前言:动态规划的概念
动态规划(dynamic programming)是通过组合子问题的解而解决整个问题的。分治算法是指将问题划分为一些独立的子问题,递归的求解各个问题,然后合并子问题的解而得到原问题的解。例如归并排序,快速排序都是采用分治算法思想。本书在第二章介绍归并排序时,详细介绍了分治算法的操作步骤,详细的内容请参考:http://www.cnblogs.com/Anker/archive/2013/01/22/2871042.html。而动态规划与此不同,适用于子问题不是独立的情况,也就是说各个子问题包含有公共的子问题。如在这种情况下,用分治算法则会重复做不必要的工作。采用动态规划算法对每个子问题只求解一次,将其结果存放到一张表中,以供后面的子问题参考,从而避免每次遇到各个子问题时重新计算答案。
动态规划与分治法之间的区别:
(1)分治法是指将问题分成一些独立的子问题,递归的求解各子问题
(2)动态规划适用于这些子问题不是独立的情况,也就是各子问题包含公共子问题
动态规划通常用于最优化问题(此类问题一般有很多可行解,我们希望从这些解中找出一个具有最优(最大或最小)值的解)。动态规划算法的设计分为以下四个步骤:
(1)描述最优解的结构
(2)递归定义最优解的值
(3)按自低向上的方式计算最优解的值
(4)由计算出的结果构造一个最优解
动态规划最重要的就是要找出最优解的子结构。
一 钢条切割
钢条切割问题描述:给定一段长度为n英寸的钢条和一个价格表Pi(i=1,2,3,...,n),求切割钢铁方案,使得销售收益rn最大。注意,如果长度为n英寸的钢条的价格Pn足够大,最优解可能就是完全不需要切割。
假设一个最优解将钢条切割为k段(对某个1<=k<=n),那么最优切割方案
n=i1+i2+...+ik
将钢条切割的长度分别为i1,i2,...ik的小段,得到的最大收益
rn=pi1+pi2+...+pik
更一般地,对于rn(n>=1),我们可以用更短的最优切割收益来描述它:
rn=max(pn,r1+r(n-1),r2+r(n-2),...,r(n-1)+r1)
第一个参数pn对应不切割,直接出售长度为n英寸的钢条的方案。其他n-1个参数对应另外n-1种方案:对每个i=1,2,...n-1,首先将钢条切割为长度为i和n-i的两端,接着求解这两段的最优切割收益ri和r(n-i)(每种方案的最优收益为两段的最优收益之和)。由于无法预知哪种方案会获得最大收益,我们必须考察所有可能的i,选取其中收益最大者。如果直接出售原钢条会获得最大收益,我们当然可以选择不做任何切割。
自顶向下递归实现
下面是一种直接的自顶向下的递归方法。
CUT-ROD(p,n)
if n==0
return 0
q=-∞
for i=1 to n
q=max(q,p[i]+CUT-ROD(p,n-i))
return q
C++实现代码:
#include<iostream>
using namespace std;
int cut_rod(int p[],int n)
{
if(n==1)
return 0;
int q=-1;
int i;
for(i=1;i<n;i++)
q=max(q,p[i]+cut_rod(p,n-i));
return q;
}
int main()
{
int p[11]={0,1,5,8,9,10,17,17,20,24,30};
int i;
for(i=0;i<11;i++)
cout<<cut_rod(p,i+1)<<endl;
}
运行结果:
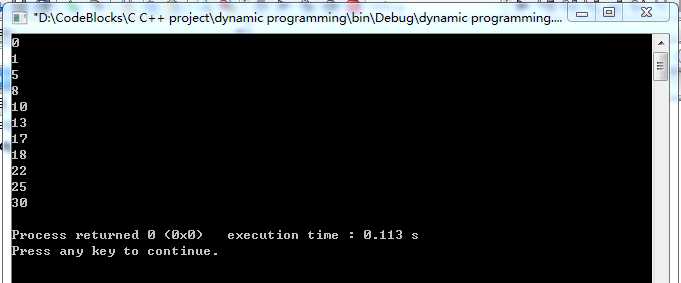
使用动态规划方法求解最优钢条切割问题
动态规划有两种等价的实现方法,下面以钢条切割问题为例展示这两种方法。
第一种方法称为带备忘的自顶向下法。此方法仍按自然的递归形式编写过程,但过程会保存每个子问题的解(通常保存在一个数组或散列表中)。当需要一个子问题的解时,过程首先检查是否已经保存过此解。如果是,则直接返回保存的值,从而节省了计算时间;否则,按通常方式计算这个子问题。我们称这个递归过程是带备忘的,因为它“记住”了之前已经计算出的结果。
第二种方法称为自底向上法。这种方法一般需要恰当定义子问题“规模”的概念,使得任何子问题的求解都只依赖于“更小的”子问题的求解。因而我们可以将子问题按规模排序,按由小到大的顺序进行求解。当求解某个子问题时,它所依赖的那些更小的子问题都已求解完毕,结果已经保存。每个子问题只需求解一次,当我们求解它(也是第一次遇到它)时,它的所有前提子问题都已经求解完成。
下面给出的是自顶向下CUT-ROD过程的伪代码,加入了备忘机制:
MEMOIZED-CUT-ROD(p,n)
let r[0...n] be a new array
for i=0 to n
r[i]=-∞
return MEMOIZED-CUT-ROD-AUX(p,n,r)
MEMOIZED-CUT-ROD-AUX(p,n,r)
if r[n]>=0
return r[i]
if n==0
q=0
else
q=-∞
for i=1 to n
q=max(q,p[i]+MEMOIZED-CUT-ROD-AUX(p,n-i,r))
r[n]=q
return q
自底向上版本:
BOTTOM-UP-CUT-ROD(p,n)
let r[0..n] be a new array
r[0]=0
for j=1 to n
q=-∞
for i=1 to j
q=max(q,p[i]+r[j-i])
r[j]=q
return r[n]
C++代码:
#include<iostream>
using namespace std;
int cut_rod(int p[],int n)
{
if(n==0)
return 0;
int q=-1;
int i;
for(i=1;i<=n;i++)
q=max(q,p[i]+cut_rod(p,n-i));
return q;
}
//自顶向下
int memoized_cut_rod_aux(int p[],int n,int r[])
{
int q=-1;
int i;
if(r[n]>=0)
return r[n];
if(n==0)
return 0;
for(i=1;i<=n;i++)
q=max(q,p[i]+memoized_cut_rod_aux(p,n-i,r));
r[n]=q;
return q;
}
int memoized_cut_rod(int p[],int n)
{
int i;
int r[n];
for(i=0;i<=n;i++)
r[i]=-1;
return memoized_cut_rod_aux(p,n,r);
}
//自底向上
int cutrod(int p[],int n)
{
int r[n];
int i,j;
for(i=0;i<=n;i++)
r[i]=0;
int q;
for(j=1;j<=n;j++)
{
q=-1;
for(i=1;i<=j;i++)
q=max(q,p[i]+r[j-i]);
r[j]=q;
}
return r[n];
}
int main()
{
int p[11]={0,1,5,8,9,10,17,17,20,24,30};
int i;
cout<<"递归:"<<endl;
for(i=0;i<11;i++)
cout<<cut_rod(p,i)<<endl;
cout<<"自顶向下:"<<endl;
for(i=0;i<11;i++)
{
cout<<memoized_cut_rod(p,i)<<endl;
}
cout<<"自底向上:"<<endl;
for(i=0;i<11;i++)
{
cout<<cutrod(p,i)<<endl;
}
}
运行结果:
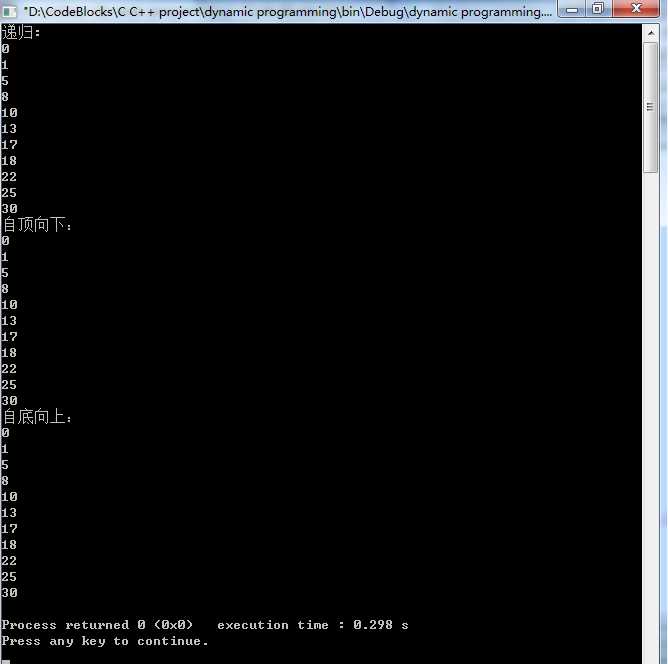
本章通过介绍插入排序和归并排序两种常见的排序算法来说明算法的过程及算法分析,在介绍归并排序算法过程中引入了分治(divide-and-conquer)算法策略。
1、插入排序
输入:n个数(a1,a2,a3,...,an)
输出:输入序列的一个排列(a1‘,a2‘,a3‘,...an‘)使得(a1‘≤a2‘≤a3‘≤...≤an‘)。
插入排序的基本思想是:将第i个元素插入到前面i-1个已经有序的元素中。具体实现是从第2个元素开始(因为1个元素是有序的),将第2个元素插入到前面的1个元素中,构成两个有序的序列,然后从第3个元素开始,循环操作,直到把第n元素插入到前面n-1个元素中,最终使得n个元素是有序的。该算法设计的方法是增量方法。书中给出了插入排序的为代码,并采用循环不变式证明算法的正确性。我采用C语言实插入排序,完整程序如下:
1 void insert_sort(int *datas,int length)
2 {
3 int i,j;
4 int key,tmp;
5 //判断参数是否合法
6 if(NULL == datas || 0==length)
7 {
8 printf("Check datas or length.\n");
9 exit(1);
10 }
11 //数组下标是从0开始的,从第二个元素(对应下标1)开始向前插入
12 for(j=1;j<length;j++)
13 {
14 key = datas[j]; //记录当前要插入的元素
15 i = j-1; //前面已经有序的元素
16 //寻找待插入元素的位置,从小到到排序,如果是从大到小改为datas[i]<key
17 while(i>=0 && datas[i] > key)
18 {
19 /×tmp = datas[i+1];
20 datas[i+1] = datas[i];
21 datas[i] = tmp;×/ 这个过程不需要进行交换,因为要插入的值保存在key中,没有被覆盖掉,在此感谢”两生花“指出问题所在
datas[i+1] = datas[i];
22 i--; //向前移动
23 }
24 datas[i+1] = key; //最终确定待插入元素的位置
25 }
26 }
插入排序算法的分析
算法分析是对一个算法所需的资源进行预测,资源是指希望测度的计算时间。插入排序过程的时间与输入相关的。插入排序的最好情况是输入数组开始时候就是满足要求的排好序的,时间代价为θ(n),最坏情况下,输入数组是按逆序排序的,时间代价为θ(n^2)。
2、归并排序
归并排序采用了算法设计中的分治法,分治法的思想是将原问题分解成n个规模较小而结构与原问题相似的小问题,递归的解决这些子问题,然后再去合并其结果,得到原问题的解。分治模式在每一层递归上有三个步骤:
分解(divide):将原问题分解成一系列子问题。
解决(conquer):递归地解答各子问题,若子问题足够小,则直接求解。
合并(combine):将子问题的结果合并成原问题的解。
归并排序(merge sort)算法按照分治模式,操作如下:
分解:将n个元素分解成各含n/2个元素的子序列
解决:用合并排序法对两个序列递归地排序
合并:合并两个已排序的子序列以得到排序结果
在对子序列排序时,长度为1时递归结束,单个元素被视为已排序好的。归并排序的关键步骤在于合并步骤中的合并两个已经有序的子序列,引入了一个辅助过程,merge(A,p,q,r),将已经有序的子数组A[p...q]和A[q+1...r]合并成为有序的A[p...r]。书中给出了采用哨兵实现merge的伪代码,课后习题要求不使用哨兵实现merge过程。在这个两种方法中都需要引入额外的辅助空间,用来存放即将合并的有序子数组,总的空间大小为n。现在用C语言完整实现这两种方法,程序如下:
1 //采用哨兵实现merge
2 #define MAXLIMIT 65535
3 void merge(int *datas,int p,int q,int r)
4 {
5 int n1 = q-p+1; //第一个有序子数组元素个数
6 int n2 = r-q; //第二个有序子数组元素个数
7 int *left = (int*)malloc(sizeof(int)*(n1+1));
8 int *right = (int*)malloc(sizeof(int)*(n2+1));
9 int i,j,k;
10 //将子数组复制到临时辅助空间
11 for(i=0;i<n1;++i)
12 left[i] = datas[p+i];
13 for(j=0;j<n2;++j)
14 right[j] = datas[q+j+1];
15 //添加哨兵
16 left[n1] = MAXLIMIT;
17 right[n2] = MAXLIMIT;
18 //从第一个元素开始合并
19 i = 0;
20 j = 0;
21 //开始合并
22 for(k=p;k<=r;k++)
23 {
24 if(left[i] < right[j])
25 {
26 datas[k] = left[i];
27 i++;
28 }
29 else
30 {
31 datas[k] = right[j];
32 j++;
33 }
34 }
35 free(left);
36 free(right);
37 }
不采用哨兵实现,需要考虑两个子数组在合并的过程中哪一个先合并结束,剩下的那个子数组剩下部分复制到数组中,程序实现如下:
1 int merge(int *datas,int p,int q,int r)
2 {
3 int n1 = q-p+1;
4 int n2 = r-q;
5 int *left = (int*)malloc(sizeof(int)*(n1+1));
6 int *right = (int*)malloc(sizeof(int)*(n2+1));
7 int i,j,k;
8 memcpy(left,datas+p,n1*sizeof(int));
9 memcpy(right,datas+q+1,n2*sizeof(int));
10 i = 0;
11 j = 0;
12 for(k=p;k<=r;++k)
13 {
14 if(i <n1 && j< n2) //归并两个子数组
15 {
16 if(left[i] < right[j])
17 {
18 datas[k] = left[i];
19 i++;
20 }
21 else
22 {
23 datas[k] = right[j];
24 j++;
25 }
26 }
27 else
28 break;
29 }
30 //将剩下的合并到数组中
31 while(i != n1)
32 datas[k++] = left[i++];
33 while(j != n2)
34 datas[k++] = right[j++];
35 free(left);
36 free(right);
37 }
merge过程的运行时间是θ(n),现将merge过程作为归并排序中的一个子程序使用,merge_sort(A,p,r),对数组A[p...r]进行排序,实例分析如下图所示: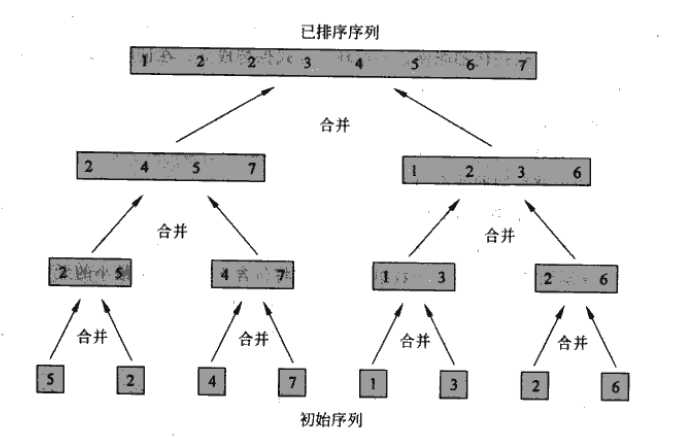
C语言实现如下:
1 void merge_sort(int *datas,int p,int r)
2 {
3 int q;
4 if(p < r)
5 {
6 q = (p+r)/2; //分解,计算出子数组的中间位置 7 merge_sort(datas,p,q); //对第一个子数组排序;
8 merge_sort(datas,q+1,r); //对第二个子数组排序
9 merge(datas,p,q,r); //合并;
10 }
11 }
归并排序算法分析:
算法中含有对其自身的递归调用,其运行时间可以用一个递归方程(或递归式)来表示。归并排序算法分析采用递归树进行,递归树的层数为lgn+1,每一层的时间代价是cn,整棵树的代价是cn(lgn+1)=cnlgn+cn,忽略低阶和常量c,得到结果为θ(nlg n)。
3、课后习题
有地道题目比较有意思,认真做了做,题目如下:
方法1:要求运行时间为θ(nlgn),对于集合S中任意一个整数a,设b=x-a,采用二分查找算法在S集合中查找b是否存在,如果b存在说明集合S中存在两个整数其和等于x。而二分查找算起的前提是集合S是有序的,算法时间为θ(lgn),因此先需要采用一种时间最多为θ(nlgn)的算法对集合S进行排序。可以采用归并排序算法,这样总的运行时间为θ(nlgn),满足题目给定的条件。
具体实现步骤:
1、采用归并排序算法对集合S进行排序
2、对集合S中任意整数a,b=x-a,采用二分查找算法b是否在集合S中,若在则集合S中存在两个整数其和等于x,如果遍历了S中所有的元素,没能找到b,即集合S中不存在两个整数其和等于x。
采用C语言实现如下:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 //非递归二叉查找
6 int binary_search(int *datas,int length,int obj)
7 {
8 int low,mid,high;
9 low = 0;
10 high = length;
11 while(low < high)
12 {
13 mid = (low + high)/2;
14 if(datas[mid] == obj)
15 return mid;
16 else if(datas[mid] > obj)
17 high = mid;
18 else
19 low = mid+1;
20 }
21 return -1;
22 }
23
24 //递归形式二分查找
25 int binary_search_recursive(int *datas,int beg,int end,int obj)
26 {
27 int mid;
28 if(beg < end)
29 {
30 mid = (beg+end)/2;
31 if(datas[mid] == obj)
32 return mid;
33 if(datas[mid] > obj)
34 return binary_search_recursive(datas,beg,mid,obj);
35 else
36 return binary_search_recursive(datas,mid+1,end,obj);
37
38 }
39 return -1;
40 }
41 //合并子程序
42 int merge(int *datas,int p,int q,int r)
43 {
44 int n1 = q-p+1;
45 int n2 = r-q;
46 int *left = (int*)malloc(sizeof(int)*(n1+1));
47 int *right = (int*)malloc(sizeof(int)*(n2+1));
48 int i,j,k;
49 memcpy(left,datas+p,n1*sizeof(int));
50 memcpy(right,datas+q+1,n2*sizeof(int));
51 i = 0;
52 j = 0;
53 for(k=p;k<=r;++k)
54 {
55 if(i <n1 && j< n2)
56 {
57 if(left[i] < right[j])
58 {
59 datas[k] = left[i];
60 i++;
61 }
62 else
63 {
64 datas[k] = right[j];
65 j++;
66 }
67 }
68 else
69 break;
70 }
71 while(i != n1)
72 datas[k++] = left[i++];
73 while(j != n2)
74 datas[k++] = right[j++];
75 free(left);
76 free(right);
77 }
78 //归并排序
79 void merge_sort(int *datas,int beg,int end)
80 {
81 int pos;
82 if(beg < end)
83 {
84 pos = (beg+end)/2;
85 merge_sort(datas,beg,pos);
86 merge_sort(datas,pos+1,end);
87 merge(datas,beg,pos,end);
88 }
89 }
90
91 int main(int argc,char *argv[])
92 {
93 int i,j,x,obj;
94 int datas[10] = {34,11,23,24,90,43,78,65,90,86};
95 if(argc != 2)
96 {
97 printf("input error.\n");
98 exit(0);
99 }
100 x = atoi(argv[1]);
101 merge_sort(datas,0,9);
102 for(i=0;i<10;i++)
103 {
104 obj = x - datas[i];
105 j = binary_search_recursive(datas,0,10,obj);
106 //j = binary_search(datas,10,obj);
107 if( j != -1 && j!= i) //判断是否查找成功
108 {
109 printf("there exit two datas (%d and %d) which their sum is %d.\n",datas[i],datas[j],x);
110 break;
111 }
112 }
113 if(i==10)
114 printf("there not exit two datas whose sum is %d.\n",x);
115 exit(0);
116 }
程序执行结果如下:

方法2:网上课后习题答案上面给的一种方法,具体思想如下:
1、对集合S进行排序,可以采用归并排序算法
2、对S中每一个元素a,将b=x-a构造一个新的集合S‘,并对S’进行排序
3、去除S和S‘中重复的数据
4、将S和S‘按照大小进行归并,组成新的集合T,若干T中有两队及以上两个连续相等数据,说明集合S中存在两个整数其和等于x。
例如:S={7,10,5,4,2,5},设x=11,执行过程如下:
对S进行排序,S={2,4,5,5,7,10}。
S‘={9,7,6,6,4,1},排序后S’={1,4,6,6,7,9}。
去除S和S‘中重复的数据后S={2,4,5,7,10},S‘={1,4,6,7,9}
归纳S和S‘组成新集合T={1,2,4,4,5,6,7,7,9,10},可以看出集合T中存在两对连续相等数据4和7,二者存在集合S中,满足4+7=11。