zookeeper介绍
ZooKeeper的工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
选主流程
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。先介绍basic paxos流程:
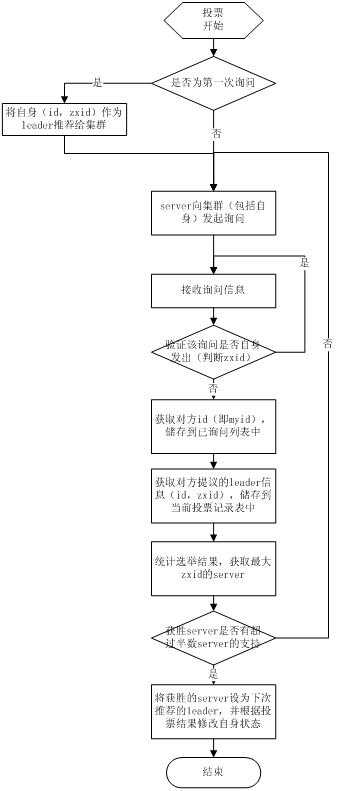
1 .选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2 .选举线程首先向所有Server发起一次询问(包括自己);
3 .选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4. 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5. 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图如下所示:
同步流程
选完leader以后,zk就进入状态同步过程。
1. leader等待server连接;
2 .Follower连接leader,将最大的zxid发送给leader;
3 .Leader根据follower的zxid确定同步点;
4 .完成同步后通知follower 已经成为uptodate状态;
5 .Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。

工作流程
Leader主要有三个功能:
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。
Follower工作流程
1. 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2 .接收Leader消息并进行处理;
3 .接收Client的请求,如果为写请求,发送给Leader进行投票;
4 .返回Client结果。
Follower的消息循环处理如下几种来自Leader的消息:
1 .PING消息: 心跳消息;
2 .PROPOSAL消息:Leader发起的提案,要求Follower投票;
3 .COMMIT消息:服务器端最新一次提案的信息;
4 .UPTODATE消息:表明同步完成;
5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
集群安装
ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以Standalone模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
ZooKeeper集群的配置
1、软件环境
192.168.16.70 server1
192.168.16.73 server2
192.168.16.74 server3
Linux服务器一台、三台、五台、(2*n+1),Zookeeper集群的工作是超过半数才能对外提供服务,3台中超过两台超过半数,允许1台挂掉 ,是否可以用偶数,其实没必要。
如果有四台那么挂掉一台还剩下三台服务器,如果在挂掉一个就不行了,这里记住是超过半数。
Java jdk1.7 zookeeper是用java写的所以他的需要JAVA环境,java是运行在java虚拟机上的
Zookeeper的稳定版本Zookeeper 3.4.6版本
2、配置&安装Zookeeper
下面的操作是:3台服务器统一操作
1、安装Java yum list java* yum -y install java-1.7.0-openjdk* 2、创建目录并下载Zookeeper(目录自定义) mkdir zookeeper #项目目录 mkdir zkdata #存放快照日志 mkdir zkdatalog #存放事物日志 #下载软件 wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz #解压软件 tar -zxvf zookeeper-3.4.6.tar.gz
3、修改配置文件
#进入conf目录
/root/zookeeper-3.4.6/conf
#zoo_sample.cfg 这个文件是官方给我们的zookeeper的样板文件,给他复制一份命名为zoo.cfg,zoo.cfg是官方指定的文件命名规则。
3台服务器的配置文件(zoo.cfg)
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/root/zkdata dataLogDir=/root/zkdatalog clientPort=12181 server.1=192.168.16.70:12888:13888 #server.1 这个1是服务器的标识也可以是其他的数字,表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里 server.2=192.168.16.73:12888:13888 server.3=192.168.16.74:12888:13888 #192.168.16.74为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
配置文件解析:
#tickTime: 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
#initLimit: 这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
#syncLimit: 这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒
#dataDir: 快照日志的存储路径
#dataLogDir: 事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影 响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
#clientPort: 这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。修改他的端口改大点
创建myid文件
#server1 echo "1" > /opt/zookeeper/zkdata/myid
#server2 echo "2" > /opt/zookeeper/zkdata/myid
#server3 echo "3" > /opt/zookeeper/zkdata/myid
4、重要配置说明
1、myid文件和server.myid 在快照目录下存放的标识本台服务器的文件,他是整个zk集群用来发现彼此的一个重要标识。
2、zoo.cfg 文件是zookeeper配置文件 在conf目录里。
3、log4j.properties文件是zk的日志输出文件 在conf目录里用java写的程序基本上有个共同点日志都用log4j,来进行管理。
configuration for log4j
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, CONSOLE #日志级别
zookeeper.console.threshold=INFO #使用下面的console来打印日志
zookeeper.log.dir=. #日志打印到那里,是咱们启动zookeeper的目录 (建议设置统一的日志目录路径)
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "<default threshold> (, <appender>)+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
#log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j‘s NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
4、zkEnv.sh和zkServer.sh文件
zkServer.sh 主的管理程序文件
zkEnv.sh 是主要配置,zookeeper集群启动时配置环境变量的文件
5、还有一个需要注意
zookeeper不会主动的清除旧的快照和日志文件,但是可以通过命令去定期的清理。
#!/bin/bash #snapshot file dir dataDir=/opt/zookeeper/zkdata/version-2 #tran log dir dataLogDir=/opt/zookeeper/zkdatalog/version-2 #Leave 66 files count=66 count=$[$count+1] ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
#以上这个脚本定义了删除对应两个目录中的文件,保留最新的66个文件,可以将他写到crontab中,设置为每天凌晨2点执行一次就可以了。
从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。
这两个参数都是在zoo.cfg中配置的:
autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
5、启动服务并查看
1、启动服务
#进入到Zookeeper的bin目录下 cd /opt/zookeeper/zookeeper-3.4.6/bin #启动服务(3台都需要操作) ./zkServer.sh start (start-foreground 命令可将启动日志打印到屏幕)
2、检查服务状态
./zkServer.sh status
通过status就能看到状态: ./zkServer.sh status JMX enabled by default Using config: /opt/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg #配置文件 Mode: follower #他是否为领导
zk集群一般只有一个leader,多个follower,主一般是相应客户端的读写请求,而从主同步数据,当主挂掉之后就会从follower里投票选举一个leader出来。可以用“jps”查看zk的进程,这个是zk的整个工程的main
#执行命令jps
20348 Jps
4233 QuorumPeerMain