我们在开发中会进场用到List来进行数据的处理尤其是它的两个实现ArrayList、LinkedList
但是这两种实现究竟有什么区别,这个在之前一直是没有仔细考虑的,一般写代码就直接一个ArrayList实现初始化对象,在企业级的互联网开发中比较少有数据处理超过100万的,这导致了我们在开发中对这两个实现的具体适合的应用场景有所忽略。
那么下面我们从这两种实现类的存储原理、源代码处理逻辑来进行分析,找出这两种类的区别以及何时的使用场景。
环境JDK8
一、 存储原理:
1、ArrayList内存存储原理:
ArrayList的类成员变量


private static final int DEFAULT_CAPACITY = 10; private static final Object[] EMPTY_ELEMENTDATA = {}; private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; transient Object[] elementData; private int size;
从成员变量的定义可以看出ArrayList是对数组的一个封装,那么这时候可以根据数组的特点初步判断:在进行正常的读写操作时将会是比较便利的。
2、LinkedList内存处处原理:
LinkedList的类成员变量:
transient int size = 0; transient Node<E> first; transient Node<E> last; private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
我们可以看到LinkedList的两个关键的变量first、last,类型是一个内部的Node类,而且里面有next以及prev两个引用以及泛型对象本身的引用,这是一个链表式的结构:
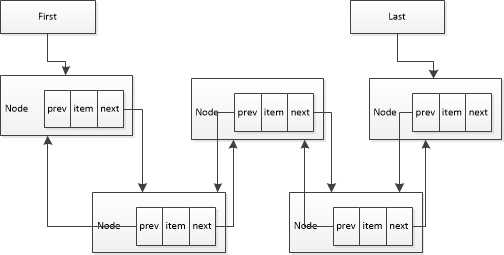
此结构不难看出:要对这个链表结构进行操作一定是从first或者last开始的,获取中间的元素都要通过一个一个遍历的方式来进行获取,当然其也有他的优势,在排序或者常规递增增加元素时有ArrayList所没有的优势。
二、功能实现对比
1、List的常规add(obj)方法
(1)ArrayList实现
public boolean add(E e) { ensureCapacityInternal(size + 1); elementData[size++] = e; return true; } private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {//确认初始化的容器大小是否是长度为0的容器 minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity);//判断容器是否满足要求,进行扩容 } private void ensureExplicitCapacity(int minCapacity) { modCount++; if (minCapacity - elementData.length > 0) grow(minCapacity); } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1);//以原大小的一半进行扩容 if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);//新建一个数组然后将原数组进行复制 } private static int hugeCapacity(int minCapacity) {//最大容量是Integer.MAX_VALUE if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
这段代码可以看出如果new一个ArrayList没有进行大小初始化的时候,在第一次add的时候会有一个初始化容器大小10,在操作过程中如果出现容器大小不够时,会重新创建一个3/2大小容量的数组,然后进行数组复制。也就是说如果在容器够的情况下ArrayList
的操作速度还是很快的。
(2)LinkedList实现
public boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
典型的链表操作逻辑,重新new一个Node节点然后调整last引用以及newNode和lastNode内部的引用,达到add的操作效果。从实现原理来看LinkedList是没有add的数量上限的,并且add操作的也比较快。
2、List的常规add(int index, E element)方法
(1)ArrayList实现
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); //扩容判断以及执行 System.arraycopy(elementData, index, elementData, index + 1, size - index);//将index往后的元素整体向后移动一位 elementData[index] = element; size++; }
这里的实现很明显这种操作需要对数组内容copy,并且index的值相对于容器size越小,进行copy的元素就越多,资源消耗的也就越多了。
(2)LinkedList实现
public void add(int index, E element) { checkPositionIndex(index);//进行index越界检查 if (index == size) linkLast(element);//直接进行尾部追加 else linkBefore(element, node(index)); } Node<E> node(int index) {//遍历找到对应的Node节点 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
在插入某一个节点时,还是会对链表进行遍历,找到对应index位置的节点,然后进行节点的插入操作,也就是index的值相对于容器size的值越大,遍历的数量越多,相应的消耗的也越多,这种情况会比ArrayList的会优越一些。
3、List的常规get(int index)方法
(1)ArrayList实现
public E get(int index) { rangeCheck(index); return elementData(index); } public E get(int index) { rangeCheck(index); return elementData(index); } E elementData(int index) {//直接通过数组下标获取元素返回 return (E) elementData[index]; }
内部实现直接通过数组下表获取元素这种方式无疑是最快的方式了。
(2)LinkedList实现
public E get(int index) { checkElementIndex(index); return node(index).item;//通过遍历获取对应index位置的元素 }
从实现上可以看到index位置越是靠后,需要遍历的元素就越多,这种方法的性能是没法跟ArrayList进行比较的。
4、List常规方法remove
(1)ArrayList实现
public E remove(int index) {//直接通过index对数组进行copy移位,并且最后一个赋值null rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index,numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; } public boolean remove(Object o) {//先要遍历对比,获取对应的index然后进行移除操作 if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; } private void fastRemove(int index) {//数组移除,需要将index后的数据copy前移一位,最后一位赋值null modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index,numMoved); elementData[--size] = null; // clear to let GC do its work }
两种remove都要进行数组中部分元素的copy移位,不同的是remove(obj)多了一个遍历比较的过程。
(2)LinkedList实现
public E remove(int index) { checkElementIndex(index); return unlink(node(index));//node方法遍历寻找对应的index的node然后调用unlink } public boolean remove(Object o) {//遍历比较相等的数值找出对应的node然后调用unlink if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next;//目标节点的下一个节点 final Node<E> prev = x.prev;//目标节点的上一个节点 if (prev == null) { first = next;//边界情况 } else { prev.next = next;//改变上一个节点的next引用 x.prev = null;//这里进行引用的消除方便回收 } if (next == null) { last = prev;//边界情况 } else { next.prev = prev;//改变下一个节点的prev引用 x.next = null;//这里进行引用的消除方便回收 } x.item = null;//这里进行引用的消除方便回收 size--; modCount++; return element; }
两种remove都要进行遍历,然后调用unlink进行链路节点的删除,不同的是remove(obj)多了一个equals的对比操作
小结:
通过以上的list常用的功能对比他们的实现,暂做出如下的总结:
当list的读操作比较多(不涉及排序、无序插入、元素移除)时,ArrayList具有明显的优势,如果可以根据业务判断容器使用的大小,那么ArrayList是绝佳的选择。
而LinkedList在排序、无序插入、元素移除等写的方面具有优势。
我们在使用的时候可以根据业务场景判断读写的具体情况进行选择。
补充:
ArrayList以及LinkedList都实现了iterator相关的接口,但是获取的iterator对象的相关遍历操作都是基于原有的数据存储结构进行操作的,因此在性能上与原有的list本身操作并无差距
三、性能测试验证
我们已经了解了数据的存储结构,以及根据接口实现原理大致推断了性能差别,但是还是需要实际的测试进行验证,关于验证会在后续进行补充的