本来继List的整理后会继续Collection下面的另一个分支Set的,但是看了下HashSet的实现是基于HashMap的,所以先从Map着手,然后在整理Set的
环境JDK8
一、存储原理
1、HashMap的存储
我们先来看看HashMap的部分实现源码:


static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f; static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64; transient Node<K,V>[] table; transient Set<Map.Entry<K,V>> entrySet; transient int size; transient int modCount; int threshold; final float loadFactor;
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }
通过成员变量以及HashMap的内部类Node,我们不难发现其存储主体是具有类似链表结构的Node和Node数组table
为了更形象的了解数据结构,我们先来看看HashMap存储的数据结构图(如果链表大小超过8,那么链表会刷新成二叉树的形式,Hashtable就没有这种待遇):
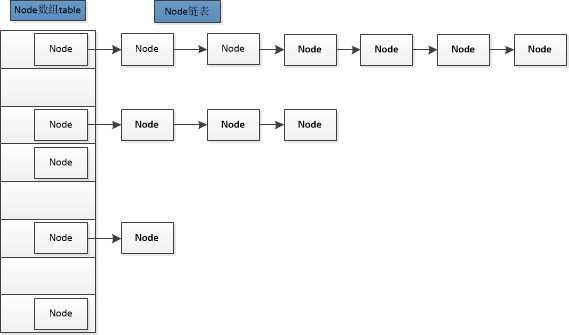
HashMap相当于结合了数组与链表的数据结构,我们成为哈希表,在Map进行put操作增加数据的时候,会根据key值的hashCode以及table(数组)大小的余数来决定新的数据应该存储在哪个数组项目里面,并且对该数组项里面的链表数据一一比较,如果有相同key的那么记性value更新,如果没有相同key的那么在链表的末尾加上新的数据。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的容量。
2、Hashtable的存储
下面是Hashtable的部分实现源码
private transient Entry<?,?>[] table; private transient int count; private int threshold; private float loadFactor; private transient int modCount = 0;
private static class Entry<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } @SuppressWarnings("unchecked") protected Object clone() { return new Entry<>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } public K getKey() { return key; } public V getValue() { return value; } public V setValue(V value) { if (value == null) throw new NullPointerException(); V oldValue = this.value; this.value = value; return oldValue; } public boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode() { return hash ^ Objects.hashCode(value); } public String toString() { return key.toString()+"="+value.toString(); } }
不难看出,除了部分参数外Hashtable的数据存储结构跟HashMap的基本无差别,都是由具有链表结构特性的内部类Entry和Entry数组table组成的。那么这两种存储结构究竟有什么不同的地方呢,我们来分析具体的方法实现
二、功能实现分析
1、put(K key, V value)的实现
(1)HashMap的put实现代码解析
public V put(K key, V value) { return putVal(hash(key), key, value, false, true);//在进行处理前先对key进行二次hash处理保证hash值的离散性 } static final int hash(Object key) {//二次哈希处理 int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0)//如果初始的数组table没有初始化或者没有容量那么进行resize()设置默认的table容量 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null)//通过位与运算确定该数据应该在哪个数组项进行存储,这个数组项如果没有Node数据那么就只接构造Node对象,然后赋值table的该数组项。 tab[i] = newNode(hash, key, value, null);//构造node并且直接赋值数组项 else {//以下是对当存储的数组项有Node的时候的判断处理 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;//数组项里的Node的key跟目标的key一致(key和hashCode都相等)那么直接对Node进行value的更改,对e.value的更改在后面进行。 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//?这里对TreeNode进行了一个判断,目前不明用途,后续如果有用到在进行解析 else {//以下是对数组项有Node并且该Node与目标数据不一致时的逻辑操作 for (int binCount = 0; ; ++binCount) {//循环遍历链式结构 if ((e = p.next) == null) {//下一个节点为null那么说明已经到该条链的最后一条也没有找到与目标数据一致的Node。 p.next = newNode(hash, key, value, null);//直接构造Node在链表的后面加上 if (binCount >= TREEIFY_THRESHOLD - 1) //这一步的操作甚是不解? treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break;//如果在链表遍历过程中遇到数据一致的node那么直接更改该节点的value,e会在后面统一进行value的更新。 p = e; } } if (e != null) { // V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value;//对e的value进行更新。 afterNodeAccess(e);//空方法 return oldValue; } } ++modCount; if (++size > threshold) resize();//当HashMap存储的数据大于阈值的时候对HashMap重新设置数组大小,并且重新构造哈希表数据,resize方法里面有对table进行新的赋值。 afterNodeInsertion(evict);//空方法 return null; } final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }
上面的代码我们看出HashMap调用put的方法时,会对key进行二次Hash编码然后在通过求余数的方式获取table的数组下标位置,如果该位置无值时直接进行节点赋值,如果有位置那么通过遍历链表(或者二叉树)数据结构进行对比如果有hashCode和equals都符合的那么进行值替换,如果没有那么在末尾追加,如果判断单个列表的长度达到8那么将链表替换成二叉树,如果整个的HashMap长度超过map容器的阈值(阈值为table的大小-默认16以及加载因子factor-默认0.75的乘积),那么进行2倍扩容重新排列。如果因子值太小会造成平凡扩容影响写的性能,如果因子值过大影响查询的性能(取决于链表的大小)
(2)Hashtable的put实现代码解析
public synchronized V put(K key, V value) { if (value == null) {//确定了table里面不能存储value的值为null的 throw new NullPointerException(); } Entry<?,?> tab[] = table; int hash = key.hashCode();//直接获取hashcode编码 int index = (hash & 0x7FFFFFFF) % tab.length;//计算获取键值对存放的table位置 @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) {//对该数组项的链表机型循环遍历 if ((entry.hash == hash) && entry.key.equals(key)) {//如果hashcode和key的equals都满足那么直接进行value替换 V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index);//如果在已有的链表里没找到匹配的项,那么直接在链表后面加上新的键值对 return null; } private void addEntry(int hash, K key, V value, int index) { modCount++; Entry<?,?> tab[] = table; if (count >= threshold) {//如果hashtable中现有的数据量超过阈值,那么进行扩容 rehash();//扩容、刷新HashTable数据 tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF) % tab.length;//根据新的table.length计算键值对的分布位置下标 } @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>) tab[index]; tab[index] = new Entry<>(hash, key, value, e);//将链表的头接到新的节点的后面然后数组项引用指向新的节点 count++; } protected void rehash() { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; int newCapacity = (oldCapacity << 1) + 1;//进行2n+1的扩容 if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) return; newCapacity = MAX_ARRAY_SIZE;//这里有table最大的限制Integer.MAX_VALUE - 8 } Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++; threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);//计算新的阈值 table = newMap; for (int i = oldCapacity ; i-- > 0 ;) {//循环遍历每一个旧的键值对,重新进行计算存储到扩容后的table中 for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = (Entry<K,V>)newMap[index];//这里都是总数组项的链表头加入数据,HashMap是加在尾部 newMap[index] = e; } } }
比较明显的一个特征put方法有synchronized修饰,表明Hashtable的put方法时线程安全的,那么其获取key的hashcode也是直接获取的hashCode编码,比较固定的数组加链表形式没有HashTable的二叉树结构存储,链表加入的方式是加到头部而不是尾部,其它方式与
HashMap基本类似,甚至更简单,数组的最大长度是Integer.MAX_VALUE - 8,超过容器阈值(阈值为table的大小-默认11以及加载因子factor-默认0.75的乘积)扩容的大小是2n+1
2、get(K key)的实现
(1)HashMap的get实现代码解析
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value;//根据key获取hashCode然后再遍历node } final Node<K,V> getNode(int hash, Object key) {//hashcode相等并且equals结果相等 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 &&//数组列表存在 (first = tab[(n - 1) & hash]) != null) {//获取key所在的数组项 if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first;//如果数组项的第一个node就符合判断条件那么直接返回该node if ((e = first.next) != null) {//继续取下一个node if (first instanceof TreeNode)//判断TreeNode分支,并且根据treenode的结构获取对应的节点 return ((TreeNode<K,V>)first).getTreeNode(hash, key); do {//对于链表式的节点依次往后遍历,对比获取node if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
get的实现思路相对比较清晰,先对key进行二次hashcode编码,然后计算出键值对应该所处的数组项,剩下的就是对链表或者二叉树进行遍历对比找出节点(对比依据key的二次hashcode编码一致,equals结果一致)
(2)Hashtable
public synchronized V get(Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;//获取所在数组项的下标 for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {//遍历判断找到key对应的节点 if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value; } } return null; }
思路跟HashMap类似,获取编码,计算下标,遍历链表进行对比找出节点。
3、remove(Object key)的实现
(1)HashMap的remove实现代码解析
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {//在这里获取key的节点坐在的数组项 Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p;//判断第一个节点就是目标值时直接进行后面的移除操作 else if ((e = p.next) != null) { if (p instanceof TreeNode)//判断如果是treeNode那么调用TreeNode的getTreeNode方法,找到这个目标节点 node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else {//否则的话进行链表循环遍历找到目标节点 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {//如果是remove obj的那么这里会对value做个判断 if (node instanceof TreeNode)//如果是treenode节点那么直接调用TreeNode的remove方法 ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p)//如果数组项的第一个就是目标节点,那么直接进行操作删除--P是第一个节点 tab[index] = node.next; else p.next = node.next;//否则用上一个节点的next直接指向目标节点的next达到删除目标节点的目的 ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }
代码分析很容易判断,这就是put的一个逆向过程,不过有一点是不可逆的,也就是二叉树不管后面remove到大小是多少(除非该数组项为null),都不会逆向转换为link的链表结构。
//该方法就是对二叉树的节点进行删除,从实现逻辑上判断不管该数组项的这数据结构的模式是否小于8,都不会回复链式结构,也就是说链式结构——》二叉树结构是不可逆的,除非这个数组项的节点删除完毕在重新add final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab, boolean movable) { int n; if (tab == null || (n = tab.length) == 0) return; int index = (n - 1) & hash; TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl; TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev; if (pred == null) tab[index] = first = succ; else pred.next = succ; if (succ != null) succ.prev = pred; if (first == null) return; if (root.parent != null) root = root.root(); if (root == null || root.right == null || (rl = root.left) == null || rl.left == null) { tab[index] = first.untreeify(map); // too small return; } TreeNode<K,V> p = this, pl = left, pr = right, replacement; if (pl != null && pr != null) { TreeNode<K,V> s = pr, sl; while ((sl = s.left) != null) // find successor s = sl; boolean c = s.red; s.red = p.red; p.red = c; // swap colors TreeNode<K,V> sr = s.right; TreeNode<K,V> pp = p.parent; if (s == pr) { // p was s‘s direct parent p.parent = s; s.right = p; } else { TreeNode<K,V> sp = s.parent; if ((p.parent = sp) != null) { if (s == sp.left) sp.left = p; else sp.right = p; } if ((s.right = pr) != null) pr.parent = s; } p.left = null; if ((p.right = sr) != null) sr.parent = p; if ((s.left = pl) != null) pl.parent = s; if ((s.parent = pp) == null) root = s; else if (p == pp.left) pp.left = s; else pp.right = s; if (sr != null) replacement = sr; else replacement = p; } else if (pl != null) replacement = pl; else if (pr != null) replacement = pr; else replacement = p; if (replacement != p) { TreeNode<K,V> pp = replacement.parent = p.parent; if (pp == null) root = replacement; else if (p == pp.left) pp.left = replacement; else pp.right = replacement; p.left = p.right = p.parent = null; } TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement); if (replacement == p) { // detach TreeNode<K,V> pp = p.parent; p.parent = null; if (pp != null) { if (p == pp.left) pp.left = null; else if (p == pp.right) pp.right = null; } } if (movable) moveRootToFront(tab, r); }
(2)Hashtable的remove实现代码解析
public synchronized V remove(Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode();// int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>)tab[index]; for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) { if ((e.hash == hash) && e.key.equals(key)) {//hashcode和key的equals双重判断定位目标节点 modCount++;//执行链表删除 if (prev != null) { prev.next = e.next; } else { tab[index] = e.next; } count--; V oldValue = e.value; e.value = null; return oldValue; } } return null; }
比较简单的直接计算获取数组项,然后进行链表遍历找到目标节点后进行节点删除操作
4、Iterator遍历实现
我们知道Map接口还有一个比较重要的功能就是iterator关于遍历的实现,主要有三种途径entrySet().iterator()、keySet().iterator()、values().iterator()的方式,下面我们来看下具体的实现
(1)HashMap的实现
entrySet部分代码
public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new EntrySet()) : es; } final class EntrySet extends AbstractSet<Map.Entry<K,V>> { public final int size() { return size; } public final void clear() { HashMap.this.clear(); } public final Iterator<Map.Entry<K,V>> iterator() { return new EntryIterator(); } public final boolean contains(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Node<K,V> candidate = getNode(hash(key), key); return candidate != null && candidate.equals(e); } public final boolean remove(Object o) { if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Object value = e.getValue(); return removeNode(hash(key), key, value, true, true) != null; } return false; } public final Spliterator<Map.Entry<K,V>> spliterator() { return new EntrySpliterator<>(HashMap.this, 0, -1, 0, 0); } public final void forEach(Consumer<? super Map.Entry<K,V>> action) { Node<K,V>[] tab; if (action == null) throw new NullPointerException(); if (size > 0 && (tab = table) != null) { int mc = modCount; for (int i = 0; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null; e = e.next) action.accept(e); } if (modCount != mc) throw new ConcurrentModificationException(); } } }
keySet部分代码
public Set<K> keySet() { Set<K> ks = keySet; if (ks == null) { ks = new KeySet(); keySet = ks; } return ks; } final class KeySet extends AbstractSet<K> { public final int size() { return size; } public final void clear() { HashMap.this.clear(); } public final Iterator<K> iterator() { return new KeyIterator(); } public final boolean contains(Object o) { return containsKey(o); } public final boolean remove(Object key) { return removeNode(hash(key), key, null, false, true) != null; } public final Spliterator<K> spliterator() { return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0); } public final void forEach(Consumer<? super K> action) { Node<K,V>[] tab; if (action == null) throw new NullPointerException(); if (size > 0 && (tab = table) != null) { int mc = modCount; for (int i = 0; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null; e = e.next) action.accept(e.key); } if (modCount != mc) throw new ConcurrentModificationException(); } } }
values部分代码
public Collection<V> values() { Collection<V> vs = values; if (vs == null) { vs = new Values(); values = vs; } return vs; } final class Values extends AbstractCollection<V> { public final int size() { return size; } public final void clear() { HashMap.this.clear(); } public final Iterator<V> iterator() { return new ValueIterator(); } public final boolean contains(Object o) { return containsValue(o); } public final Spliterator<V> spliterator() { return new ValueSpliterator<>(HashMap.this, 0, -1, 0, 0); } public final void forEach(Consumer<? super V> action) { Node<K,V>[] tab; if (action == null) throw new NullPointerException(); if (size > 0 && (tab = table) != null) { int mc = modCount; for (int i = 0; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null; e = e.next) action.accept(e.value); } if (modCount != mc) throw new ConcurrentModificationException(); } } }
上面的三部分代码表明entrySet、keySet、values都返回了一个继承了AbstractCollection的抽象类(AbstractSet也是继承了AbstractCollection的抽象类)
iterator代码
final class KeyIterator extends HashIterator implements Iterator<K> { public final K next() { return nextNode().key; } } final class ValueIterator extends HashIterator implements Iterator<V> { public final V next() { return nextNode().value; } } final class EntryIterator extends HashIterator implements Iterator<Map.Entry<K,V>> { public final Map.Entry<K,V> next() { return nextNode(); } }
获取iterator的过程都是通过共同的HashIterator.nextNode方法获取的,不同的是entrySet返回的是node节点,而另外的两个分别返回的是key以及value
HashInerator类
abstract class HashIterator { Node<K,V> next; // next entry to return Node<K,V> current; // current entry int expectedModCount; // for fast-fail int index; // current slot HashIterator() { expectedModCount = modCount; Node<K,V>[] t = table; current = next = null; index = 0; if (t != null && size > 0) { // advance to first entry do {} while (index < t.length && (next = t[index++]) == null); } } public final boolean hasNext() { return next != null; } final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; } public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false); expectedModCount = modCount; } }
nextNode的操作基于对HashMap中数组链表的数据结构进行遍历实时获取的当前节点
(2)Hashtable的实现
entrySet部分代码实现
public Set<Map.Entry<K,V>> entrySet() { if (entrySet==null) entrySet = Collections.synchronizedSet(new EntrySet(), this); return entrySet; } private class EntrySet extends AbstractSet<Map.Entry<K,V>> { public Iterator<Map.Entry<K,V>> iterator() { return getIterator(ENTRIES); } public boolean add(Map.Entry<K,V> o) { return super.add(o); } public boolean contains(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> entry = (Map.Entry<?,?>)o; Object key = entry.getKey(); Entry<?,?>[] tab = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<?,?> e = tab[index]; e != null; e = e.next) if (e.hash==hash && e.equals(entry)) return true; return false; } public boolean remove(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> entry = (Map.Entry<?,?>) o; Object key = entry.getKey(); Entry<?,?>[] tab = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>)tab[index]; for(Entry<K,V> prev = null; e != null; prev = e, e = e.next) { if (e.hash==hash && e.equals(entry)) { modCount++; if (prev != null) prev.next = e.next; else tab[index] = e.next; count--; e.value = null; return true; } } return false; } public int size() { return count; } public void clear() { Hashtable.this.clear(); } }
keySet部分代码实现
public Set<K> keySet() { if (keySet == null) keySet = Collections.synchronizedSet(new KeySet(), this); return keySet; } private class KeySet extends AbstractSet<K> { public Iterator<K> iterator() { return getIterator(KEYS); } public int size() { return count; } public boolean contains(Object o) { return containsKey(o); } public boolean remove(Object o) { return Hashtable.this.remove(o) != null; } public void clear() { Hashtable.this.clear(); } }
values部分代码实现
public Collection<V> values() { if (values==null) values = Collections.synchronizedCollection(new ValueCollection(), this); return values; } private class ValueCollection extends AbstractCollection<V> { public Iterator<V> iterator() { return getIterator(VALUES); } public int size() { return count; } public boolean contains(Object o) { return containsValue(o); } public void clear() { Hashtable.this.clear(); } }
iterator代码
private <T> Iterator<T> getIterator(int type) { if (count == 0) { return Collections.emptyIterator(); } else { return new Enumerator<>(type, true); } }
从Enumerator<>(type, true)可以看出这还是一种比较老的实现,目前还无法跟踪,大致的设计思路跟HashMap是一致的,因为Hashtable目前使用的并不多,多线程的一般使用ConcurrentHashMap(线程安全),在这里不深入研究,以后有机会找到资料再看。
小结:
通过以上各个常用功能的实现代码分析,我们对比了HashMap与HashTable得出如下结论
1、HashTable的对外相关的方法都有用synchronized进行修饰,是线程安全的,而HashMap不是,但是方法级别的synchronized必定导致HashTable在多线程运行时的性能问题。
2、HashMap的初始化数组大小是16,并且扩容是2n增长,Hashtable的初始化数组大小是11,扩容是2n+1的增长
3、key的hashCode方式两者也不一样,Hashtable直接去key的hashCode,而HashMap中对key进行了两次hash编码,这样做应该是在计算table数组下标位置的时候能够使存储位置分布的更均匀,可以提高HashMap的性能。
4、当一个数组项里面的链表数量超过8时,HashMap会将链表转换为二叉树的存储结构,但是Hashtable一致是链表结构
三、性能测试验证
不用质疑,在性能上面HashMap肯定比Hashtable要优越的多,不管是从数据存储结构或者是散列分布算法HashMap都有进行过优化,至于线程安全问题java api为我们提供了性能更优越的ConcurrentHashMap等类(后续也会对这些类进行分析),那么我们需要验证性能的方面就要从HashMap本身实现的功能使用上进行分析了,比如HashMap的遍历方式、初始容量以及阈值因子的设置对性能影响等。那么这块我们还是放在后面进行实例测试验证。