标签:style blog http color 使用 ar strong for 文件
堆栈是编程中很重要的概念,相信很多人也跳过坑,然后解决之后,继续跳坑。想整理堆栈的概念很久了。最近看了程序员自我修养,就一起整理一下吧。
本文将从几个方面学习一下堆栈
1. 堆栈概念
2. 进程,线程概念
3. 堆栈分配
1. 堆栈概念
在32位系统,内存的寻址可以达到4G。 理论上,用户可以使用一个32位的指针访问任意内存地址。
int a = 3; int * p = &a; std::cout << *p << endl;
然而,事实上并非如此,在编程中我们却常常会遇到segment fault错误,指示我们非法内存访问。证明,有些位置我们是无权访问的,或者说暂时无权访问,只有申请了该内存才能访问。
其实,大多数操作系统会把4G的内存空间进行划分,比如linux通常会默认把高地址的1G空间分配给内核(内核空间给内核线程执行特权操作,比如维护打开文件表等),剩余的作为内存空间。内存空间又大致分为堆空间,栈空间,代码区等。
*栈: 用户维护函数调用上下文。由高地址向低地址生长,通常以M为单位,由操作系统维护。
[不能申请占用过大的内存的局部变量,会导致栈爆掉而core.如果变量太大,可以考虑放到全局变量区或者使用堆]
*堆: 动态申请内存,即使用new or malloc等分配到的内存,可以比栈大很多,需用户自己释放
[new/delete,malloc/free成对出现,否则会导致内存泄露,可以使用查找内存泄露的工具监控或者自己写代码监控]
*代码区:存放代码的内存映像
*保留区:禁止访问的一些区域,比如NULL
[使用*访问置为NULL的指针会出错,也需要小心野指针]
内核态和用户态的区别?什么叫做系统调用时会陷入内核
内核线程和用户线程是存在一定的对应关系,这个由线程库来实现。内核并不感知用户级别的线程。用户需要做一些操作,比如访问文件,开辟共享内存等特权操作但是用户又没有权限时,只能通过系统调用,让操作系统的内核线程来做。称为陷入内核,此时,内核会通过调用相应的中断处理程序来执行特权操作。但是用户往往只能拿到资源的代号而无法拿到资源的实际指针,比如文件描述符。其实是内核系统给进程维护的打开文件表数组下标,而实际的文件指针是存储在下标中的元素。所以,用户拿到了描述符还是只能通过系统调用来进行操作,而无法直接拿到指针进行访问,这样,就绕过了操作系统。这是不被允许的。
2. 进程,线程概念
实际上,linux将所有运行的实体(进程,线程)称为任务(task),每一个task概念上类似于一个单线程的进程,具有内存空间,执行实体,文件资源等。不过。linux下不同的任务之间可以选择共享内存空间,因而实际上可以定义,共享了一个内存空间的不同任务构成了一个进程,而这些任务则称为进程里的线程。
接口:fork(写时复制),exec(替换程序),clone
从数据角度来看,线程数据和进程数据可以分为:
| 线程私有 | 现场共享(进程所有) |
|
局部变量(栈,寄存器) 函数参数 TLS数据 |
全局变量 动态申请的数据(堆) 函数里的静态变量 代码区 打开文件列表 |
3. 堆栈分配
3.1. 堆
用于动态分配内存,c语言中使用malloc/free进行申请和释放
int main(){
char *p = (char *)malloc(1000);
//do_something(p);
free(p);return 0;
}
那么malloc是怎么实现的呢?对于申请内存这种特权操作,肯定是操作系统内核来做比较合适,但是频繁的进行系统调用,在用户态和内核态之间切换,也就是频繁的调用中断处理程序,性能是较差的。所以,事实上都是通过c语言的运行库封装好的库函数,预申请一块设当的内存,然后零售给程序用,可以采用空闲链表或者位图等来管理。这取决于运行库的实现了。
比如glibc运行库的malloc函数是这样处理的:对于小于128KB的请求,他会在现有的堆里面,按照分配算法给他分配一块空间并返回,对于大于128KB的请求,则使用mmap()为它分配一块匿名空间(mmap可以映射到某个文件,而把使用mmap申请却不映射到文件的空间称为匿名空间),然后在这块空间里面分配给用户内存。
3.2. 栈
栈在程序运行中的作用不言而喻,非常重要。它保存了一个 函数调用所需要维护的信息,称为活动记录,包括
1. 函数的返回地址,参数
2. 临时变量
3. 上下文:寄存器
在i386中,一个活动记录用ebp和esp两个寄存器来划定范围,esp始终指向栈顶部,任何指令的执行都会改变esp的值,push stack的时候esp减小,pop stack的时候esp增大。而ebp则指向了一个固定位置,表示函数调用的开始。
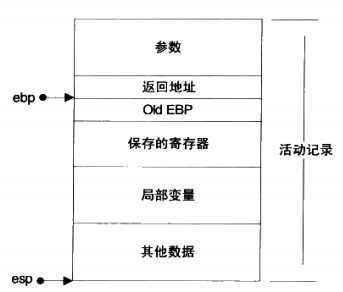
当调用函数时,
a. 把参数按照从右至左的顺序压栈
b. 当前指令的下一条指令入栈(return address)
c. 开始执行函数体(先保存old ebp)
当返回函数时:把old ebp读回寄存器,然后从return address开始执行
那么,函数的返回值是如何传递的呢?
答案:通过eax寄存器。函数将返回值存储在eax中,然后调用方读取eax。但是,eax本身只有4个字节,大于4个字节的返回值,则是通过eax存储了一个指针,而实际内容在栈上的其他地方。
当返回值是大于4个字节的的数据结构时,在压栈入参数的时候,大概会做一个这样的事情。
假设函数调用如下
some_struct foo(int arg1, int arg2);
some_struct s = foo(1, 2);
编译器会把把它处理成类似这样的概念
some_struct* foo(some_struct* ret_val, int arg1, int arg2); some_struct s; // constructor isn‘t called foo(&s, 1, 2); // constructor will be called in foo
也就是给它安排一个隐藏的参数,大概流程如下
a. 首先在栈上额外开辟一片空间,并把这块空间的一部分作为传递返回值的临时对象
b. 把这个对象的地址作为隐藏参数传递给函数
c. 函数把数据拷贝给临时对象,并把地址用eax传出
d. 调用方再把临时对象拷贝给返回值。
标签:style blog http color 使用 ar strong for 文件
原文地址:http://www.cnblogs.com/weijiaen/p/3983492.html