正则化就是在J(w,b)中加上wi^2
J(w,b)表示的是整个模型在样本上的效果,J(w,b)越小,效果越好
深度学习也就是训练参数,是J变小、
现在拿L2型正则化来举个例子
我们知道,过拟合的原因是深度网络深度太深,节点太多,激活函数太复杂(非线性)
现在我的J在原来的基础上+ (w1 * w1 + w2 * w2 + ....... + wn * wn)*lanbda/2*m
lanbda是正则化的参数
那么对于没有正则化之前的神经网络来说我的w肯定是变小了
这样就减小了神经网络对图片的影响,就相当于简化了整个神经网络
还有就是几乎所有的非线性激活函数,在0附近时其形状都是类似线性的
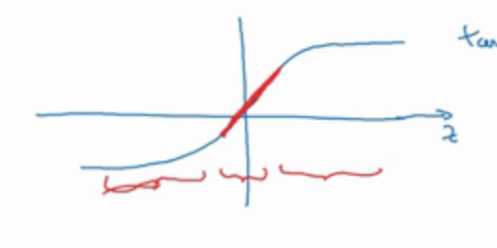
那我通过降低w是值变小,也就是x变小
那么激活函数就变得线性了
在反向传播中,我们反向传播是不用管加上的这个正则化的
我们只需要在改变每个w的值的时候 - 2 * wi * lambda / (2 * m)即可