Support Vector Machines(支持向量机)
Optimization objective
与逻辑回归和神经网络相比,支持向量机,或者简称 SVM。在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
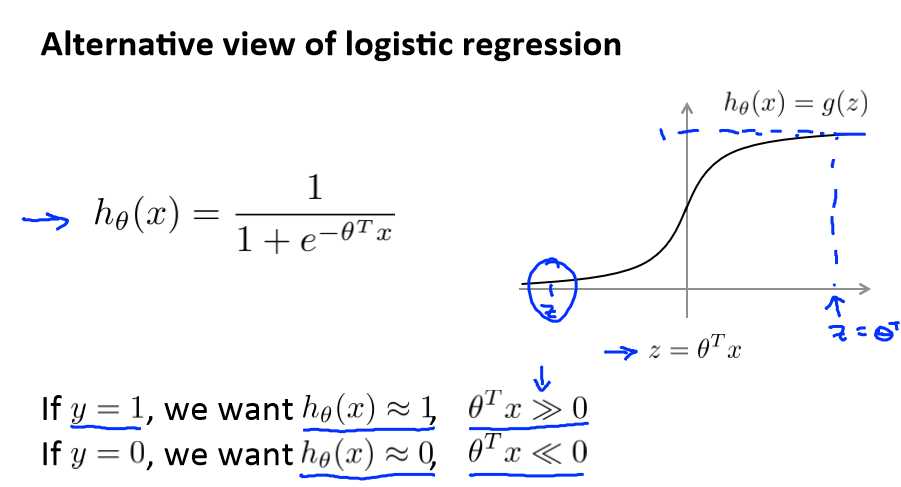
这是逻辑回归里的,右边是S型激励函数,我们用z表示θTx
但y = 1 和 y = 0 时的函数图如下:
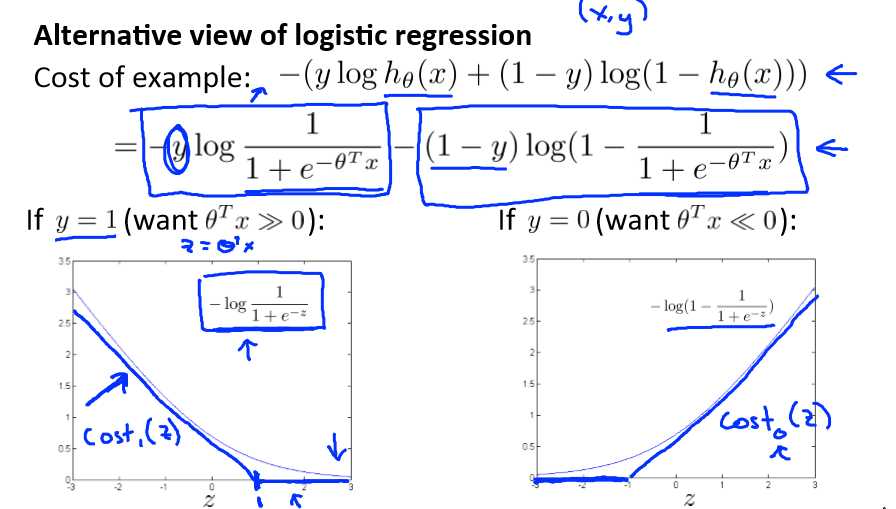
在逻辑回归中使用SVM如下:

然后最小化这个目标函数,得到 SVM 学习到的参数 C。
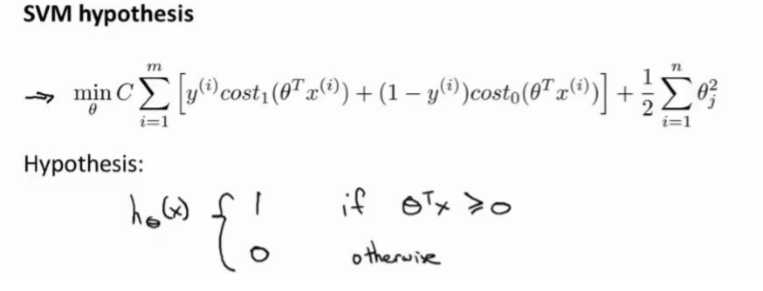
Large Margin Intuition
人们有时将支持向量机看作是大间距分类器。在这一部分,我将介绍其中的含义,这有助于我们直观理解 SVM 模型的假设是什么样的。
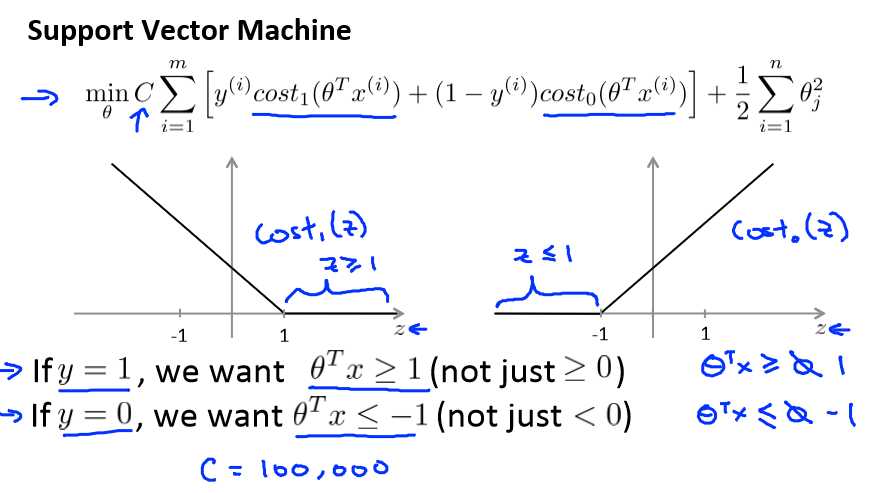
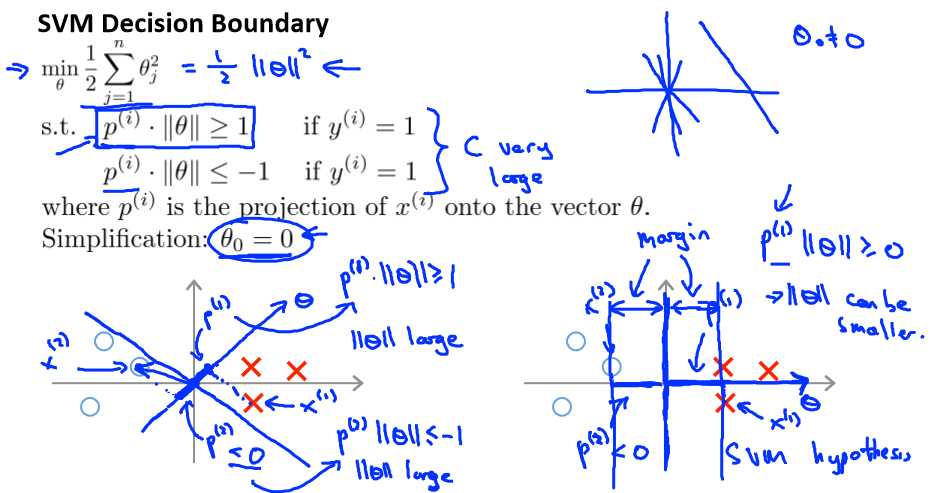
这是我的支持向量机模型的代价函数,在左边这里我画出了关于 z 的代价函数 cost1(z),此函数用于正样本,而在右边这里我画出了关于 z 的代价函数 cost0(z),横轴表示 z,现在让我们考虑一下,最小化这些代价函数的必要条件是什么。
支持向量机的要求更高,不仅仅要能正确分开输入的样本,即不仅仅要求θTx>0,我们需要的是比 0 值大很多,比如大于等于 1,我也想这个比 0 小很多,比如我希望它小于等于-1,这就相当于在支持向量机中嵌入了一个额外的安全因子。

如果 C 非常大,则最小化代价函数的时候,我们将会很希望找到一个使第一项为 0 的最优解。因此,让我们尝试在代价项的第一项为 0 的情形下理解该优化问题。比如我们可以
把 C 设置成了非常大的常数,这将给我们一些关于支持向量机模型的直观感受。
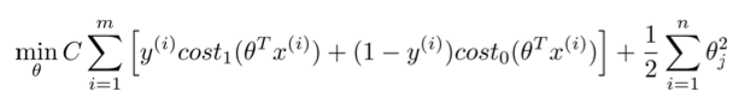
这将遵从以下的约束:θTx(i) >= 1,如果 y (i)是等于 1 的,θTx(i)<=-1,如果样本 i是一个负样本,这样当你求解这个优化问题的时候,当你最小化这个关于变量θ的函数的时候,你会得到一个非常有趣的决策边界。
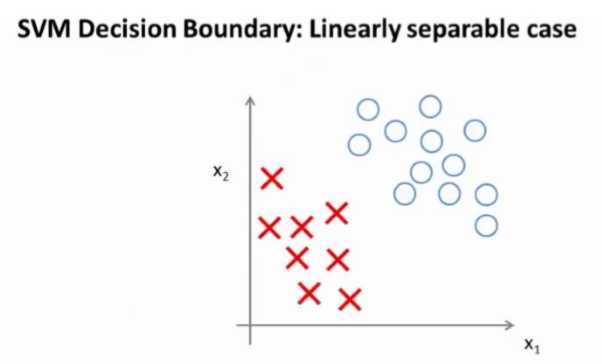
存在一条直线把正负样本分开。当然有多条不同的直线,可以把正样本和负样本完全分开。
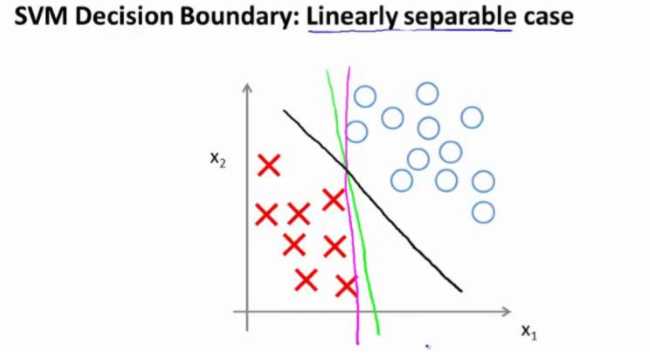
比如,这就是一个决策边界可以把正样本和负样本分开。但是多多少少这个看起来并不是非常自然是么?
中间黑线有更大的距离,这个距离叫做间距 (margin),这样就可以最优的边界了。
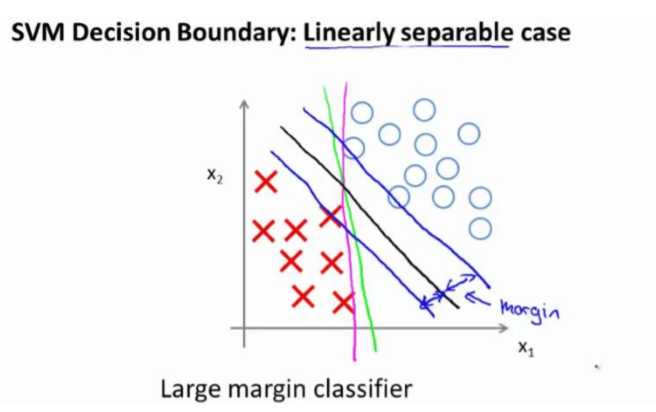
当画出这两条额外的蓝线,我们看到黑色的决策界和训练样本之间有更大的最短距离。然而粉线和蓝线离训练样本就非常近,在分离样本的时候就会比黑线表现差。
因此支持向量机有时被称为大间距分类器,而这其实是求解上一页幻灯片上优化问题的结果。 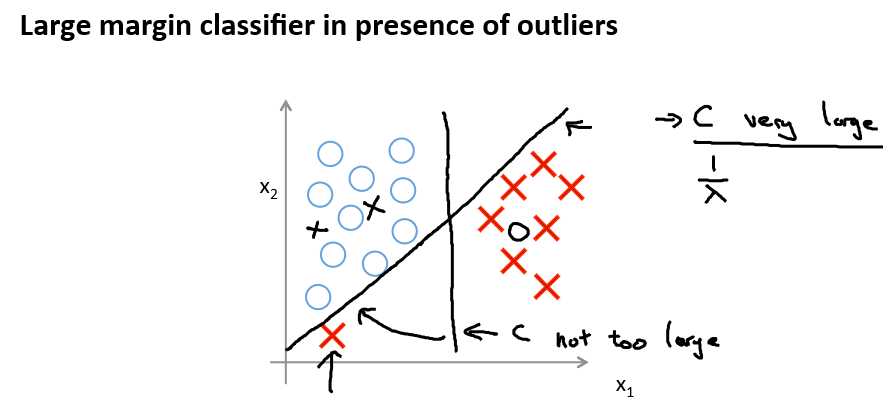
回顾 C=1/λ,因此:
C 较大时,相当于 λ 较小,可能会导致过拟合,高方差。
C 较小时,相当于 λ 较大,可能会导致低拟合,高偏差。
The mathematics behind large margin classi?cation (optional)
下图是关于內积的标示图:
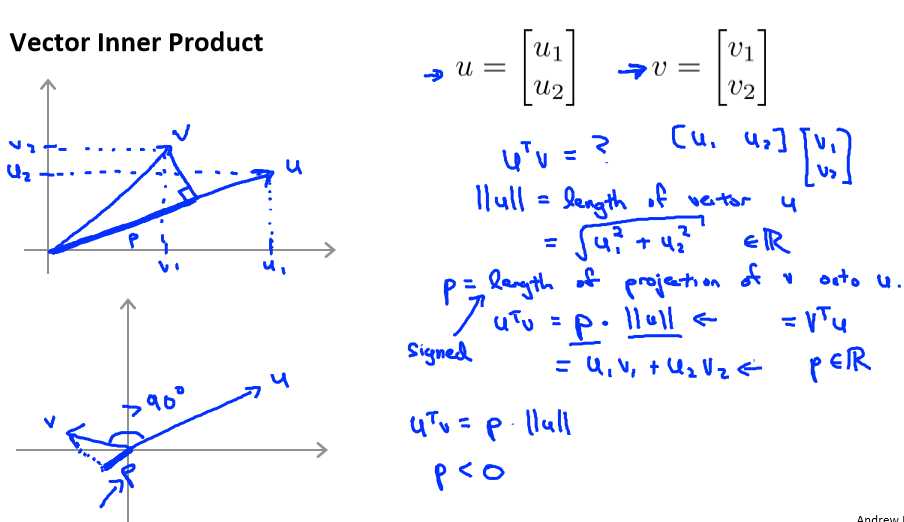
根据毕达哥拉斯定理: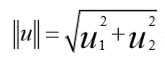 ,这是向量μ的长度,它是一个实数。
,这是向量μ的长度,它是一个实数。
接下来将会使用这些关于向量内积的性质试图来理解支持向量机中的目标函数。

这就是我们先前给出的支持向量机模型中的目标函数。为了讲解方便,我做一点简化,仅仅是为了让目标函数更容易被分析。
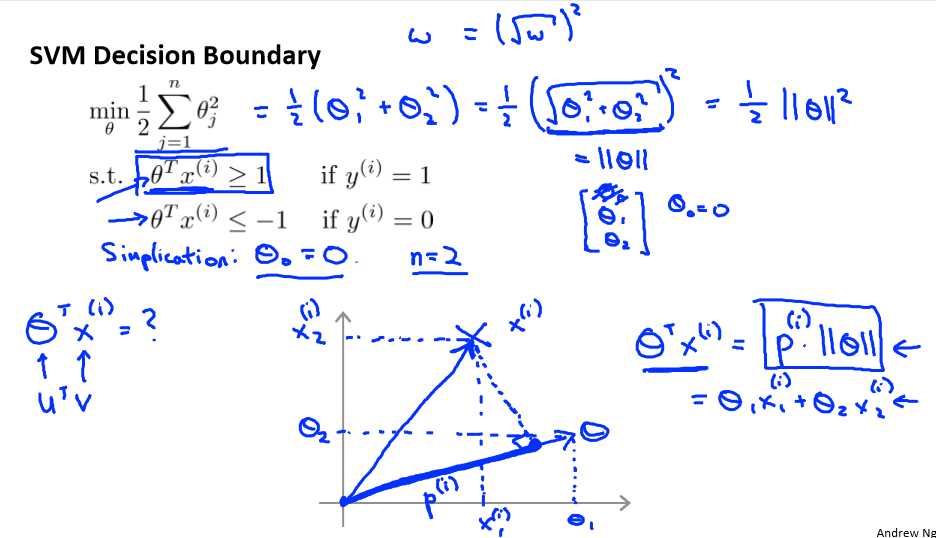
我接下来忽略掉截距,令θ0 = 0,这样更容易画示意图。我将特征数 n 置为 2,因此我们仅有两个特征 x1和 x2,现在 我们来看一下目标函数,支持向量机的优化目标函数。当我
们仅有两个特征,即 n=2 时,这个式子可以写作:
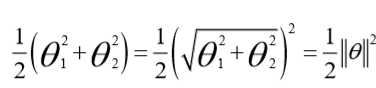
我们只有两个参数θ1 和θ2。你可能注意到括号里面的这一项是向量θ的范数,或者说是向量θ的长度。我的意思是如果我们将向量θ写出来,那么我刚刚画红线的这一项就是向量θ的长度或范数。这里我们用的是之前学过的向量范数的定义事实上这就等于向量θ的长度。
因此在我们接下来的推导中去掉θ0 不会有影响这意味着我们的目标函数是等于½||θ||2。因此支持向量机做的全部事情就是极小化参数向量θ范数的平方或者说长度的平方。
Kernels I
可以用高级数的多项式模型来解决无法用直线进行分隔的分类问题:
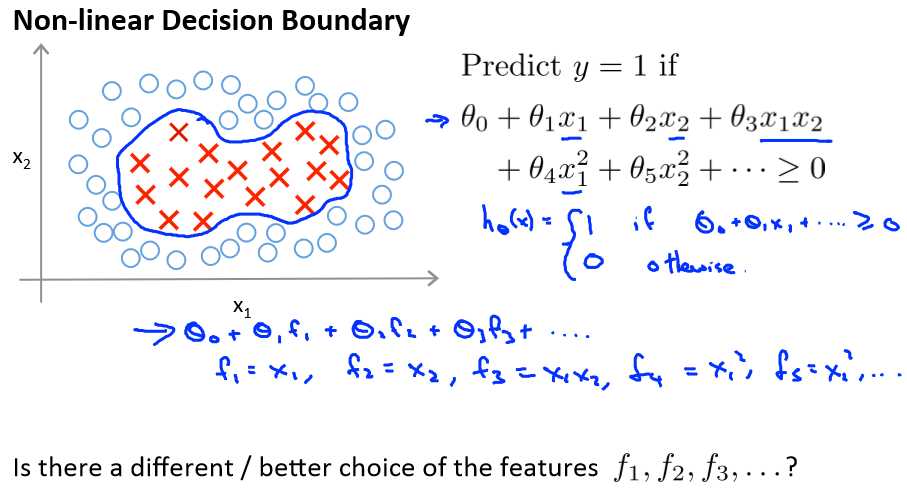
给定一个训练实例x,我们利用x的各个特征与我们预先选定的地标(landmarks) l(1),l(2),l(3)的近似程度来选取新的特征 f1,f2,f3。
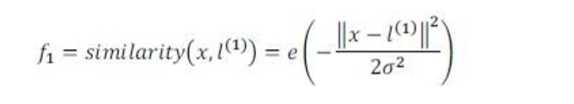
其中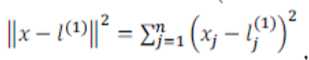
使用内核的规则如下:

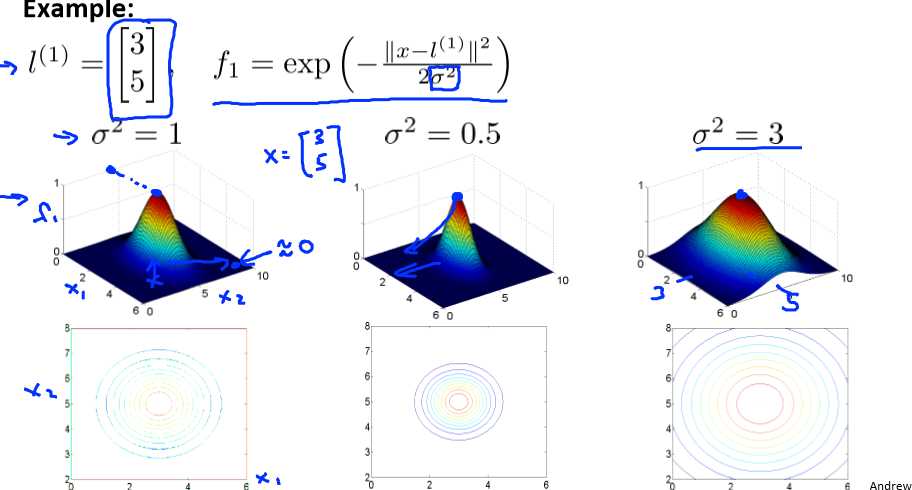
这里是一个高斯核函数(Gaussian Kernel)。 注:这个函数与正态分布没什么实际上的关系,只是看上去像而已。 
例如:

Kernels II
我们通常是根据训练集的数量选择地标的数量,即如果训练集中有 m 个实例,则我们选取 m 个地标,并且令: l(1)=x(1),l(2)=x(2),...,l(m)=x(m)。这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的,即:
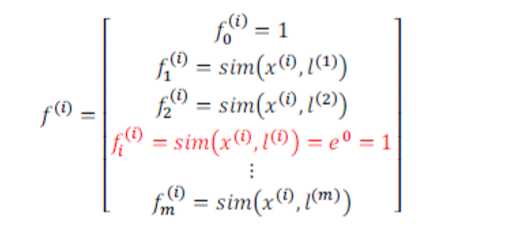
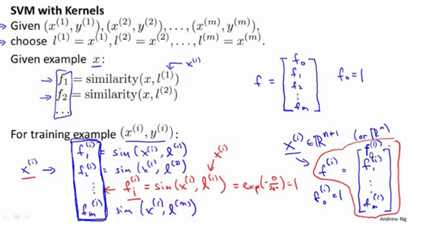
下面我们将核函数运用到支持向量机中,修改我们的支持向量机假设为:
给定 x,计算新特征 f,当 θTf>=0 时,预测 y=1,否则反之。 相应地修改代价函数为:
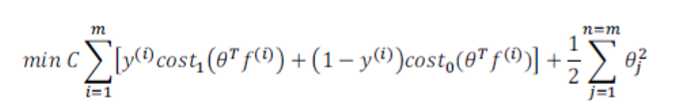
在具体实施过程中,我们还需要对最后的归一化项进行些微调整,在计算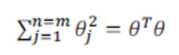 时,我们用 θTMθ 代替 θTθ,其中 M 是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
时,我们用 θTMθ 代替 θTθ,其中 M 是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel), 当我们不采用非常复杂的函数,或者我们的训练集特征非常多而实例非常少的时候,可以采用这种不带核函数的支持向量机。
下面是支持向量机的两个参数 C 和 σ 的影响:
C 较大时,相当于 λ 较小,可能会导致过拟合,高方差
C 较小时,相当于 λ 较大,可能会导致低拟合,高偏差
σ 较大时,导致高方差
σ 较小时,导致高偏差 
Using an SVM

在高斯核函数之外我们还有其他一些选择,如:
多项式核函数(Polynomial Kernel)
字符串核函数(String kernel)
卡方核函数( chi-square kernel)
直方图交集核函数(histogram intersection kernel)

多类分类问题 :
假设我们利用之前介绍的一对多方法来解决一个多类分类问题。如果一共有 k 个类,则我们需要 k 个模型,以及 k 个参数向量 θ。我们同样也可以训练 k 个支持向量机来解决多类
分类问题。但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。
尽管你不去写你自己的 SVM(支持向量机)的优化软件,但是你也需要做几件事:
1、是提出参数 C 的选择。我们在之前的视频中讨论过误差/方差在这方面的性质。
2、你也需要选择内核参数或你想要使用的相似函数,其中一个选择是:我们选择不需要任何内核参数,没有内核参数的理念,也叫线性核函数。因此,如果有人说他使用了线性
核的 SVM(支持向量机),这就意味这他使用了不带有核函数的 SVM(支持向量机)。

下面是一些普遍使用的准则:
n 为特征数,m 为训练样本数。
(1)如果相较于 m 而言,n 要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果 n 较小,而且 m 大小中等,例如 n 在 1-1000 之间,而 m 在 10-10000 之间,使用高斯核函数的支持向量机。
(3)如果 n 较小,而 m 较大,例如 n 在 1-1000 之间,而 m 大于 50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向
量机。 