习总结于国立台湾大学 :李宏毅老师
Wasserstein GAN 、 Improved Training of Wasserstein GANs
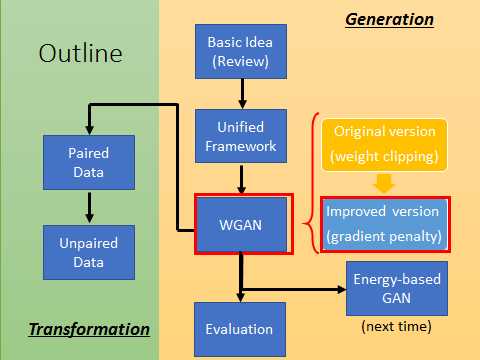
本文outline
一句话介绍WGAN: Using Earth Mover’s Distance to evaluate two distribution Earth Mover‘s Distance(EMD) = Wasserstein Distance
一. WGAN
1. Earth Mover’s Distance(EMD)
EMD: P和Q为两个分布:P分布为一堆土,Q分布为要移到的目标,那么要移动P达到Q,哪种距离更小呢?
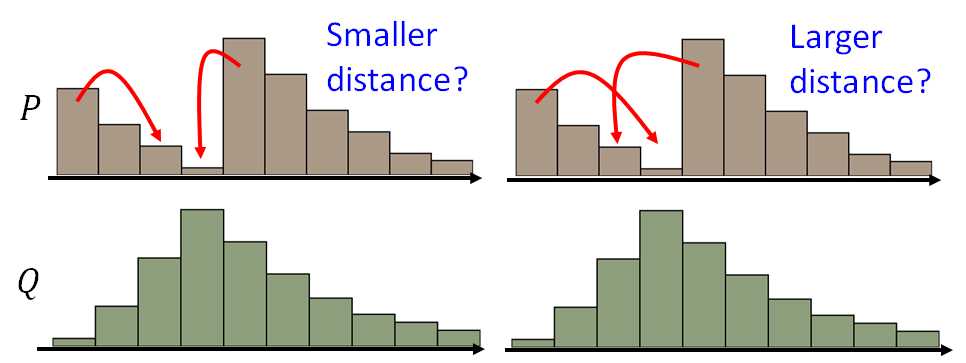
这里有许多种可能的moving plans,利用最小平均距离的moving plans来定义EMD
那么以下是最好的moving plans:
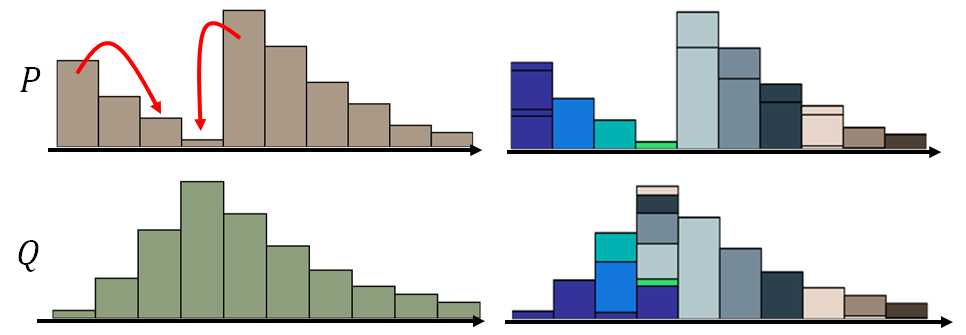
来用矩阵直观解释移土方案:
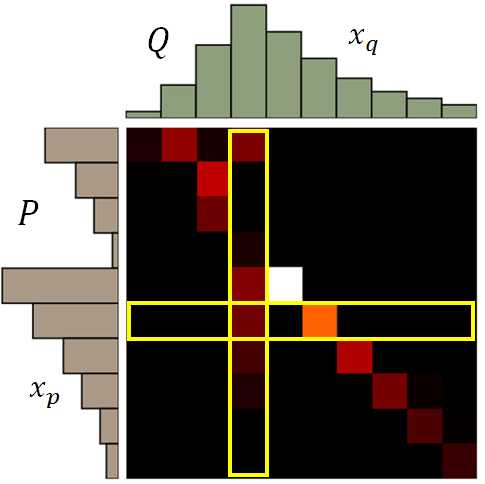
图中每个像素点对应row需要移出多少土到对应column, 越亮表示移动越多。注意每一个row的值加起来为对应P行的分布, 每个column的值加起来为对应Q行的分布。所以可以有很多的moving plan来实现:
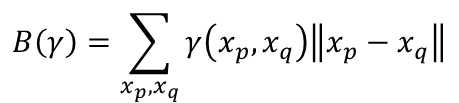
γ(xp,xq)表示从p移动多少土到q, || xp - xq ||表示pq之间的距离。上式就是给定一个plan时需要平均移动的距离。 那么EMD定义就是
穷举所有plan,EMD为最小的距离(最优的plan):
![]()
2. Why EMD
在更新过程中我们希望PG的分布和Pdata越来越相似:

但是Df(Pdata||PG): 因为从JS-divergence来看:无法从G0变到G100, 因为G50并没有比G0变小
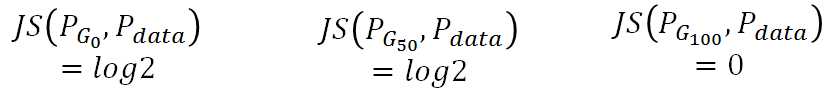
用W(Pdata, PG)则不同,G0对应的距离就是d0, G50对应的距离就是G50:所以利用Wasserstein距离时,model就会有动机使得分布趋于真实分布。
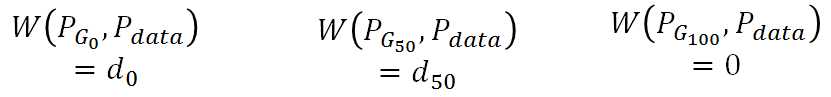
3. 回到GAN框架
![]()
我们知道所有的f-divergence都可以写成以下形式:
![]() 1)
1)
而Earth Mover’s Distance可以写成以下形式:
![]() 2)
2)
即找一个D使得大括号里的值最大,而限制是D属于1-Lipschitz。
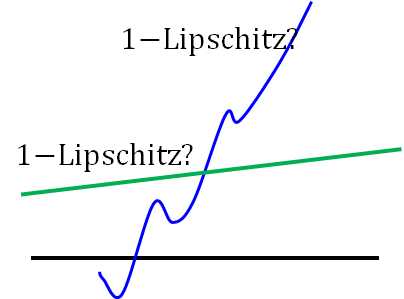
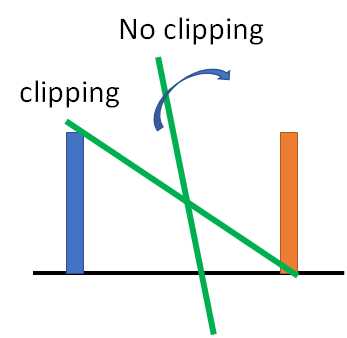
Lipschitz Function: 输出的变化小于等于输入的变化, k=1时为 1-Lipschitz ,即变化的不要太猛烈。
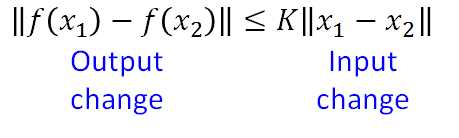
栗子:黑线为基准, 蓝线变化很猛烈不是1-Lipschitz, 而绿线变化缓和属于1-Lipschitz。
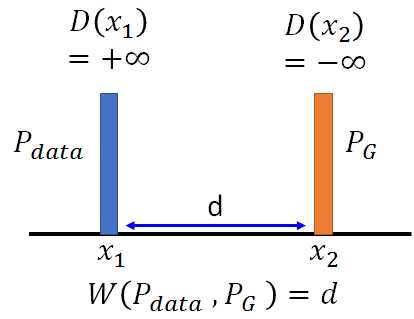
所以回到 2)式,如果没有对D的限制,当D(x1) 和D(x2)为正负无穷时可以最大化2)式,下图左。而现在对D有此限制![]() ,则D的取值如下图右:
,则D的取值如下图右:
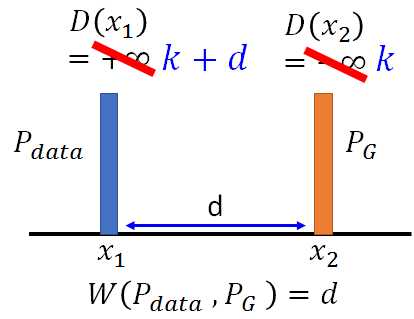
D(x1) 和D(x2)差距一定要小于d。下图说明了利用EMD的好处是PG可以沿着梯度移动到蓝色Pdata,而原生GAN的判别器D为而二元分类器,输出为sigmoid函数。对于蓝色和橙色的分布,原生GAN可能为蓝线:对应Pdata的输出值为1,对应PG的输出值为0。所以蓝色曲线在蓝色和橙色分布的梯度为0,根本没有动力去挪动generator的输出来更新。而EMD在两个分布附近都有梯度,可以继续更新。
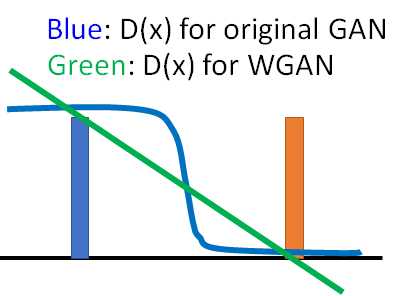
WGAN优点: WGAN will provide gradient to push PG towards Pdata
4. WGAN优化
那么怎么梯度更新呢?因为D有了限制,无法直接利用SGD。这里引入一种方法:Weight clipping
就是强制令权重w 限制在c ~ -c之间。在参数更新后,如果w>c,则令w=c, 如果w<-c,则令w=-c。我们这样做只为保证:![]()
对权重的限制表示对NN的输入做一个变化,输出的变化总是有限的。实做上对于w进行限制:就可以限制了这条直线的斜率,否则D的输出为一条很斜的直线,且不断变直,给橙色的值越来越小,给蓝色的值越来越大,无法停止。
5. WGAN 算法


result:

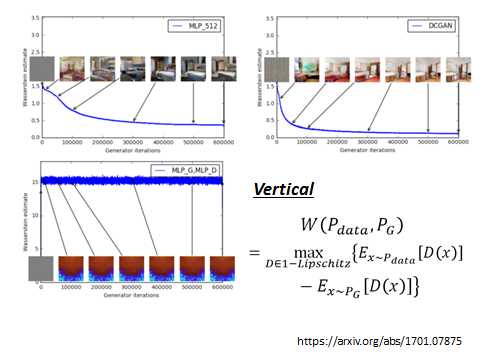
原来的GAN是衡量JS-divergence,GAN是把JS-divergence train到底,所有case的结果几乎都是0,不管你generate的image好不好,JS-divergence都是个定值。那Discriminator就不是衡量JS-divergence,D的output就变得没有意义了。但是如果我们用WGAN的话,discriminator衡量的是EMD,而这个earth mover’s distance 衡量的就是两个分布真正的距离。所以看discriminator的loss可以真的表示出generate的图片的好坏。
二. Improved WGAN
A differentiable function is 1-Lipschitz if and only if it has gradients with norm less than or equal to 1 everywhere.
就是说如果一个函数是1-Lipschitz,那么它的gradients with morm <=1: ![]()
注意这里的gradient不是对参数,而是input对output的gradient,即x对D(x)的gradient。
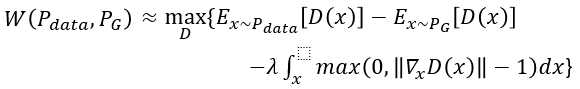
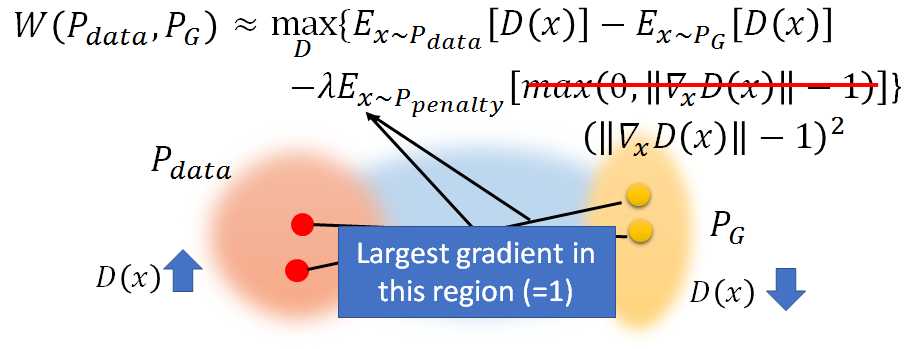
注意此惩罚项penalty:如果梯度的norm>1就会惩罚,即![]() ,因不可能对所有x作积分,所以对sample的x求期望
,因不可能对所有x作积分,所以对sample的x求期望![]()
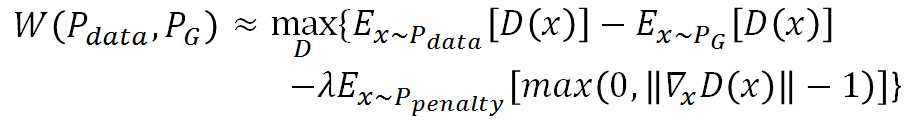
那Ppenalty是什么呢,怎么从Ppenalty sample x呢?首先从Pdata sample一个点,再从PG sample一个点,然后在其连线中sample出x,即x是在Pdata 和 PG 之间的区域中sample:
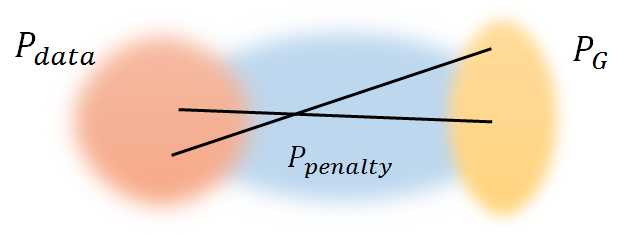
Only give gradient constraint to the region between ??_???????? and ??_?? because they influence how ??_?? moves to ??_????????
仅仅对Pdata 和 PG 之间的区域的梯度进行限制,因为只有这个区域影响PG 移向Pdata 。
而进一步,Improved WGAN不是让gradient的norm小于1,而是越接近1越好: 因为希望Pdata的D(x)越大越好, PG的 D(x)越小越好,然而这个差距总是有限的,所以希望中间的蓝色区域的gradient越大越好,因为蓝色的坡度越陡,Pdata 和PG的差距越大,然而蓝色的gradient的最大值就只能取到1.
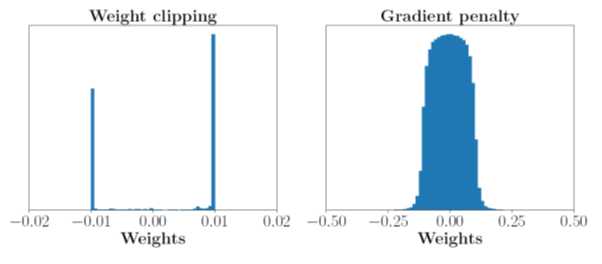
论文给出利用Weight clipping 和 Gradient penalty 学出来的discriminator有什么差距。
如果利用Weight clipping 得到的weight集中在clip的地方,而Gradient penalty得到的weight的distribution比较正常:
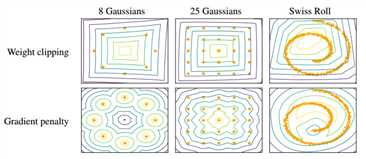
下图中黄色的点为true distribution,要learn一个discriminator使黄色的点值比较大,其他点值比较小。因为Weight clipping对weight进行了限制,所以很难学出复杂的discriminator, 而gradient penalty可以学到复杂的分布。
接下来是一些真实的实验结果:


上图主要表示不同的压力测试,Improved WGAN都有好的表现。
三. Paired Data
Conditional GAN: test to image 、 image to image
1)text to image by traditional supervised learning:
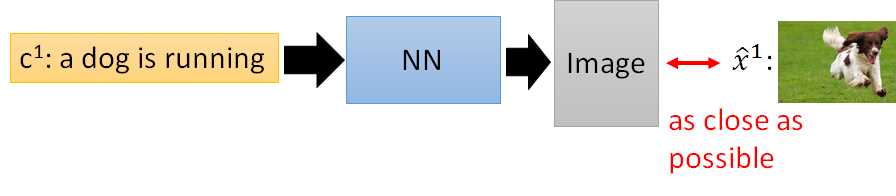
以上是传统监督方法,但这么做可能有问题,因为对于一个叙述可能有不同的image,用这个方法来训练,你的machine的output可能想同时minimize跟所有不同example之间的distance,那么可能产生的就是一个很模糊的图案:
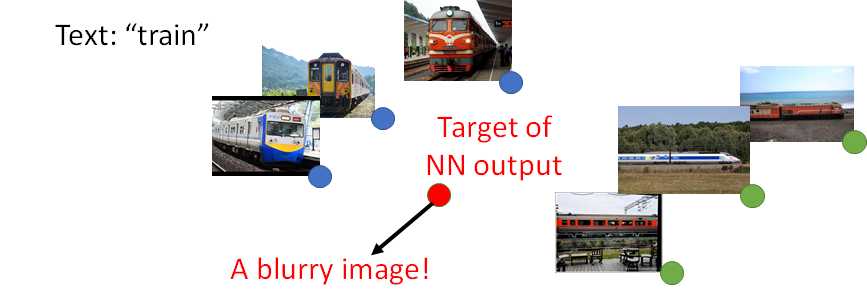
然而用GAN方法的话,输入是c和一个distribution,那么输出x也是一个distribution:即输出可能落在蓝点的分布或绿点的分布,就不会落在红点的分布:
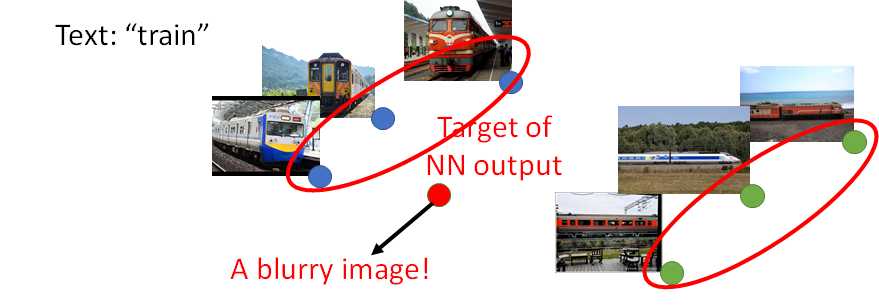
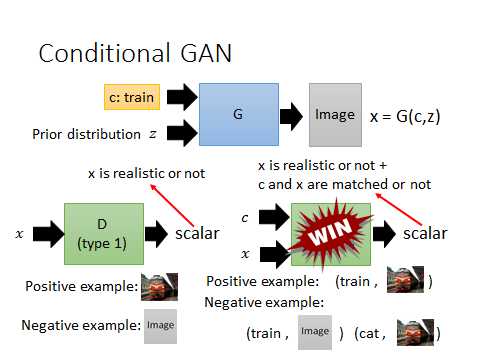
以下两种Discriminator左边可能产生清晰但图文无关的图,而右边则效果好很多:
2) image to image
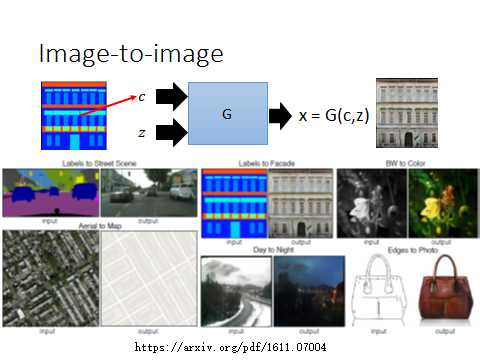
先看用传统监督方法怎么做:Traditional supervised approach
首先搜集最右边的真实图像,然后生成最左边的几何图形,利用这种传统监督方法train来learn一个NN而不是一个GAN 的generator的话,测试时可能有以下结果:

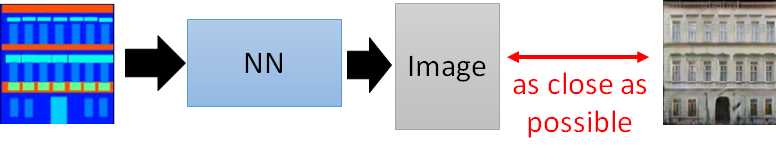
模糊原因同上:同一个输入有许多不同的输出,machine找到的是所有输出的平均。来看看用GAN train的方法:

result: machine自己加了个小阁楼

如果再加一个限制,使得generate的图像与原图越接近越好,则得到更合理的图像:
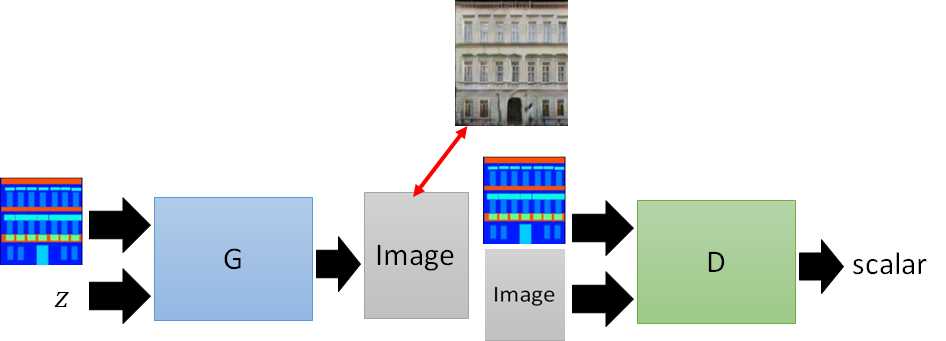
result: 更接近原图

四. Unpaired Data

此时没有成对的图片,例如只有一大堆风景图片和一大堆梵高的油画(并没有对应关系说哪张风景画对应于哪张梵高的画),那怎么做呢?
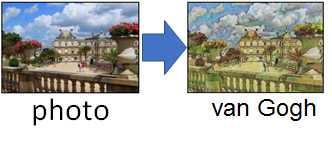


对于这种不同Domain之间的转换,方法有:Cycle GAN, Disco GAN
Cycle GAN做法:先train一个generator,可以把Domain X转为Domain Y。
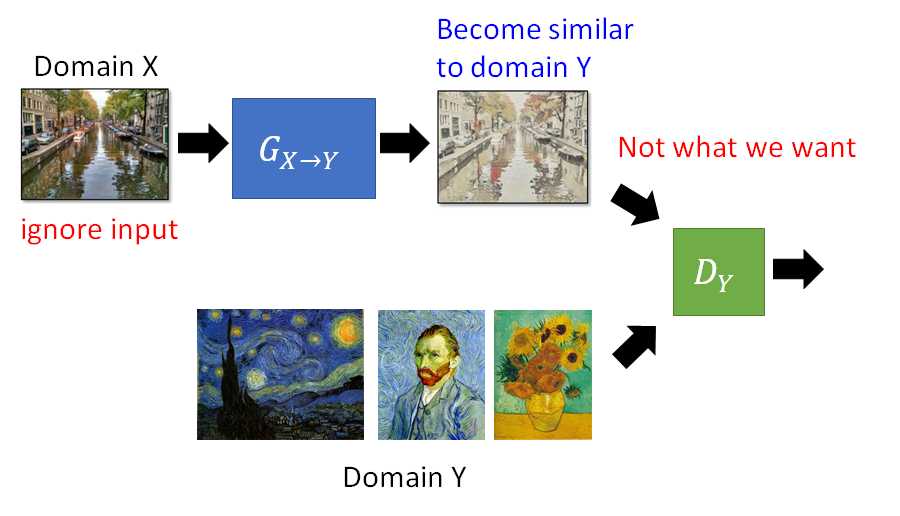
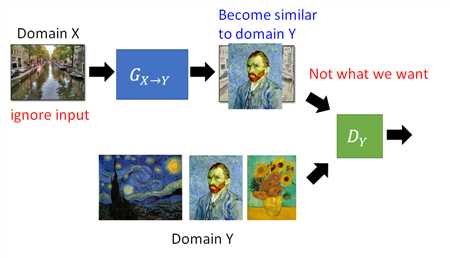
注意此时G输出会越来越像梵高的画,但可能是一张和输入完全无关的图,因为对它的要求只追求像梵高的画,上图右(原本应该产生风景油画却产生出了人物头像)。所以这里应该再加一个generator,它把梵高油画转为输入的原画(下图左):
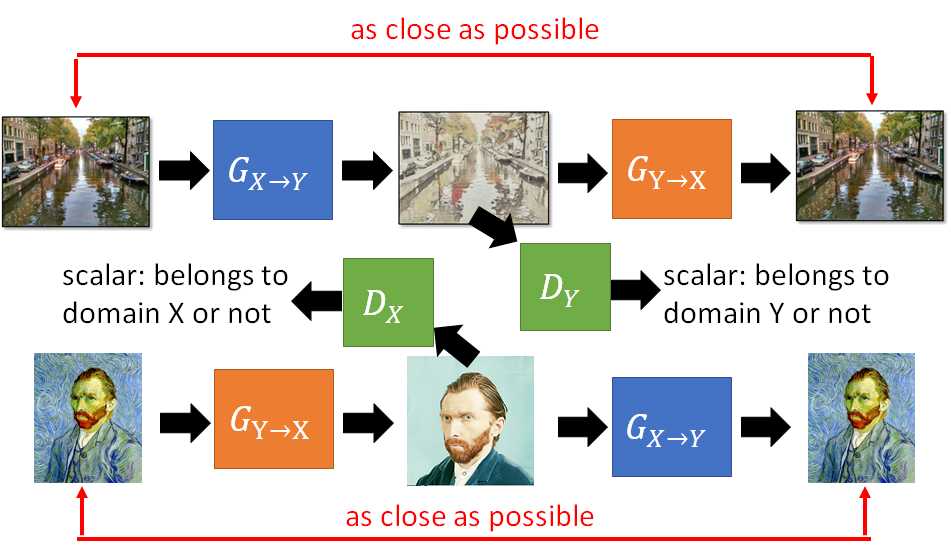
上图右可以将训练好的两个generator用来真实画与梵高油画之间的转换。