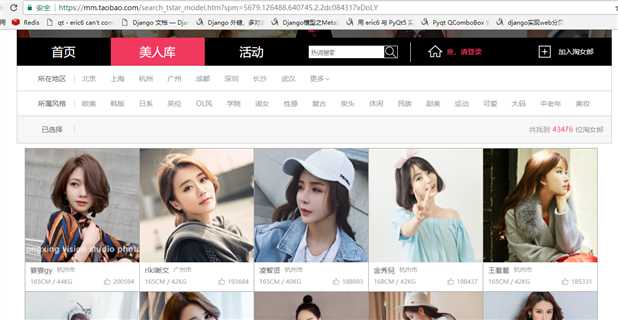
先上一高清无码大图,让大家过过眼瘾。
爬虫一共就四个主要步骤:
1、明确目标:明确需要抓取那些内容,在哪个网页
2、爬:分析网站结构,将所有的网站的内容全部爬下来
3、取:提取我们所需要的数据
4、处理数据:按照需求存储使用
第一步:
明确目标:
网站url: https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.2dc084317xDoLY
抓取内容:
头像:存储在本地硬盘。
名字,城市,身高,体重,点赞数: 保存在mysql数据库
说明:这里只是用作教程并非真的要将爬取的内容作为其它用途,我只是单纯想看看淘宝小姐姐的卓越风姿。
第二步爬:
使用到的模块:
python 3.6: python环境
requests: 发送请求
pymysql: 操作mysql
queue: 队列
random: 产生随机数
想要看懂这篇文章,还是需要那么一丢丢的python基础知识。
分析网页结构:
1、确定网页数据的请求方式‘GET‘还是‘POST‘,ajax异步请求还是直接浏览器请求,一般ajax请求的url跟我们在浏览器上的url地址栏看到是不一样的,所以我们需要使用到浏览器的开发者工具抓包查看。
我观察了下淘女郎这个模特库首页是有分页的,这里有个小技巧,来确定请求方式:
我这里使用的是谷歌浏览器,按F12打开浏览器的开发者工具,切换到netrork选项,然后将网页拉到最下面有分页的地方。
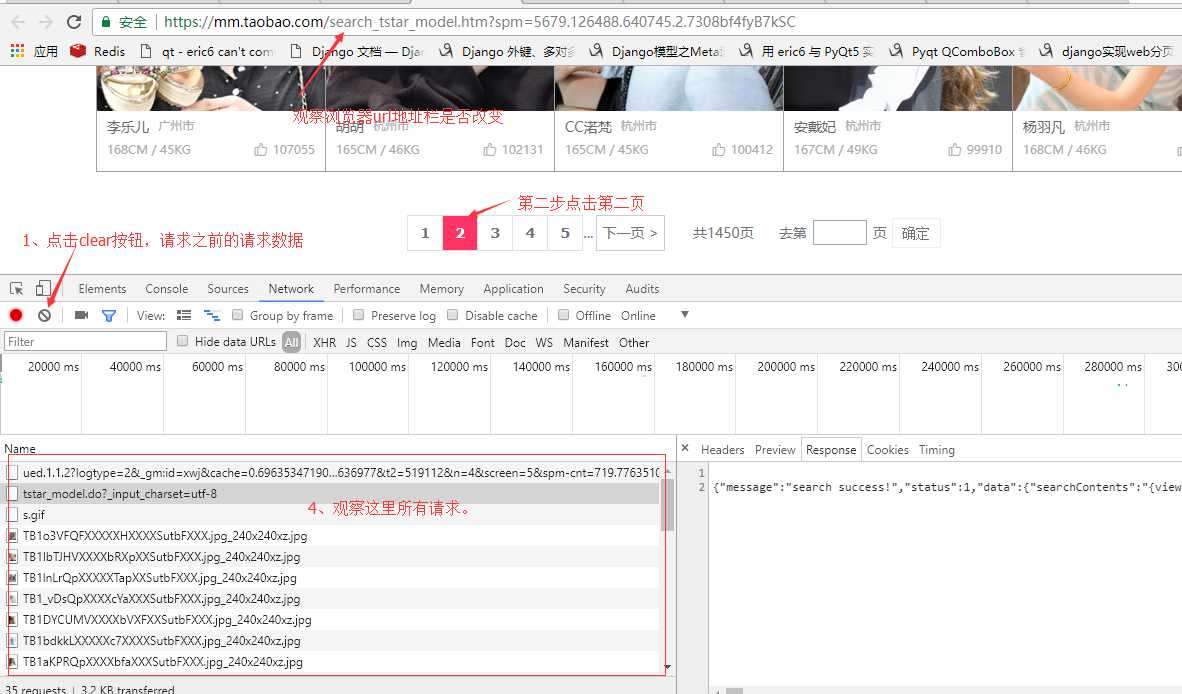
我们观察url地址栏上的地址并没有发生改变,所以地址栏上的url对我们没有帮助!这也说明这个网页的内容是通过ajax加载的。
查看图片上4的位置所有请求的url,发现第一个请求并没有返回任何数据,只有第二个请求有返回数据第三个请求之后的全部都是请求图片的。
选中第二个请求,选中response,查看返回的数据是json数据,可以将json数据复制到json在线解析网站解析看下返回的是什么,解析出来后我们发现,json数据 "searchDOList" 字段就是包含了当前页所有淘宝小姐姐的信息。
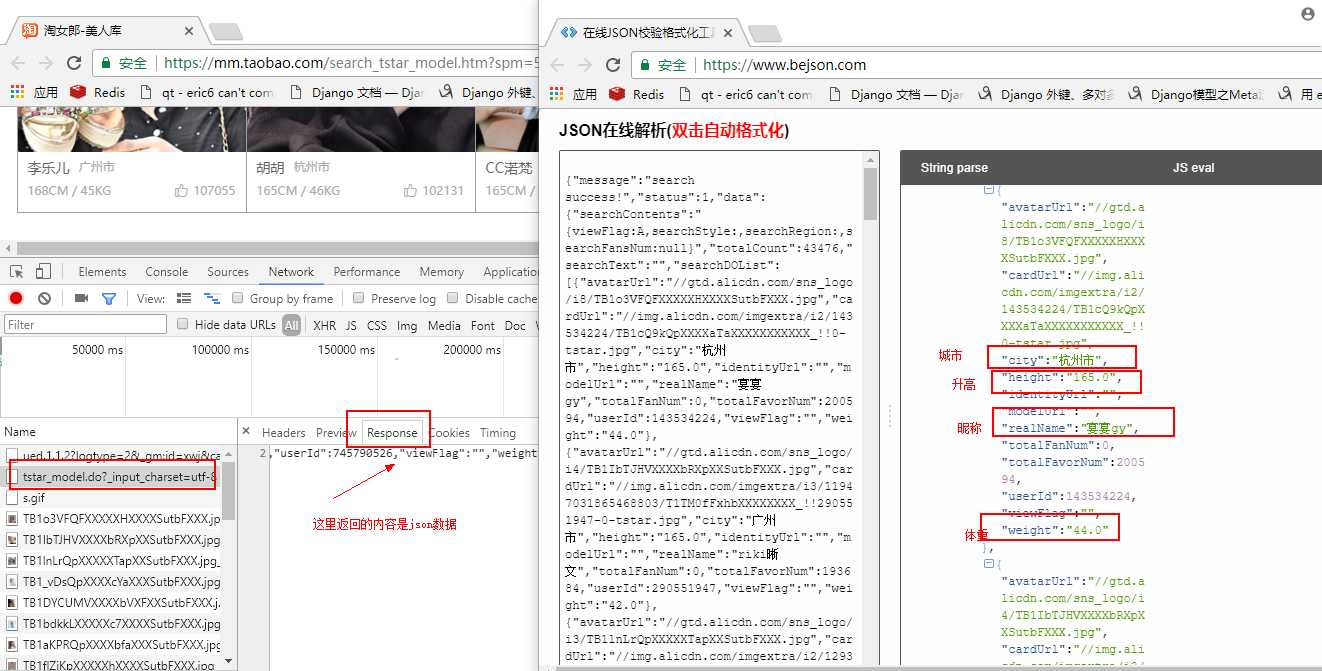
确定我们需要的数据就是在第二请求之后,我们回到开发者管理工具,点击headers查看请求头信息。
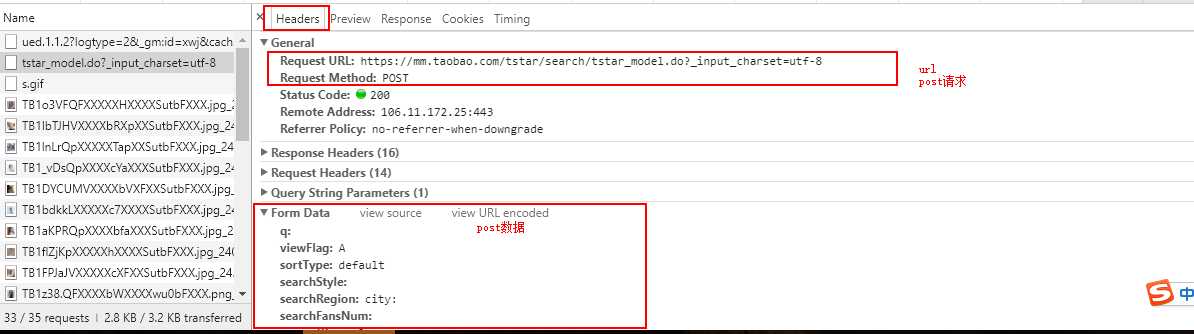
标红框的这几个数据等会写爬虫会用到,分析到这里我们就拿到了等下写爬虫需要的数据:
```
url:https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8 请求方式:post post参数: q: viewFlag:A sortType:default searchStyle: searchRegion:city: searchFansNum: currentPage:2 pageSize:100 ```
淘女郎一共有1450页,所以采取多线程的方式进行抓取。
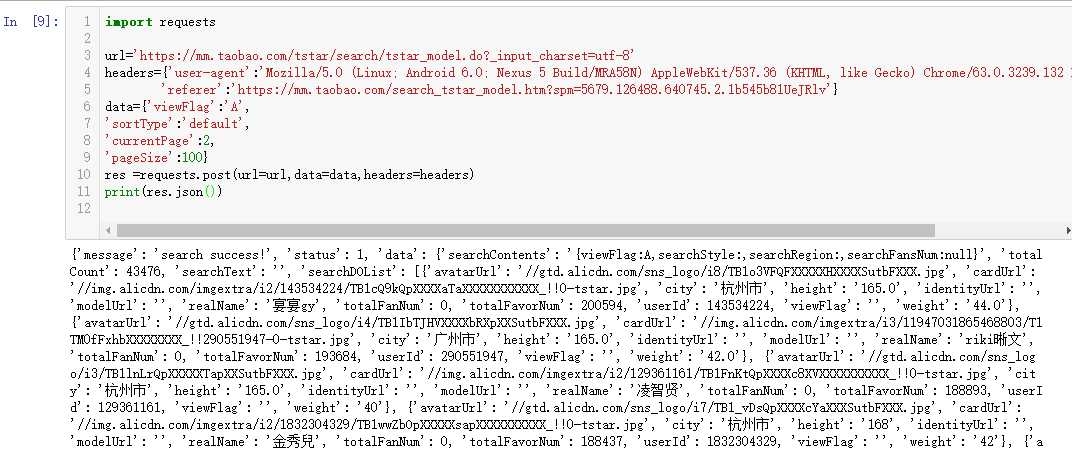
import requests url=‘https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8‘ headers={‘user-agent‘:‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘, ‘referer‘:‘https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.1b545b81UeJRlv‘} data={‘viewFlag‘:‘A‘, ‘sortType‘:‘default‘, ‘currentPage‘:2, ‘pageSize‘:100} res =requests.post(url=url,data=data,headers=headers).json()
未完待续。。。。