What is machine learning?
实际上,即使是在机器学习的专业人士中,也不存在一个被广泛认可的定义来准确定义机器学习是什么或不是什么,本课程中给出了两个定义
1:Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
这个是一种更久远的定义,Arthur Samuel将其定义为“给予计算机能自我学习的能力而不是编程”
2:Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
这一个更新的定义是Tom Mitchell 提出的,“对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习。”
Machine learning algorithms
1:Supervised learning(监督学习)
2:Unsupervised learning(无监督学习)
3:Others: Reinforcement learning, recommender systems.
Supervised Learning
通过已有的训练样本来训练,得到一个最优的模型,利用这个模型可以将新的数据输出相应的值。
监督学习分为“回归”(regression)和“分类”(classification)。
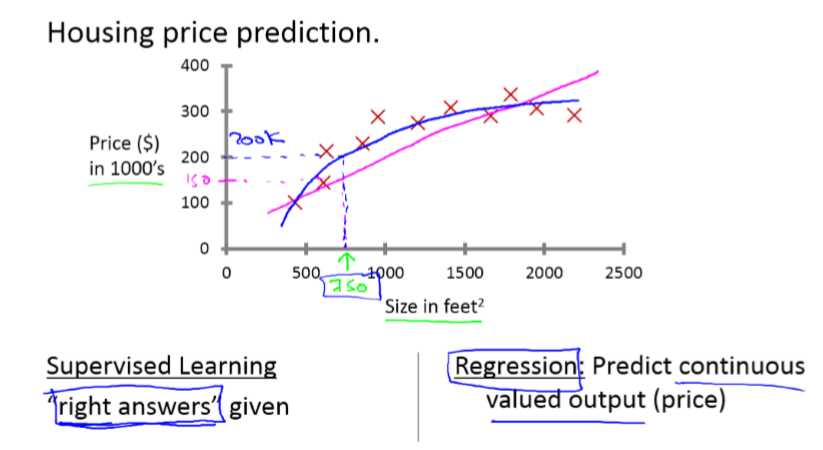
回归问题:预测一个连续的值。
列如通过房屋大小来预测相应的价值
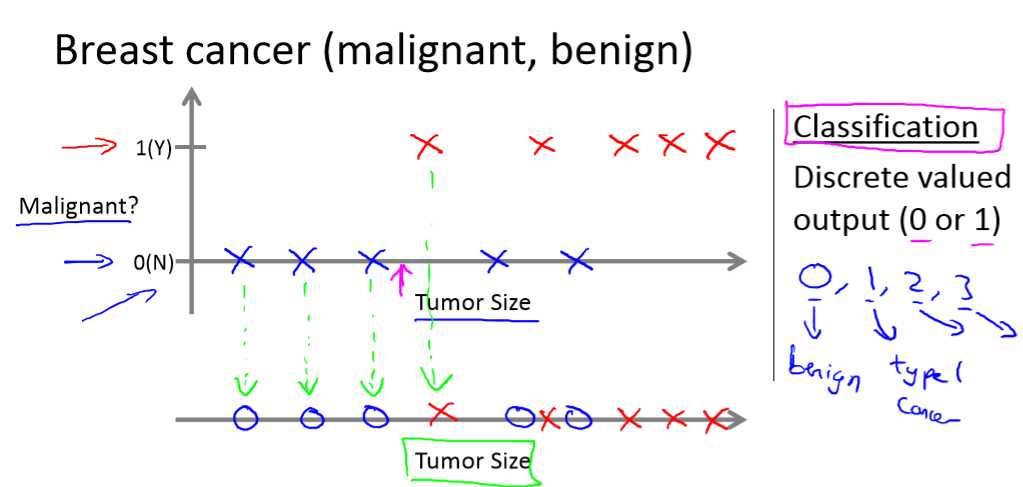
分类问题:预测一个离散的值。
列如给定肿瘤大小来判断是良性的还是恶性的。
Unsupervised Learning
在监督学习中,我们明确的知道我们需要的结果是什么,但在无监督学习中,我们是不知道产生的结果是什么的。
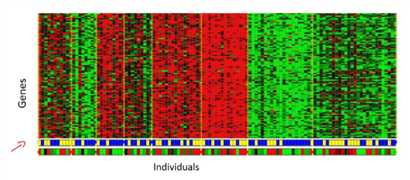
在无监督学习中,我们只有一个数据集,聚类算法可以将一个数据集分成多个聚集簇。当然,无监督学习还有其它算法。
列如聚类:收集1,000,000个不同的基因,并找到一种方法,将这些基因自动组合成相似或相关的不同变量,如寿命、位置、角色等。
Linear regression with one variable(单变量线性回归问题)
Model representaion
让我们看一个例子:
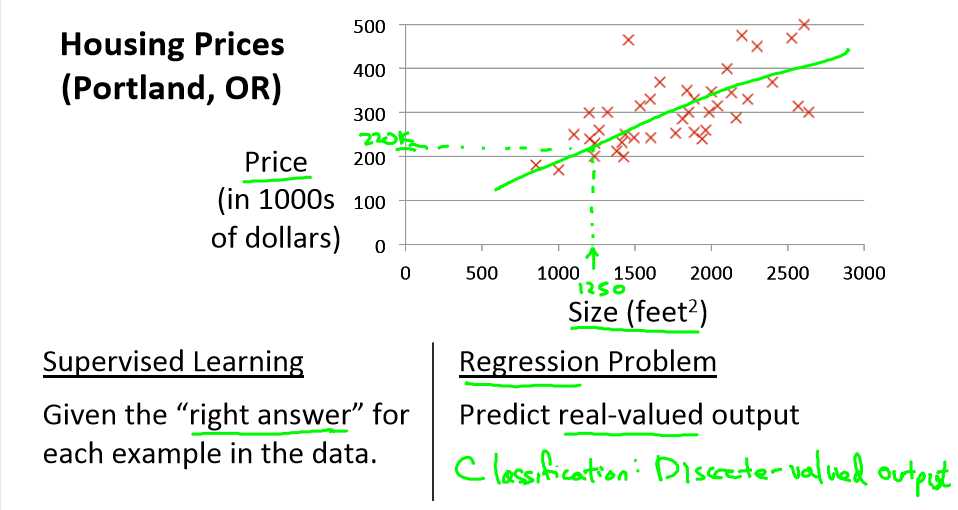
预测住房价格问题
如果你朋友的房子大小是1250平方尺大小,你要告诉他这个房子能卖多少钱。那么你可以做的就是建立一个模型,从这个数据模型上来看,也许你可以告诉你的朋友,他大概能卖220000美元。
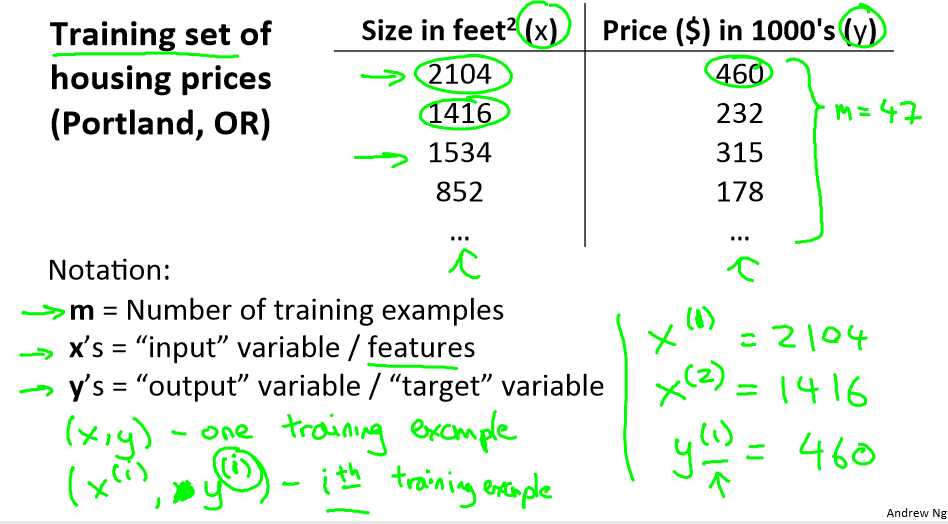
下面说下符号定义,为了更好的理解。
m:代表训练集中实例的数量
x:代表特征/输入变量
y:代表目标变量/输出变量
(x,y):代表训练集中的实例
(x(i),y(i)):da代表第i个观察实例
h:代表学习算法的解决方案或函数也称为假设(hypothesis)
下面是一个监督学习的工作方式:
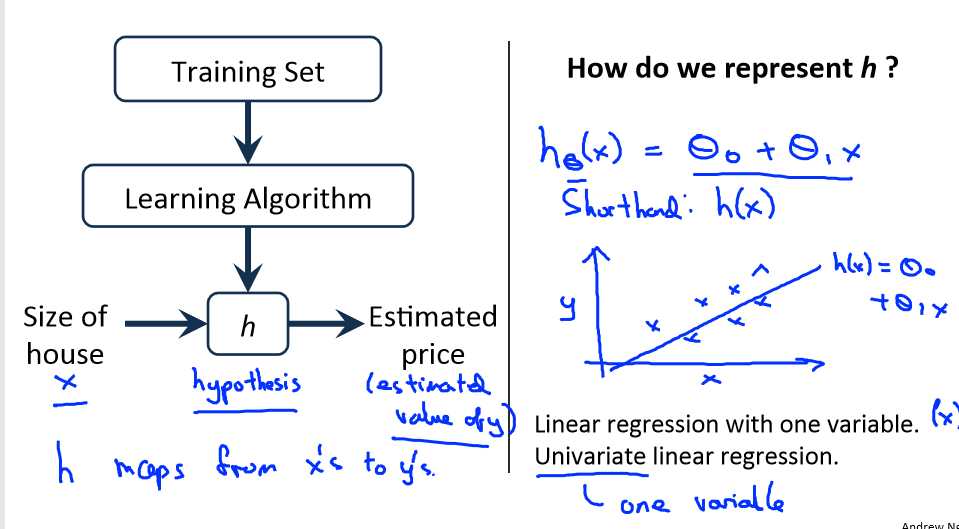
将y关于x的线性函数表示为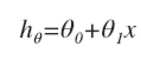 ,因此这样的问题也叫做单变量线性回归问题。
,因此这样的问题也叫做单变量线性回归问题。
Cost funcion(代价函数)
代价函数在我的理解中是使的目标函数最优。

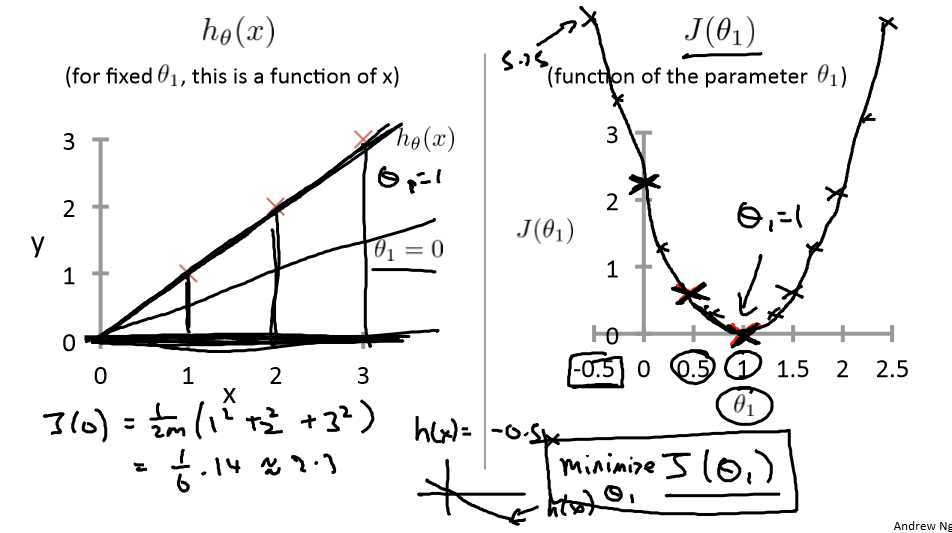
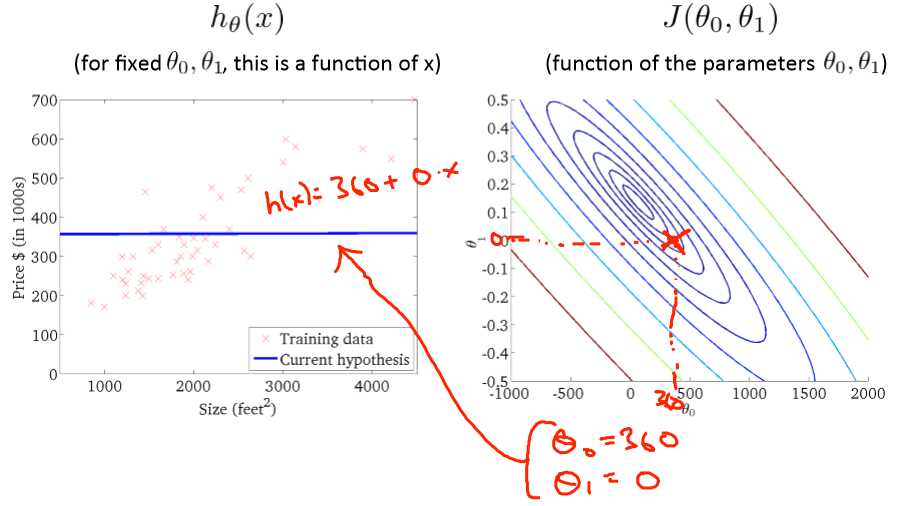
例如我们有m=47,我们的假设函数是![]() ,我们需要的是为这个模型选择合适的参数θ0和θ1 ,使的误差最小。
,我们需要的是为这个模型选择合适的参数θ0和θ1 ,使的误差最小。
可以向下面那样选择:
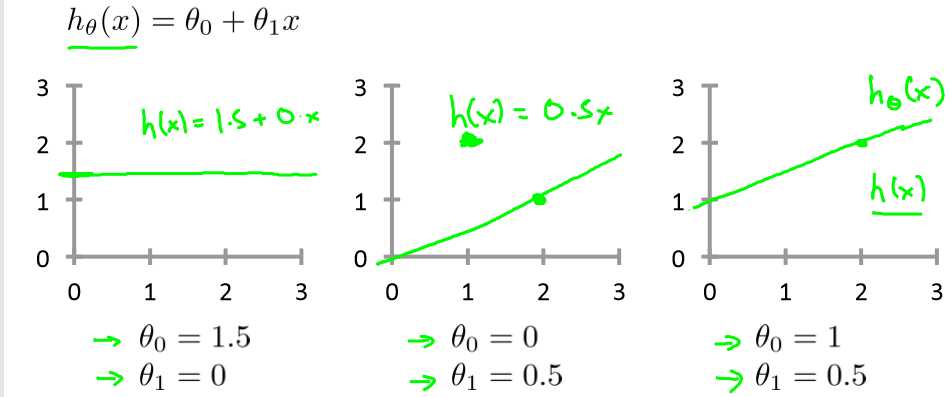
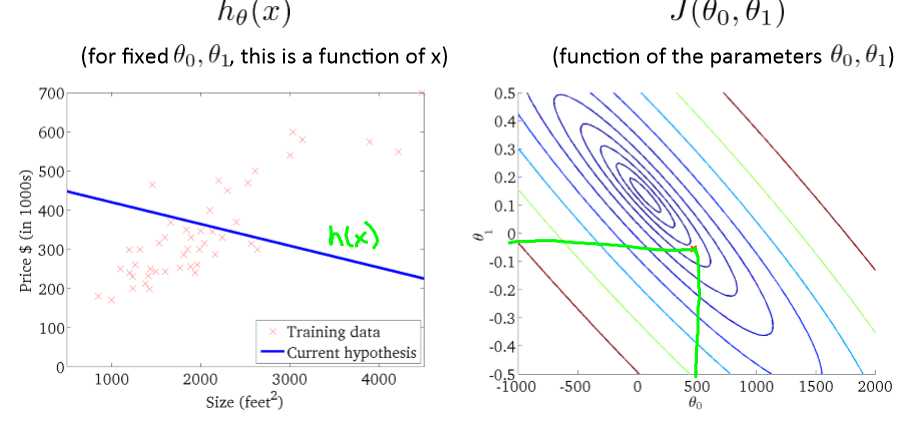
而我们需要的是让误差最小,即目标函数最优解。也就是求下面J函数的最小值
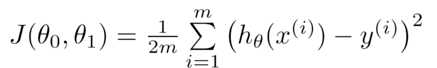

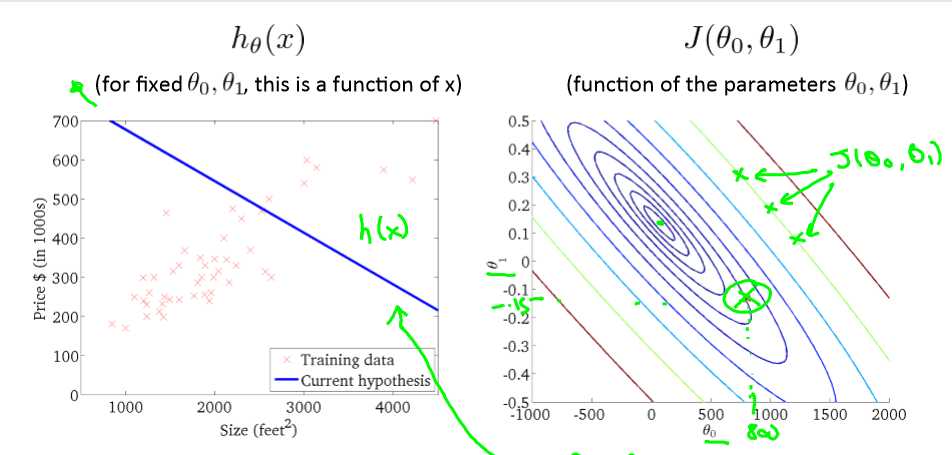
设θ0=0,即过原点,θ1为x轴,J为y轴,可以得出不同的θ1对应的不同的J,由右图明显得出θ1=1时误差最小。
学习算法的优化目的是找到一个最优的θ1,使的J(θ1)最小化,上图就是θ1=1时,J(θ1)最小化。
上面那个例子的代价函数三维图如下:
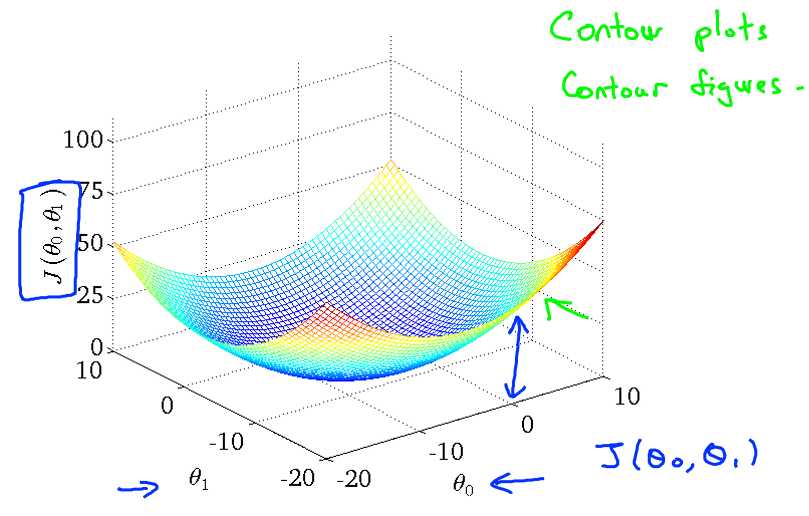
也可以在二维图种用轮廓图代替
Gradient descent(梯度下降法)
梯度下降法可以让代价函数J得到最优化

假设只有两个θ,当然多个也是一样的。先初始化θ0=θ1=0,然后每次都往θ0,θ1下降最快的方向移动,不停的改变θ0和θ1的值,最后就可以得到最小值了。当然也可能是局部最小
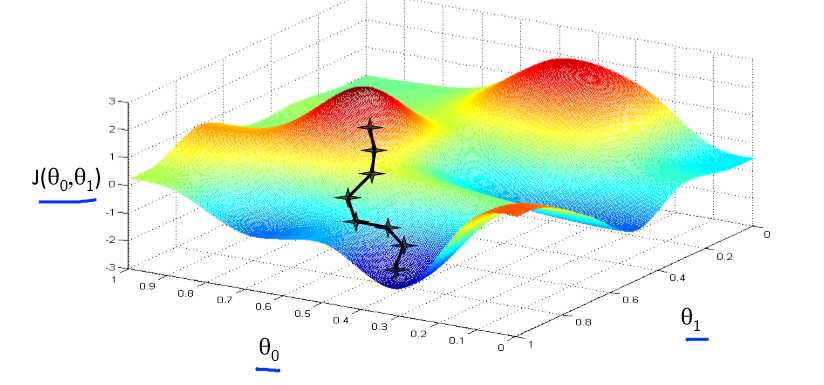
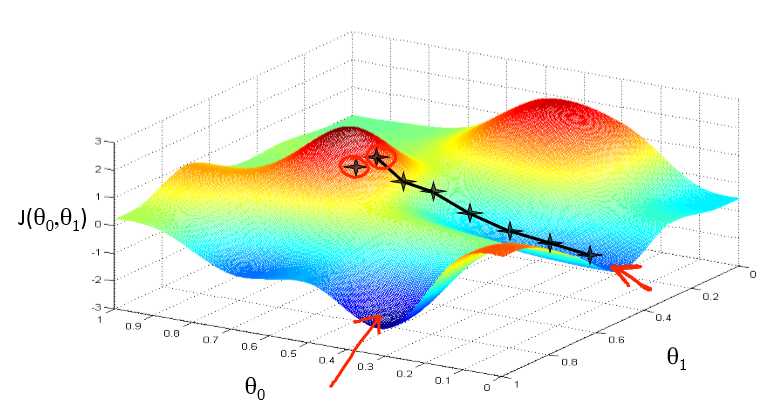
可以想象成你在山顶,你想以最快的步伐到山地,看到每次都是往斜度最大的方向走,梯度下降法也是类似的。


α表示学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
θ0,θ1必须同步更新,不然会出错。
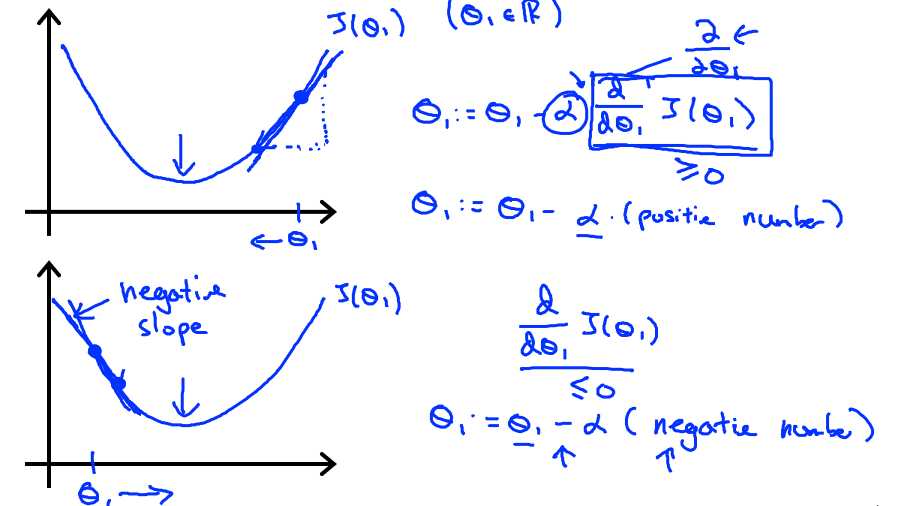
α要是个正值,负值的话会往高处走,得不偿失了。
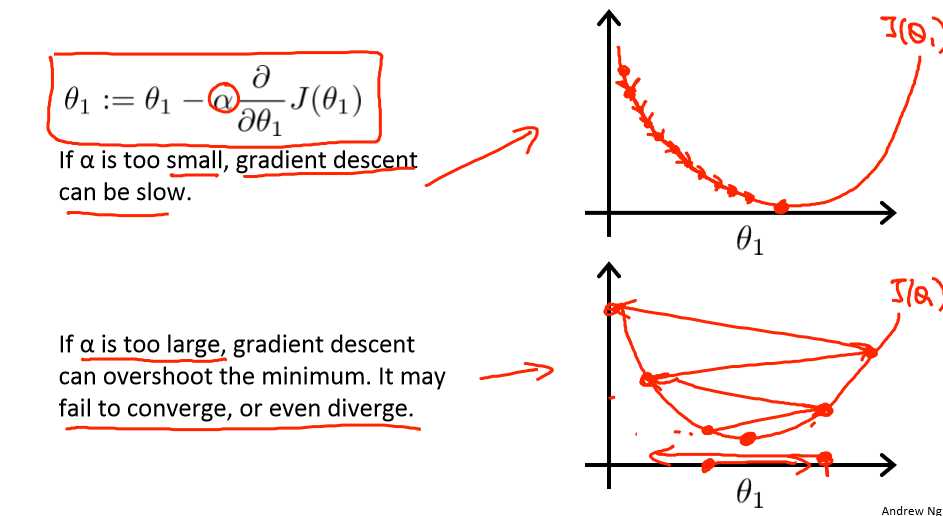
如果α大小,结果是它一点一点的挪动,非常的缓慢,需要很多步才能到达全局最低点。
如果α太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛乃至发散。知道你发现实际上离最低点越来越远。
如果θ1初始化在局部最低点,在这儿,它已经在一个局部的最优处或局部最低点。结果是此处的导数是0,那么θ1将不会变,一直是原来的那个θ1,这也解释了为什么即使学习速率α不变时,梯度下降法也可以收敛局部最低点。
让我们看下下面这个例子:
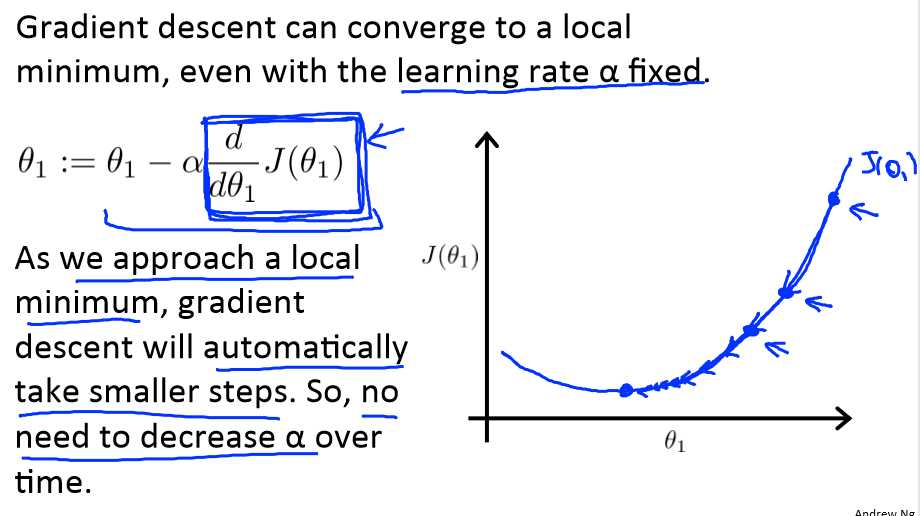
先初始化θ1的值,然后用梯度下降法一步一步往下移,当越接近最低点时,导数就越小,那么幅度也越接近0,直到等于0时θ1的值将不会被改变。
Gradient descent for linear regression
用梯度下降法运用在平方误差代价函数中,下图是梯度下降法和线性回归算法的比较:

想要最优化J(θ0,θ1),就要不断的改变θ0,θ1的值。直到J(θ0,θ1)收敛。J(θ0,θ1)的导数如下:
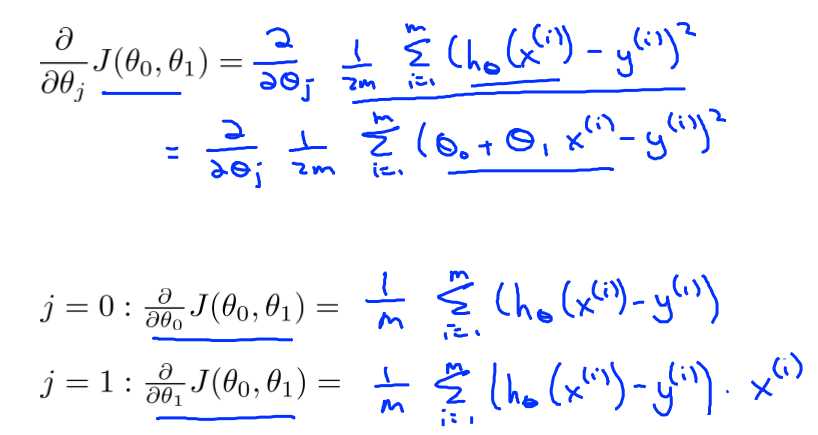
那么梯度下降法就变成了:
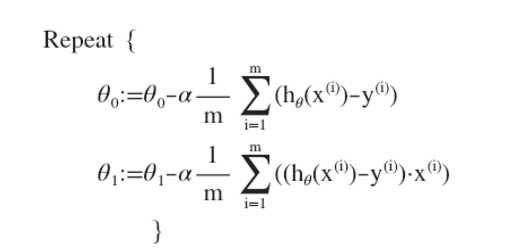
刚刚使用的算法有时候也叫批量梯度下降法,就是不断重复这个步骤,知道得到最优值。
找到最优解:
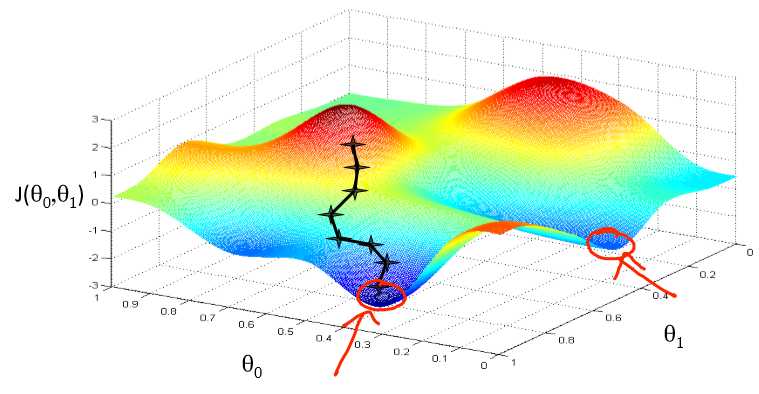
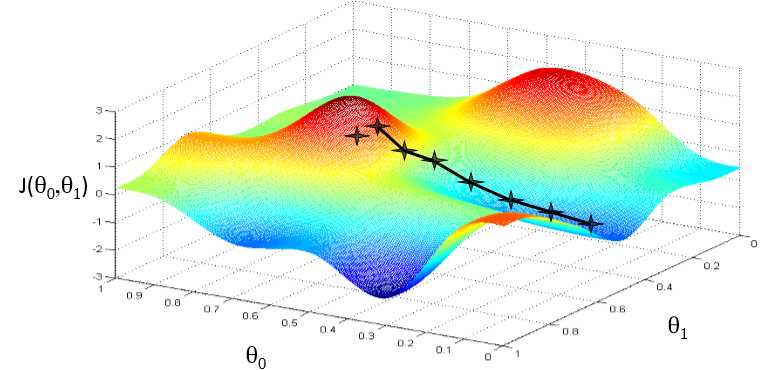
执行梯度下降时,根据你的初始值的不同,可能会得到不同的局部最优解。
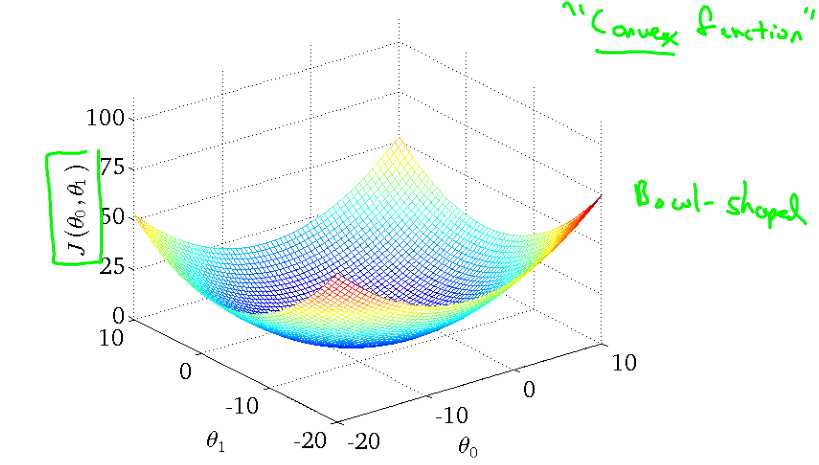
但是线性回归的“代价函数”总是这样一个弓形的样子(凸函数)凸函数是没有局部最优解,只有一个全局最优解。无论什么时候对这种代价函数使用线性回归,梯度下降得到的结果总是收敛至全局最小,没有全局最优以外的局部最优。