scrapy是一个非常好用的爬虫框架,它是基于Twisted开发的,Twisted又是一个异步网络框架,既然它是异步的,那么执行起来肯定会很快,所以scrapy的执行速度也不会慢的!
如果你还没没有学过scrapy的话,那么我建议你先去学习一下,再来看这个小案例,毕竟这是基于scrapy来实现的!网上有很多有关scrapy的学习资料,你可以自行百度来学习!
接下来进入我们的正题:
如何利用scrapy来获取某个城市的天气信息呢?
我们爬取的网站是:天气网
城市我们可以自定义
1.创建项目名称
scrapy startproject weatherSpider
2.编写items.py文件
在这个文件中我们主要定义我们想要抓取的数据:
a.城市名(city)
b.日期(date)
c.天气状况(weather)
d.湿度(humidity)
e.空气质量(air_quality)
1 import scrapy
2
3
4 class WeatherspiderItem(scrapy.Item):
5 """
6 设置要爬取的信息
7 """
8 city = scrapy.Field()
9 date = scrapy.Field()
10 weather = scrapy.Field()
11 humidity = scrapy.Field()
12 air_quality = scrapy.Field()
3.打开网页
利用Chrome浏览器来提取上面5个信息
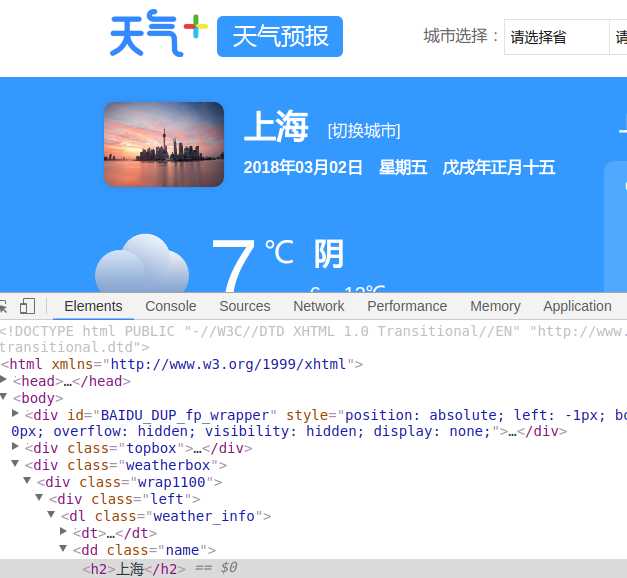
利用同样的方式我们可以找到其余4个信息个XPath表达式
4.编写爬虫文件
在第3步中我们已经找到我们想要的信息的XPath表达式了,我们就可以开始写代码了
1 import scrapy
2 from scrapy import loader
3
4 from ..items import WeatherspiderItem
5
6
7 class WeatherSpider(scrapy.Spider):
8 name = ‘weather‘
9 allowed_domains = [‘tianqi.com‘]
10 # 这是事先定义好的城市,我们还可以在里面添加其他城市名称
11 cities = [‘shanghai‘, ‘hangzhou‘, ‘beijing‘]
12 base_url = ‘https://www.tianqi.com/‘
13 start_urls = []
14 for city in cities:
15 start_urls.append(base_url + ‘{}‘.format(city))
16
17
18
19
20 def parse(self, response):
21 """
22 提取上海今天的天气信息
23 :param response:
24 :return:
25 """
26 # 创建一个ItemLoader,方便处理数据
27 iloader = loader.ItemLoader(WeatherspiderItem(),response=response)
28 iloader.add_xpath("city", ‘//dl[@class="weather_info"]//h2/text()‘)
29 iloader.add_xpath(‘date‘, ‘//dl[@class="weather_info"]/dd[@class="week"]/text()‘)
30 iloader.add_xpath(‘weather‘, ‘//dl[@class="weather_info"]/dd[@class="weather"]‘
31 ‘/p[@class="now"]/b/text()‘)
32 iloader.add_xpath(‘weather‘, ‘//dl[@class="weather_info"]/dd[@class="weather"]‘
33 ‘/span/b/text()‘)
34 iloader.add_xpath(‘weather‘, ‘//dl[@class="weather_info"]/dd[@class="weather"]‘
35 ‘/span/text()‘)
36 iloader.add_xpath(‘humidity‘, ‘//dl[@class="weather_info"]/dd[@class="shidu"]‘
37 ‘/b/text()‘)
38 iloader.add_xpath(‘air_quality‘, ‘//dl[@class="weather_info"]/dd[@class="kongqi"]‘
39 ‘/h5/text()‘)
40 iloader.add_xpath(‘air_quality‘, ‘//dl[@class="weather_info"]/dd[@class="kongqi"]‘
41 ‘/h6/text()‘)
42 return iloader.load_item()
如果觉得困惑为何要使用ItemLoader的话,建议去读一下关于ItemLoader的官方文档:传送门
5.结果保存为JSON格式
要想把我们提取的结果保存到某种文件中,我们需要编写pipelines
1 import os
2 import json
3
4
5 class StoreAsJson(object):
6 def process_item(self, item, spider):
7 # 获取工作目录
8 pwd = os.getcwd()
9 # 在当前目录下创建文件
10 filename = pwd + ‘/data/weather.json‘
11
12 with open(filename, ‘a‘) as fp:
13 line = json.dumps(dict(item), ensure_ascii=False) + ‘\n‘
14 fp.write(line)
6.添加设置信息
我们写的pipelines文件要起作用,需要在settings.py中设置
1 ITEM_PIPELINES = {
2 ‘WeatherSpider.pipelines.StoreAsJson‘: 300,
3 }
7.启动爬虫
scrapy crawl wether
8.参考资料
从零开始写Python爬虫 --- 2.3 爬虫实践:天气预报&数据存储
如果大家喜欢的话,请点个赞!!O(∩_∩)O