前面我们用Tensorboard显示了tensorflow的程序结构,本节主要用Tensorboard显示各个参数值的变化以及损失函数的值的变化。
这里的核心函数有:
histogram
例如:
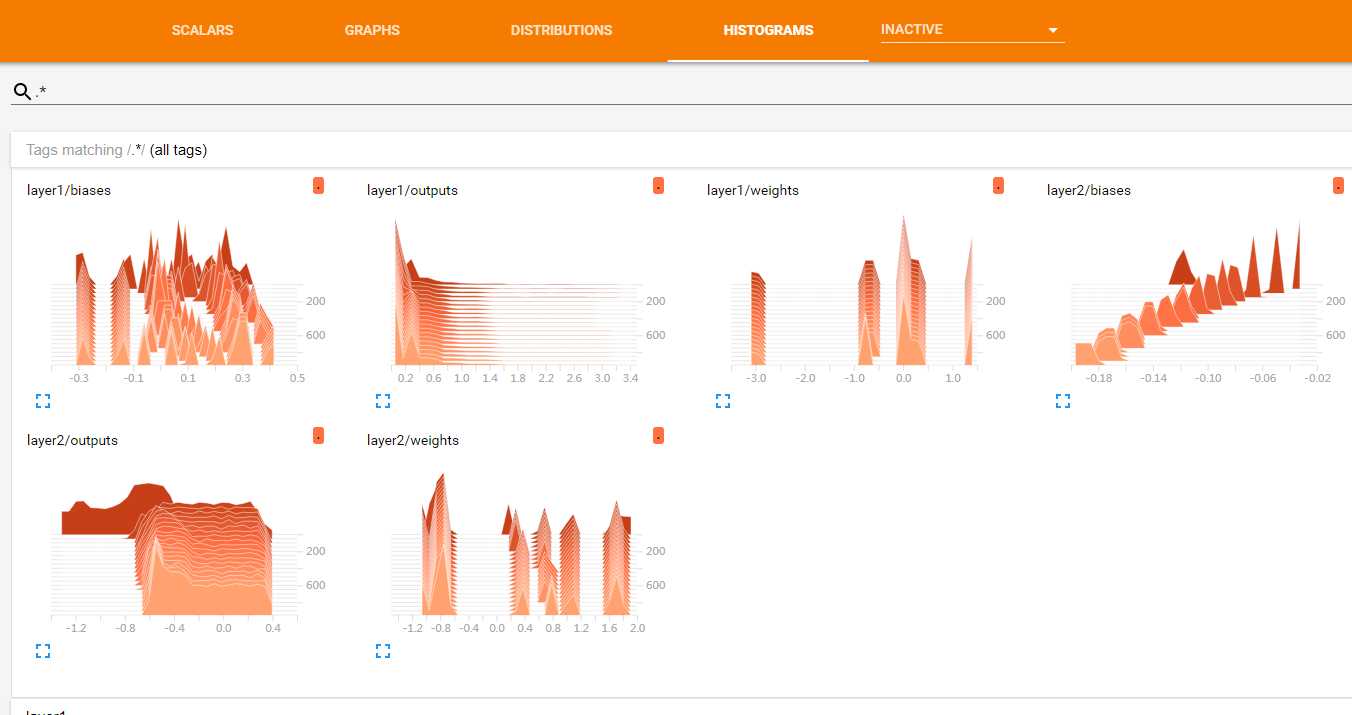
tf.summary.histogram(layer_name + "/weights", Weights)这里用tf.summary.histogram函数来显示二维数据在不同网络层的变化情况,其中第一个参数是名字,可以用/来进行分层显示,第二个参数就是相应变量的值。
scalar
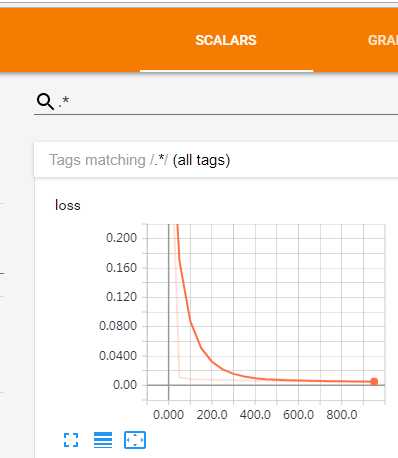
tf.summary.scalar(‘loss‘, loss)用scalar来显示单个值。
尽管是单个值,但因为会在不同的循环下有不同的值,因此还是会有一系列的点组成的曲线,在这里可以查看损失值是否在逐步递减。
这样我们就不需要用matplot来额外地画图了。
merge all & writer
要把所有的summary合并在一起并在适当的时候进行输出:
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("E:/todel/data/tensorflow", sess.graph)最后在训练循环中进行输出:
result = sess.run(merged, feed_dict={xs:x_data, ys:y_data})
writer.add_summary(result, i)完整的代码
import tensorflow as tf
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, n_layer, activation_function=None):
"""
添加层
:param inputs: 输入数据
:param in_size: 输入数据的列数
:param out_size: 输出数据的列数
:param activation_function: 激励函数
:return:
"""
layer_name = ‘layer%s‘ % n_layer
# 定义权重,初始时使用随机变量,可以简单理解为在进行梯度下降时的随机初始点,这个随机初始点要比0值好,因为如果是0值的话,反复计算就一直是固定在0中,导致可能下降不到其它位置去。
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
tf.summary.histogram(layer_name + "/weights", Weights)
# 偏置shape为1行out_size列
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
tf.summary.histogram(layer_name + "/biases", biases)
# 建立神经网络线性公式:inputs * Weights + biases,我们大脑中的神经元的传递基本上也是类似这样的线性公式,这里的权重就是每个神经元传递某信号的强弱系数,偏置值是指这个神经元的原先所拥有的电位高低值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
# 如果没有设置激活函数,则直接就把当前信号原封不动地传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则会由此激活函数来对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name + "/outputs", outputs)
return outputs
import numpy as np
# 创建一列(相当于只有一个属性值),300行的x值,这里np.newaxis用于新建出列数据,使其shape为(300, 1)
x_data = np.linspace(-1, 1, 300)[:,np.newaxis]
# 增加噪点,噪点的均值为0,标准差为0.05,形状跟x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
# 定义y的函数为二次曲线的函数,但同时增加了一些噪点数据
y_data = np.square(x_data) - 0.5 + noise
# 定义输入值,这里定义输入值的目的是为了能够使程序比较灵活,可以在神经网络启动时接收不同的实际输入值,这里输入的结构为输入的行数不国定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1], name=‘x_input‘)
ys = tf.placeholder(tf.float32, [None, 1], name=‘y_input‘)
# 定义一个隐藏层,输入为xs,输入size为1列,因为x_data就只有1个属性值,输出size我们假定输出的神经元有10个神经元的隐藏层,激励函数用relu
l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu)
# 定义输出层,输入为l1,输入size为10列,也就是l1的列数,输出size为1,因为这里直接输出为类似y_data了,因此为1列,假定没有激励函数,也就是输出是啥就直接传递出去了。
predition = add_layer(l1, 10, 1, n_layer=2, activation_function=None)
# 定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - predition), axis=1))
tf.summary.scalar(‘loss‘, loss)
# 进行逐步优化的梯度下降优化器,学习效率为0.1,以最小化损失函数的方式进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化所有定义的变量
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("E:/todel/data/tensorflow", sess.graph)
# 学习1000次
for i in range(1000):
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
# 打印期间的误差值,看这个误差值是否在减少
if i % 50 == 0:
result = sess.run(merged, feed_dict={xs:x_data, ys:y_data})
writer.add_summary(result, i)最后在相应的目录下输入如下的命令显示Tensorboard中的图形:
tensorboard --logdir tensorflow显示的图形为: