1、Spark是什么
Spark是一个用来实现快速而通用的集群计算的平台。
2、Spark是一个大一统的软件栈
Spark项目包含多个紧密集成的组件。首先Spark的核心是一个对由很多计算任务组成的、运行在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。
Spark的个组件如下图所示:
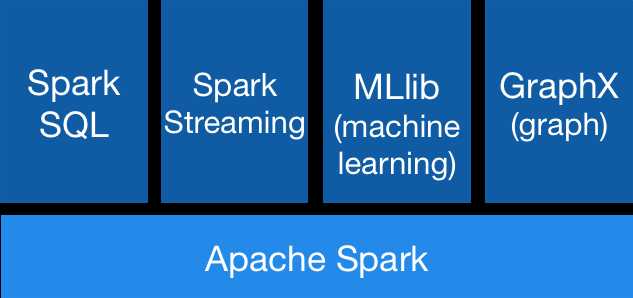
- Apache Spark 也就是Spark的核心部分,也称为Spark Core,这个部分实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互模块,还包含了对弹性分布式数据集(RDD)的API定义。
- Spark SQL是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者HQL来查询数据。
- Spark Streaming 是Spark提供的对实时数据进行流式计算的组件。比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是消息流
- MLlib这是一个包含了常见机器学习功能的程序库,包括分类、回归、聚类、协同过滤等
- GraphX是用来操作图的程序库,可以进行并行的图计算。
3、Spark的核心概念
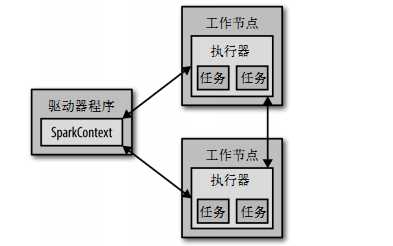
从上层来看,每个Spark应用都由一个驱动器程序来发起集群上的并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表对计算集群的一个连接,当Spark shell启动时已自动创建了一个SparkContext对象。
val textFile = sc.textFile("hdfs://...") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")
这里的sc变量,就是自动创建的SparkContext对象。通过它就可以来创建RDD,调用sc.textFile()来创建一个代表文件各行文本的RDD。
通过RDD我们就可以在这些行上进行各种操作,通常驱动器程序要管理多个执行器节点。比如,如果我们在集群上运行输出操作,那么不同的节点就会统计文件不同部分的行数。
4、初始化SparlContext
一旦完成了应用与Spark的连接,接下来就需要在程序中导入Spark包并创建SparkContext.我们可以通过先创建一个SparkConf对象来配置应用,然后基于这个SparkConf来创建一个Sparktext对象。
val conf = new SparkConf().setAppName("wordcount").setMaster("local") val sc = new SparkContext(conf)
这里创建了SparkContext的最基础的方法,只需要传递两个参数:
- 应用名:这里使用的是"wordcount ",当连接到一个集群的时候,这个值可以帮助我们在集群管理器的用户界面中找到你的应用,这是这个程序运行后的集群管理器的截图

- 集群URL:告诉Spark如何连接到集群上,这里使用的是local,这个特殊的值可以让Spark运行在单机单线程上而无需连接到集群上