一、beautifulsoup的简单使用
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
更多知识访问:官方文档
1.安装
pip3 install beautifulsoup4
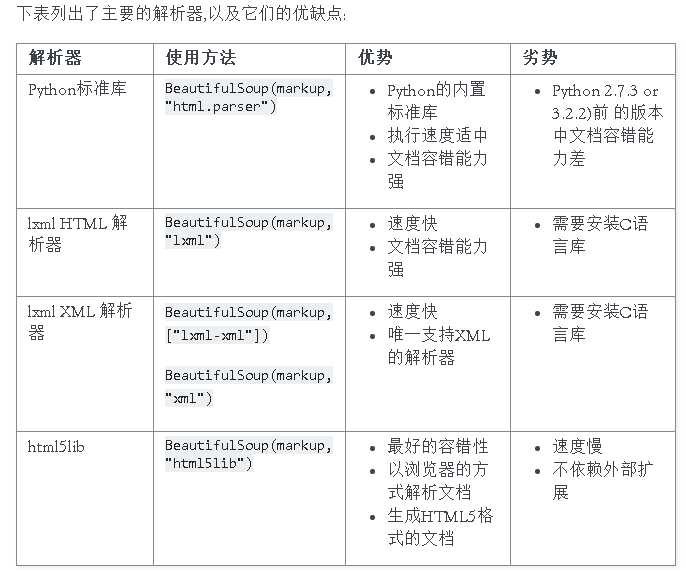
(1)解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装
pip3 install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
pip install html5lib
(2)解析器对比
2.快速开始
下面的一段HTML代码将作为例子被多次用到.这是 爱丽丝梦游仙境的 的一段内容(以后内容中简称为 爱丽丝 的文档):
<html><head><title>The Dormouse‘s story</title></head> <body> <p class="title"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p>
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, ‘html.parser‘) #<class ‘bs4.BeautifulSoup‘> 类型,html解析器:html.parser print(soup.prettify()) #以标准格式输出
结果展示:


1 <html> 2 <head> 3 <title> 4 The Dormouse‘s story 5 </title> 6 </head> 7 <body> 8 <p class="title"> 9 <b> 10 The Dormouse‘s story 11 </b> 12 </p> 13 <p class="story"> 14 Once upon a time there were three little sisters; and their names were 15 <a class="sister" href="http://example.com/elsie" id="link1"> 16 Elsie 17 </a> 18 , 19 <a class="sister" href="http://example.com/lacie" id="link2"> 20 Lacie 21 </a> 22 and 23 <a class="sister" href="http://example.com/tillie" id="link3"> 24 Tillie 25 </a> 26 ; 27 and they lived at the bottom of a well. 28 </p> 29 <p class="story"> 30 ... 31 </p> 32 </body> 33 </html>
二、beautifulsoup的遍历文档树
几个简单的浏览结构化数据的方法:
操作文档树最简单的方法就是告诉它你想获取的tag的name.
(1)如果想获取 <head> 标签,只要用 soup.head :
soup.head # <head><title>The Dormouse‘s story</title></head> soup.title # <title>The Dormouse‘s story</title>
还可以连续获取:
soup.body.b # <b>The Dormouse‘s story</b>
注意:通过点的方式只能获取当前名字的第一个标签
soup.a #总共又三个 # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
如果想获取所有标签,可以使用find_all()
soup.find_all(‘a‘) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
(2).contents 和 .children 以及.descendants(子节点)
.contents:将标签的的所有子节点以列表的形式输出,既然是列表,那就可以有列表的操作
head_tag.contents [<title>The Dormouse‘s story</title>] soup.contents[1].name #切片当然可以 # u‘html‘
.children:返回一个包含所有子节点的生成器,可以对其进行循环。
for child in title_tag.children: print(child) # The Dormouse‘s story
.descendants:返回一个包含所有子孙节点的生成器。
print(soup.head.contents) #直接的子标签只有一个 # [<title>The Dormouse‘s story</title>] for i in soup.head.descendants: #子标签有一个,还有一个孙子标签 print(i) # < title > TheDormouse‘s story</title> # The Dormouse‘s story #注意:字符串也可以作为一个独立的标签
(3).string 和 .stripped_strings
.string可以用户获取标签的内容,如果子标签有多个
print(soup.title.string) # The Dormouse‘s story print(soup.head.string) #即使有多层标签,也可以打印出来 # The Dormouse‘s story print(soup.body.string) #由于有多个子节点,所以不知道去哪一个 # None for i in soup.body: #有多个子节点可以使用循环, print(i)
.stripped_strings 可以去除多余空白内容
for string in soup.stripped_strings: print(repr(string)) # "The Dormouse‘s story" # "The Dormouse‘s story" # ‘Once upon a time there were three little sisters; and their names were‘ # ‘Elsie‘ # ‘,‘ # ‘Lacie‘ # ‘and‘ # ‘Tillie‘ # ‘;\nand they lived at the bottom of a well.‘ # ‘...‘
(4)parent 和 parents(父节点)
.parent 属性来获取某个元素的父节点
print(soup.title.parent) # <head><title>The Dormouse‘s story</title></head>
.parents 属性可以递归得到元素的所有父辈节点
for i in soup.a.parents: #它是一次从内到外 print(i.name) # p # body # html # [document] # None
(5)兄弟节点
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>") print(sibling_soup.prettify()) # <html> # <body> # <a> # <b> # text1 # </b> # <c> # text2 # </c> # </a> # </body> # </html>
.next_sibling会向下找兄弟
.previous_sibling会向上找兄弟
当你需要判断两个节点是否是兄弟节点的时候,你只需要查看其父节点是否相同就行。
sibling_soup.b.next_sibling # <c>text2</c> sibling_soup.c.previous_sibling # <b>text1</b>
.next_siblings和.previous_siblings可以对当前节点的兄弟节点迭代输出
for i in enumerate(soup.a.next_siblings,1): #向下找 print(i) # (1, ‘,\n‘) # (2, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>) # (3, ‘ and\n‘) # (4, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>) # (5, ‘;\nand they lived at the bottom of a well.‘) for i in enumerate(soup.a.previous_siblings,1): #向上找 print(i) # (1, ‘Once upon a time there were three little sisters; and their names were\n‘)
(6)回退和前进
首先需要了解一下解析的流程,例如下面字段:
<html><head><title>The Dormouse‘s story</title></head> <p class="title"><b>The Dormouse‘s story</b></p>
HTML解析器把这段字符串转换成一连串的事件: “打开<html>标签”,”打开一个<head>标签”,”打开一个<title>标签”,”添加一段字符串”,”关闭<title>标签”,”打开<p>标签”,等等
.next_element 属性结果是在<a>标签被解析之后的解析内容,不是<a>标签后的句子部分,应该是字符串”Tillie”。
print(soup.find("a",id="link2").next_element) #Lacie
.previous_element 它指向当前被解析的对象的前一个解析对象
print(soup.find("a",id="link2").previous_element) # ,
通过 .next_elements 和 .previous_elements 的迭代器就可以向前或向后访问文档的解析内容,就好像文档正在被解析一样:
for element in soup.find("a",id="link3").next_elements: print(repr(element)) # ‘Tillie‘ # ‘;\nand they lived at the bottom of a well.‘ # ‘\n‘ # <p class="story">...</p> # ‘...‘ # ‘\n‘
二、beautifulsoup的遍历文档树
三、beautifulsoup的搜索文档树
四、beautifulsoup的CSS选择器