Error analysis
Carrying out error analysis
Error analysis是手动分析算法错误的过程。
通过一个例子来说明error analysis的过程。假设你在做猫图像识别的算法,它的错误率高达10%,你希望提高它的表现。
你已经有了一些改进的想法,包括:
- 算法把狗的图片错误识别为猫,需要修正;
- 算法把其他一些猫科动物(比如狮子,豹,...)错误识别为猫,需要修正;
- 算法对于比较模糊的图片容易识别错误,需要改进;
- 算法对于加了滤镜的图片容易识别错误,需要改进。
那么,究竟哪个想法是最有价值去花费时间实现的呢?我们可以通过一个表格进行error analysis,从而给我们一个直观的指导。
- 首先,从dev set中手动地找出比如约100个被错误标记的样本;
- 然后,用一个表格进行统计,在这些选出的错误样本中,各个原因导致错误的比例;
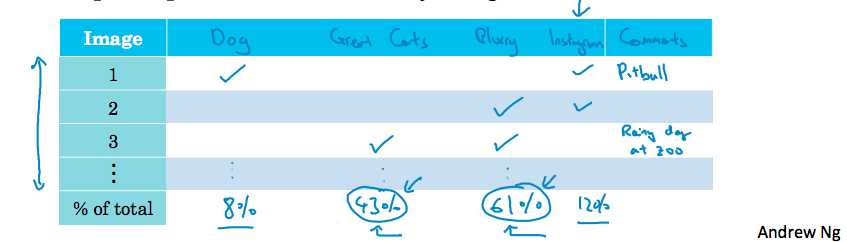
- 最后,分析下一步集中解决哪个问题可以使得准确率有最大的提升。
比如假设我们的统计结果如上表所示,那么集中解决其他猫科动物的识别或者模糊图像的问题显然更有价值,我们可以采取再去多收集一些其他猫科动物的图片加入训练集等措施。
Cleaning up incorrectly labled data
当我们发现我们使用的数据中有些被标记错误,是否需要手动一一更正呢?我们应该怎么处理?
对于training set
事实上,DL算法对于训练集中的[随机误差]有着较强的抗干扰能力。因此,如果训练集中有一些随机的错误标记,可以不用去修改不会产生什么坏的影响。需要注意的是,如果存在系统误差,比如把绝大多数白色的小狗错误标记成猫,则容易造成干扰,需要更正。
对于dev/tests set
建议在error analysis过程中,增加统计“错误标记”一项造成错误的比例。例如,我们在表格增加了“错误标记”列并且得到以下统计结果。那么我们是否需要花费精力取修改这6%的标记错误呢?
建议:需要看错误标记的问题是否影响dev/test set准确地反映算法正确性的能力。通过三个数据来判断:1.整体dev set误差;2.错误标记造成的误差;3.其他问题造成的误差。
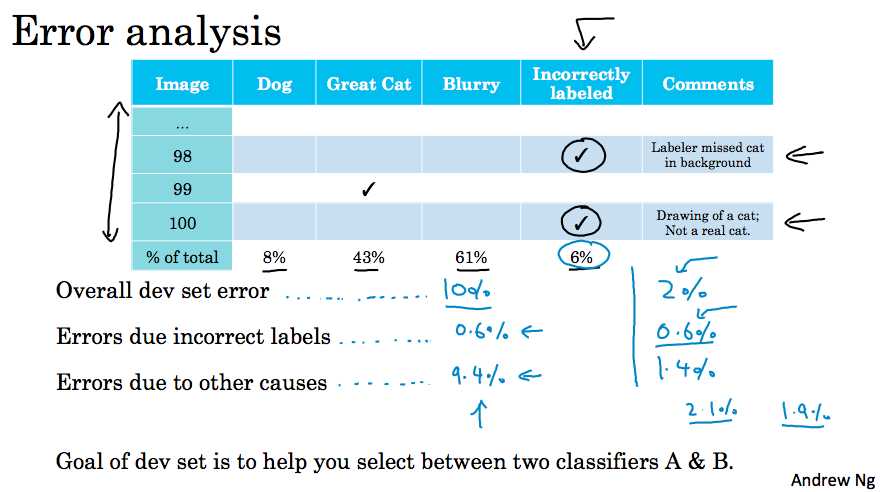
举例来说,对于左边的情况,0.6%与9.4%相比占比较少,因此可以考虑不修改;对于右边的情况,0.6%与1.4%相比占比已经比较大了,因此考虑修改。
另外还有一些其他的建议:
- 对于dev和test set始终进行同样的处理过程,以确保它们来自同样的分布。dev set进行的错误标记的更正,那么test set也应该更正。
- 可以考虑对算法判断错误的和判断正确的都进行检查,算法可能把某些本身标记错误的猫判读为猫造成正确分类的假象。但是判断错误比例一般较小,容易检查,而正确检查则较为困难。
- 训练集和dev/test set可以来自略不相同的分布。训练集一般很大,检查较困难,因此只更正dev/test set而不更正training set可能是OK的。
Bulid your first system quickly, then iterate
如果你在建立一个全新应用的ML系统,你可能一开始考虑到很多可能因素的影响,迷茫于集中解决什么,对此的建议是:首先快速建立起来第一个系统,不要考虑过多,然后再迭代改进。 不要一开始想的过于复杂,增加困难建立了过于复杂的系统。
- 设置好dev/test set和评估指标,这决定了瞄准的目标;
- 建立初步的系统(快速训练,fit参数;dev set,调整参数;test set,评价结果)
- 进行bias/variance分析和 error analysis分析来确定下一步优先解决什么问题,逐步优化。
如果你是在有一些先验经验的基础上建立ML系统,或者已经有较为完善的学术研究基础可以解决很多你建立系统的相同问题,比如人脸识别已经有很多研究基础,你可以考虑在这些基础上直接建立一个较为复杂的系统。