此PCA是一种无监督学习算法。
二、PCA基础
1、目的
PCA的目的,是找到一个低维的超平面,让每个样本投影到该平面的距离的总和最短。通常样本投影之前还要进行均值化和归一化。
2、降维
当需要使用PCA,将样本数据从二维降到一维,即可以理解成在平面上,找到一个向量,使得平面上的所有点到该向量的垂直距离的总和最短,如下图所示:
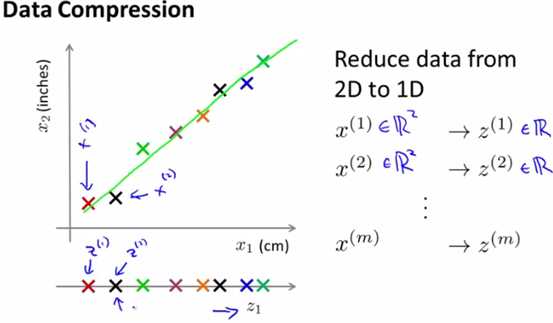
三维降维到二维如下图所示:
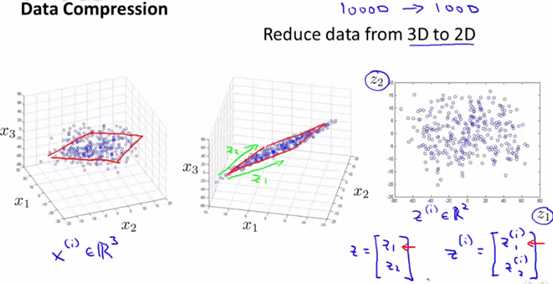
其中,每个样本到该向量的垂直距离,称为投影误差(projection error),u(i)表示第i个样本的投影误差,正值表示和向量同向,负值表示反向。下图的红线表示向量,蓝色的线表示投影误差。
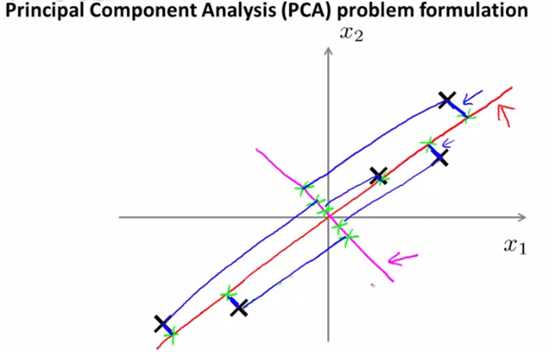
上图画出了红线和粉线,粉色的即错误的pca的结果,可以看出所有点到这个粉线的投影误差都非常大这个就是不正确的pca。而红色的线,相比之下,所有点到其的投影误差就非常小了。
3、定义
对PCA更通用的定义:
n维特征,要降维到k维,泽需要找出k个向量u(1) ,u(2) ,…u(k),让所有样本到由这些向量组成的超平面的距离之和最小。如下图所示:
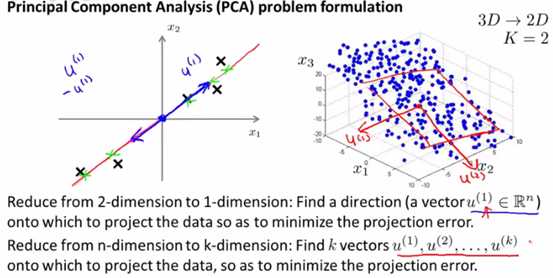
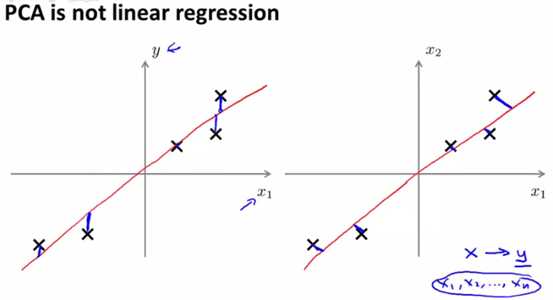
4、PCA与线性回归区别
上面PCA的例子,看起来非常像线性回归,然而实际上,PCA并不是线性回归。
线性回归,其二维图像的含义是,对于1个特征x,输出结果是y,即线性回归的纵轴是输出的标签y。因此,线性回归最终找到的线,其目的是让所有的样本的点距离这条线的纵向距离的和最小。
相比之下,PCA的图,是两个特征组成的图,x1和x2没有关联,只不过是一个样本的两个特征。其拟合的线,目的是使每个样本到这个线的垂直距离(即最短距离)的和最小。如下图所示,左边为线性回归的图,右边为PCA的图:
三、PCA计算过程
1、数据预处理
1)把各特征进行归一化,令这些特征在一个数量级中。
2)计算所有样本,每个特征值的均值。
3)把每个样本中的每个特征值,换成原特征值减去该特征值的均值。
2、计算所有样本的协方差,生成协方差矩阵Σ(注意这里的Σ是矩阵的标记,而不是求和的标记),Σ是一个n*n维的矩阵。
3、计算Σ的特征值和特征向量。
4、将特征值按照从大到小的顺序排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
5、将样本点投影到选取的特征向量上。
6、说明
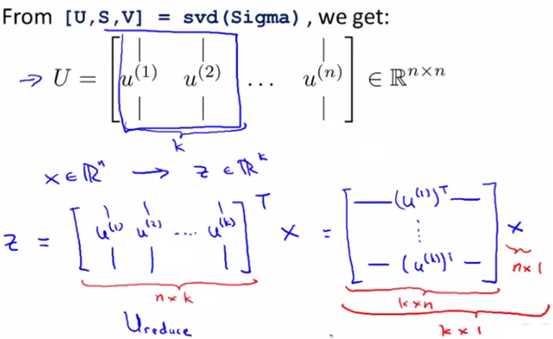
对于octave语言,求出Σ后,调用函数[U,S,V]=svd(Sigma),其中的U,是一系列由向量u(i)组成的矩阵,前面k个组成的矩阵即为PCA所需要的矩阵,这里把其称为Ureduce,注意这个U是一个正交矩阵,即UT=U-1,这个性质后面会用到。
最终投影的结果Z=UreduceT*Xapprox,这里的X不考虑x0=1这一项。
过程如下图所示:


四、选择合适的k
k表示的是降维后的维度,诸如数据压缩等场景,没有明确的降维的维度要求,则需要有一个概念来衡量降维的效果。这里引入一个公式,可以衡量降维的效果。
降维的效果 = 平均投影误差 / 总方差,如下图所示:

当计算结果为0.01,表示样本的99%的方差性会被保留,这个值越大表示样本损失的特征越少。这里根据需要,可以设定不同的结果,例如要求0.05,则是保留95%的方差性。
因此,判断k值的方法如下:
1)k初始值设置为1。
2)计算Z、Ureduce、Xapprox(即预处理后的输入样本)。
3)按上面的公式,计算结果是否大于要求(例如要求是0.01)。
4)如果不是,则k+1,然后重复2、3步骤,直到满足条件。
这样计算量很大,在octave中,有简化算法,上面公式[U,S,V]=svd(Sigma)中的S,即特征值排序后组成的对角矩阵,则公式有简化算法,如下图所示:

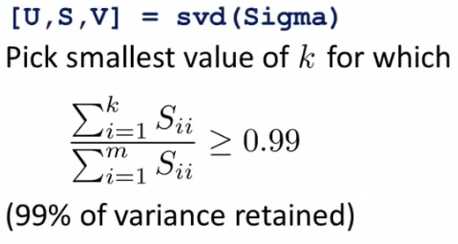
五、重建特征值
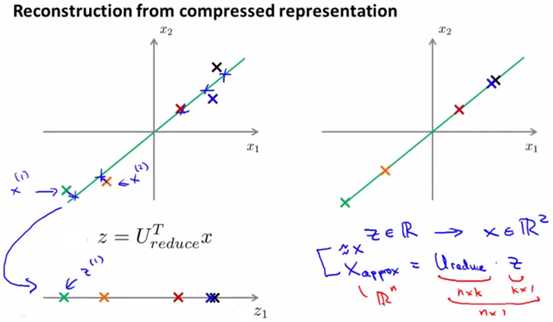
重建(reconstruction)特征值,即把被压缩的特征值还原回原来的维度。根据式子Z=UreduceT*Xapprox,因此Xapprox=( UreduceT)-1*Z。
另外,由于上面提到,U是一个正交矩阵,其转置矩阵和逆矩阵的结果是一样的,因此公式可以写成Xapprox=Ureduce*Z。
考虑到Xapprox≈X,因此重建特征值后,结果即为X≈Xapprox= Ureduce*Z,如下图所示:
六、PCA使用建议
1、使用
在监督学习中,假设输入的样本是(x(1),y(1)), (x(2),y(2))…(x(m),y(m)),现考虑使用logistic回归,用PCA来简化计算,方法如下:
1)提取出x(1), x(2),…x(m),即不考虑y。
2)用PCA把其映射成z(1), z(2),…z(m)。
3)拼接回y,形成(z (1),y(1)), (z (2),y(2))…(z (m),y(m))。
4)进行参数计算,计算出θ,得到公式hθ(z)=1/(1+e-θTz)。
5)对于新输入的x,映射成z后,带入上面的h(z)即可。
2、反例
1)不宜用于解决过拟合
PCA算法,可以减少特征值的数量,因此对于过拟合的缓解是有作用的。但是,考虑到还有更优的解决过拟合的方式——正则化,因此不要用PCA来解决过拟合。
其中主要的问题,在于PCA的压缩过程,会丢失一些样本的特性,而正则化不会丢失太多的样本特性。
2)不能无脑使用PCA
PCA是有助于加速机器学习的学习过程,但是不能无脑的使用。建议所有的算法,都先用全量特征参与学习,只有发现真的速度太慢、占用太多的内存或硬盘,才考虑使用PCA。
3、实际应用
PCA主要用于数据压缩和数据可视化。
1)数据压缩
数据压缩,主要目的是减少内存和硬盘的使用,并且加速机器学习的速度。对于此目的,需要用上面介绍的方式,设定一个压缩后数据丢失的容忍值,然后计算出最合适的最小的降维维度k。
2)数据可视化
数据可视化,通常只能在二维、三维,因此此时直接将数据降维到二维或者三维即可。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。