git诞生
同生活中的许多伟大事件一样,Git 诞生于一个极富纷争大举创新的年代。1991年,Linus创建了开源的Linux,并且有着为数众多的参与者。虽然有世界各地的志愿者为Linux编写代码,但是绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。在这期间,所有的源代码都是由Linus手工合并。因为Linus坚定地反对CVS和SVN,这些集中式的版本控制系统(集中式和分布式我们会在接下来的内容讲解)不但速度慢,而且必须联网才能使用。虽然有一些商用的版本控制系统,比CVS、SVN好用,但那是付费的,和Linux的开源精神不符。
不过,到了2002 年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是整个项目组启用了一个商业版本的分布式版本控制系统 BitKeeper 来管理和维护代码。BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。安定团结的大好局面在2005年被打破,开发BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,原因是Linux社区牛人聚集,开发Samba的Andrew试图破解BitKeeper的协议,这么干的其实也不只他一个,但是被BitMover公司发现了,于是BitMover公司收回了Linux社区的免费使用权。这就迫使Linux开源社区( 特别是Linux的缔造者 Linus Torvalds )不得不吸取教训,只有开发一套属于自己的版本控制系统才不至于重蹈覆辙。
他们对新的系统制订了若干目标:速度 、 简单的设计 、 对非线性开发模式的强力支持(允许上千个并行开发的分支)、完全分布式、有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)。自诞生于 2005 年以来,Git 日臻成熟完善,迅速成为最流行的分布式版本控制系统,在高度易用的同时,仍然保留着初期设定的目标。它的速度飞快,极其适合管理大项目,它还有着令人难以置信的非线性分支管理系统,可以应付各种复杂的项目开发需求。2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
历史就是这么偶然,如果不是当年BitMover公司威胁Linux社区,可能现在我们就没有免费而超级好用的Git了。
版本控制系统
Linus一直痛恨的CVS及SVN都是集中式的版本控制系统,而
Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢?
先说集中式版本控制系统,版本库是集中存放在中央服务器的,而大家工作的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始工作,工作完成,再把自己的修订推送给中央服务器。这类系统,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
那分布式版本控制系统与集中式版本控制系统有何不同呢?首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
GIT对象模型
SHA
所有用来表示项目历史信息的文件,是通过一个40个字符的(40-digit)“对象名”来索引的,对象名看起来像这样:
6ff87c4664981e4397625791c8ea3bbb5f2279a3你会在Git里到处看到这种“40个字符”字符串。每一个“对象名”都是对“对象”内容做SHA1哈希计算得来的,(SHA1是一种密码学的哈希算法)。这样就意味着两个不同内容的对象不可能有相同的“对象名”。
这样做会有几个好处:
Git只要比较对象名,就可以很快的判断两个对象是否相同。- 因为在每个仓库(
repository)的“对象名”的计算方法都完全一样,如果同样的内容存在两个不同的仓库中,就会存在相同的“对象名”下。Git还可以通过检查对象内容的SHA1的哈希值和“对象名”是否相同,来判断对象内容是否正确。
对象
每个对象(object) 包括三个部分:类型,大小和内容。大小就是指内容的大小,内容取决于对象的类型,有四种类型的对象:"blob"、"tree"、 "commit" 和"tag"。
- “blob”用来存储文件数据,通常是一个文件。
- “tree”有点像一个目录,它管理一些“tree”或是 “blob”(就像文件和子目录)
- 一个“commit”只指向一个"tree",它用来标记项目某一个特定时间点的状态。它包括一些关于时间点的元数据,如时间戳、最近一次提交的作者、指向上次提交(commits)的指针等等。
- 一个“tag”是来标记某一个提交(commit) 的方法。
几乎所有的Git功能都是使用这四个简单的对象类型来完成的。它就像是在你本机的文件系统之上构建一个小的文件系统。
与SVN的区别
Git与你熟悉的大部分版本控制系统的差别是很大的。也许你熟悉Subversion、CVS、Perforce、Mercurial等等,他们使用 “增量文件系统” (Delta Storage systems), 就是说它们存储每次提交(commit)之间的差异。Git正好与之相反,它会把你的每次提交的文件的全部内容(snapshot)都会记录下来。这会是在使用Git时的一个很重要的理念。
Blob对象
一个blob通常用来存储文件的内容.
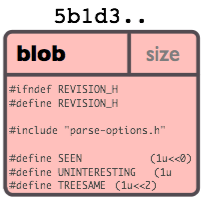
你可以使用git show命令来查看一个blob对象里的内容。假设我们现在有一个Blob对象的SHA1哈希值,我们可以通过下面的的命令来查看内容:
$ git show 6ff87c4664
Note that the only valid version of the GPL as far as this project
is concerned is _this_ particular version of the license (ie v2, not
v2.2 or v3.x or whatever), unless explicitly otherwise stated.
...
一个"blob对象"就是一块二进制数据,它没有指向任何东西或有任何其它属性,甚至连文件名都没有.
因为blob对象内容全部都是数据,如两个文件在一个目录树(或是一个版本仓库)中有同样的数据内容,那么它们将会共享同一个blob对象。Blob对象和其所对应的文件所在路径、文件名是否改被更改都完全没有关系。
Tree 对象
一个tree对象有一串(bunch)指向blob对象或是其它tree对象的指针,它一般用来表示内容之间的目录层次关系。

git show命令还可以用来查看tree对象,但是git ls-tree能让你看到更多的细节。如果我们有一个tree对象的SHA1哈希值,我们可以像下面一样来查看它:
$ git ls-tree fb3a8bdd0ce
100644 blob 63c918c667fa005ff12ad89437f2fdc80926e21c .gitignore
100644 blob 5529b198e8d14decbe4ad99db3f7fb632de0439d .mailmap
100644 blob 6ff87c4664981e4397625791c8ea3bbb5f2279a3 COPYING
040000 tree 2fb783e477100ce076f6bf57e4a6f026013dc745 Documentation
100755 blob 3c0032cec592a765692234f1cba47dfdcc3a9200 GIT-VERSION-GEN
100644 blob 289b046a443c0647624607d471289b2c7dcd470b INSTALL
100644 blob 4eb463797adc693dc168b926b6932ff53f17d0b1 Makefile
100644 blob 548142c327a6790ff8821d67c2ee1eff7a656b52 README
...
就如同你所见,一个tree对象包括一串(list)条目,每一个条目包括:mode、对象类型、SHA1值 和名字(这串条目是按名字排序的)。它用来表示一个目录树的内容。
一个tree对象可以指向(reference): 一个包含文件内容的blob对象, 也可以是其它包含某个子目录内容的其它tree对象. Tree对象、blob对象和其它所有的对象一样,都用其内容的SHA1哈希值来命名的;只有当两个tree对象的内容完全相同(包括其所指向所有子对象)时,它的名字才会一样,反之亦然。这样就能让Git仅仅通过比较两个相关的tree对象的名字是否相同,来快速的判断其内容是否不同。
(注意:在submodules里,trees对象也可以指向commits对象. 请参见 Submodules 章节)
注意:所有的文件的mode位都是644或 755,这意味着Git只关心文件的可执行位.
Commit对象
"commit对象"指向一个"tree对象", 并且带有相关的描述信息.

你可以用--pretty=raw参数来配合 git show 或 git log 去查看某个提交(commit):
$ git show -s --pretty=raw 2be7fcb476
commit 2be7fcb4764f2dbcee52635b91fedb1b3dcf7ab4
tree fb3a8bdd0ceddd019615af4d57a53f43d8cee2bf
parent 257a84d9d02e90447b149af58b271c19405edb6a
author Dave Watson <dwatson@mimvista.com> 1187576872 -0400
committer Junio C Hamano <gitster@pobox.com> 1187591163 -0700
Fix misspelling of 'suppress' in docs
Signed-off-by: Junio C Hamano <gitster@pobox.com>
你可以看到, 一个提交(commit)由以下的部分组成:
- 一个
tree对象:tree对象的SHA1签名, 代表着目录在某一时间点的内容. - 父对象 (
parent(s)): 提交(commit)的SHA1签名代表着当前提交前一步的项目历史. 上面的那个例子就只有一个父对象; 合并的提交(merge commits)可能会有不只一个父对象. 如果一个提交没有父对象, 那么我们就叫它“根提交"(root commit), 它就代表着项目最初的一个版本(revision). 每个项目必须有至少有一个“根提交"(root commit). 一个项目可能有多个"根提交“,虽然这并不常见(这不是好的作法). - 作者 : 做了此次修改的人的名字, 还有修改日期.
- 提交者(
committer): 实际创建提交(commit)的人的名字, 同时也带有提交日期. TA可能会和作者不是同一个人; 例如作者写一个补丁(patch)并把它用邮件发给提交者, 由他来创建提交(commit).
-注释 用来描述此次提交.
注意: 一个提交(commit)本身并没有包括任何信息来说明其做了哪些修改; 所有的修改(changes)都是通过与父提交(parents)的内容比较而得出的. 值得一提的是, 尽管git可以检测到文件内容不变而路径改变的情况, 但是它不会去显式(explicitly)的记录文件的更名操作. (你可以看一下 git diff 的 -M 参数的用法)
一般用 git commit 来创建一个提交(commit), 这个提交(commit)的父对象一般是当前分支(current HEAD), 同时把存储在当前索引(index)的内容全部提交.
对象模型
现在我们已经了解了3种主要对象类型(blob, tree和 commit), 好现在就让我们大概了解一下它们怎么组合到一起的.
如果我们一个小项目, 有如下的目录结构:
$>tree
.
|-- README
`-- lib
|-- inc
| `-- tricks.rb
`-- mylib.rb
2 directories, 3 files
如果我们把它提交(commit)到一个Git仓库中, 在Git中它们也许看起来就如下图:
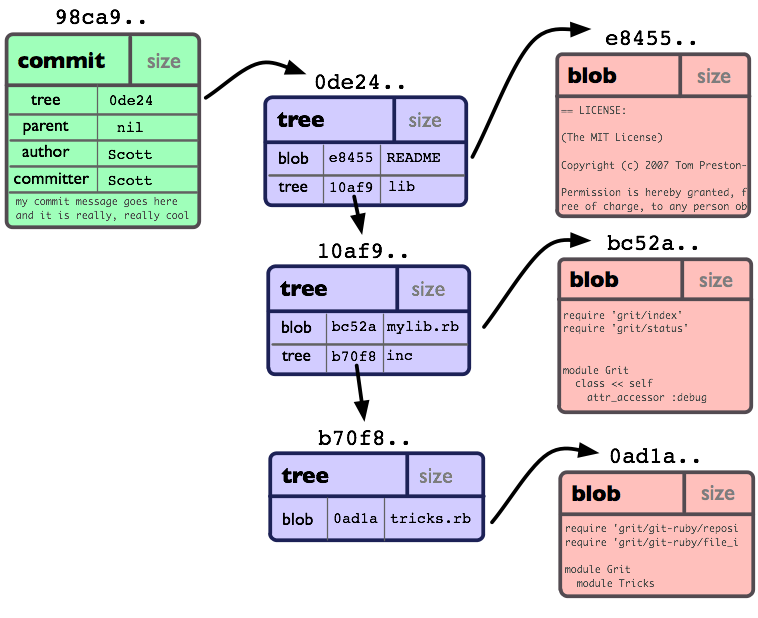
你可以看到: 每个目录都创建了 tree对象 (包括根目录), 每个文件都创建了一个对应的 blob对象 . 最后有一个 commit对象 来指向根tree对象(root of trees), 这样我们就可以追踪项目每一项提交内容.
标签对象
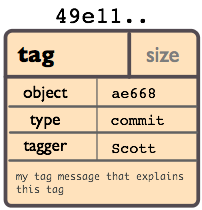
一个标签对象包括一个对象名(译者注:就是SHA1签名), 对象类型, 标签名, 标签创建人的名字("tagger"), 还有一条可能包含有签名(signature)的消息. 你可以用 git cat-file 命令来查看这些信息:
$ git cat-file tag v1.5.0
object 437b1b20df4b356c9342dac8d38849f24ef44f27
type commit
tag v1.5.0
tagger Junio C Hamano <junkio@cox.net> 1171411200 +0000
GIT 1.5.0
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1.4.6 (GNU/Linux)
iD8DBQBF0lGqwMbZpPMRm5oRAuRiAJ9ohBLd7s2kqjkKlq1qqC57SbnmzQCdG4ui
nLE/L9aUXdWeTFPron96DLA=
=2E+0
-----END PGP SIGNATURE-----
点击 git tag, 可以了解如何创建和验证标签对象. (注意: git tag 同样也可以用来创建 "轻量级的标签"(lightweight tags), 但它们并不是标签对象, 而只一些以 "refs/tags/" 开头的引用罢了).
Github上的对象模型
每一次commit了新版本以后都会产生一个Git对象模型,在Github中体现如下:
但是上一次的版本号展现为什么是7位?7位可以区分于其他的提交历史吗?
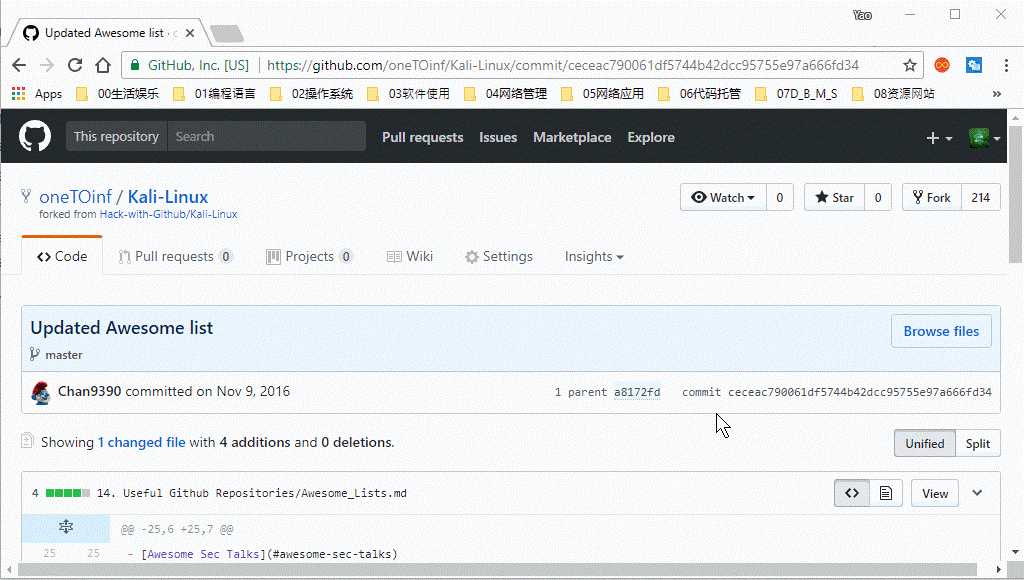
可以看到基于版本号的前7位数,还是可以访问得到当前的版本,所以上一次的版本号显示的是前7位!
