导读
本节内容介绍如何使用RNN训练语言模型,并生成新的文本序列。
语言模型(Language model)
通过语言模型,我们可以计算某个特定句子出现的概率是多少,或者说该句子属于真实句子的概率是多少。正式点讲,一个序列模型模拟了任意特定单词序列的概率。
Language modelling with an RNN
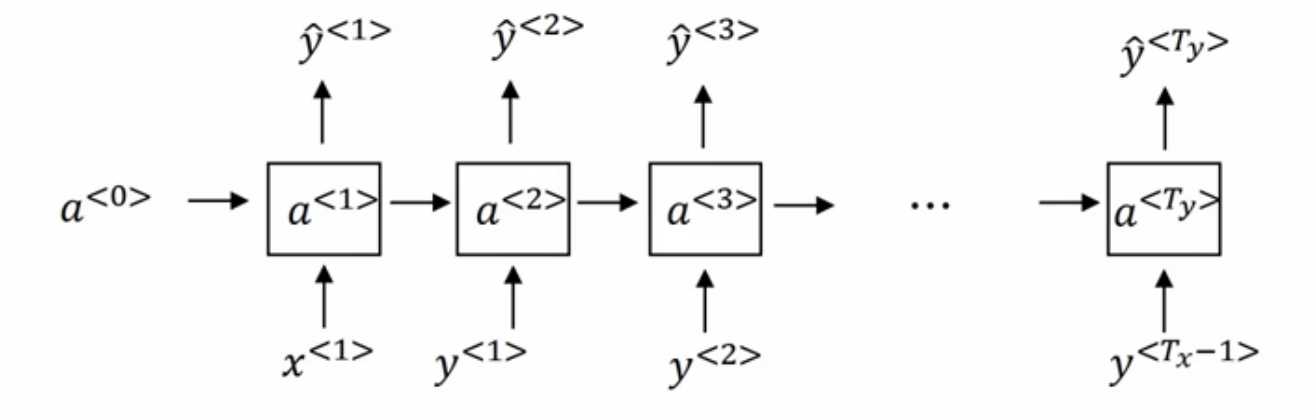
RNN中\(x^{<1>}\),\(a^{<0>}\)为零向量,而a^{<1>}通过softmax层进行预测,计算出第一个词可能是什么,其结果为\(\hat{y}^{<1>}\)。这一步其实是通过softmax层计算词典里每一个词会是第一个词的概率,假设词典有n个词,那么\(\hat{y}^{<i>}\)就是一个n维向量。然后RNN进入下个时间步,将激活值\(a^{<1>}\)传递到第二个时间步,这步要计算句子中第二个词会是什么,此时的输入为\(y^{<1>}\)(注意区分,不是\(\hat{y}^{<1>}\)),将当前训练句子中真实的第一个词作为输入,即\(x^{<2>}=y^{<1>}\),接下来同样经过softmax层得到n维向量\(\hat{y}^{<2>}\),每一维度所对应的数值,是已知第一词为\(x^{<2>}\)时第二个词是该单词(每个维度对应唯一一个单词)的概率。
以此类推,之后RNN中每个时间步的输入都是上个时间步的真实值\(x^{<i>}=y^{<i-1>}\),之后根据前\((i-1)\)个真实值\(y^{<i>}\)所包含的信息计算得到输出值\(\hat{y}^{<i>}\),一个n维向量,n是词典的大小。
RNN训练语言模型时采用的损失函数是softmax的损失函数,即交叉熵损失函数,公式如下:
\[L(\hat{y}^{<t>},y^{<t>})=-\sum_i y_i^{<t>}log \hat{y}_i^{<t>}\]
\[L = \sum_t L^{<t>}(\hat{y}^{<t>},y^{<t>}) \]
- 第一个公式中\(y\)是真实的数据分布,\(\hat{y}\)是预测的数据分布,i代表一个训练batch中的每个训练数据。
- 第二个公式将不同时刻的损失函数值累加,得到最终的损失函数。RNN在该公式的基础上进行反向传播。
现在我们已经掌握了RNN训练语言模型的具体细节,那么当模型训练完成后,我们该如何应用此模型计算某一句子出现的概率?
假设测试句子的长度为\(T_x\),将该序列作为输入,重复上述操作但不进行反向传播。最后模型可以生成\(T_x\)个输出值,对这些值执行累乘操作,便得到了该句子的概率值。