- 编译的流程,编译的分层与输入输出
- 每个步骤产出什么,为什么会有这个步骤
- 每个步骤如何实现
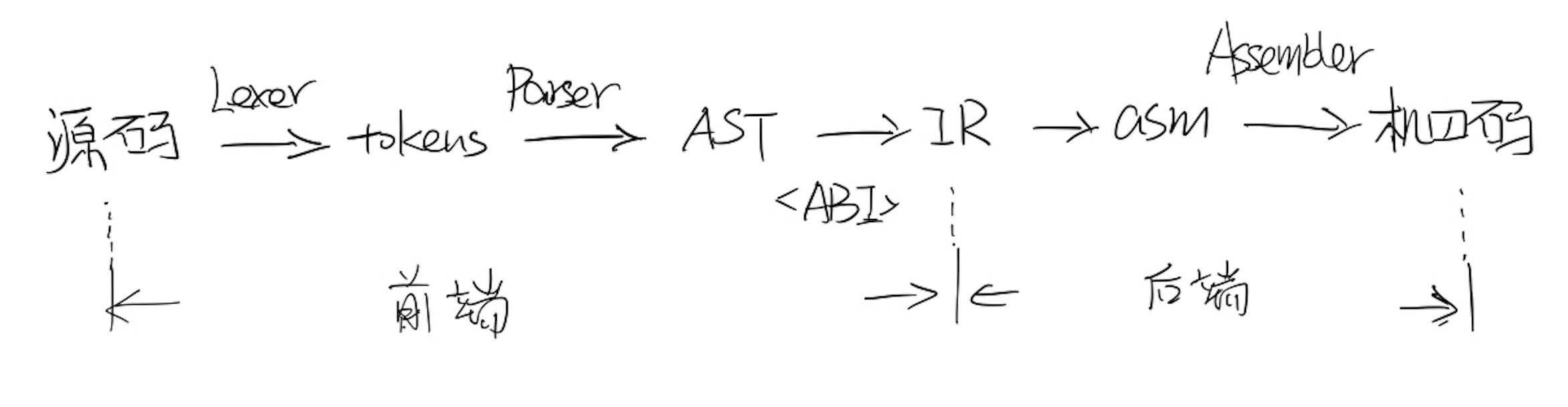
编译的流程
 ?
?
中间产物
tokens
是什么
tokens 是 Token序列,一个有序数组,每个元素都是Token类型;
Token 由字符的集和映射过来,例如:
-
123是Token(‘number‘,‘123‘) -
‘123‘是Token(‘string‘,‘123‘)
这些映射规则在语言规格说明中定义,例如:
为什么需要
Token是 最小语法单位;这种格式是为了下一步的语法解析;
即,tokens 是源码的一种表征,为了方便下一步的语法解析;
AST
是什么
AST (Abstract Syntax Tree,抽象语法树),是源代码的抽象语法结构的表征,以树状结构呈现;
AST 按语法规则,遍历1-n次 tokens 来生成;
语法规则在语言规格中定义;
为什么需要
AST 的树状数据格式方便程序员处理;
AST 包含了语法信息,这是后面转成汇编码所需要的;
其他用途
AST可以让不同编程语言互相转换,比如:- js → js AST → 补上 c没有的函数 → c AST → c
- 给某编程语言写个预处理器,增加特性,比如:
- sass:sass → sass AST → css AST → css code
- babel:es6 (经过babel)→ es5 AST → es5
- 语言语法的切面处理(AOP):
- 干掉所有注释
- 找出函数实现超过100行但是没有注释的代码作者
asm
是什么,为什么需要
asm (assembly code,汇编码);
上古时代的程序员是用机器码编程,比如纸带;
 ?
?
但是不便调试与阅读;
为了提高编程效率,需要给二进制数字取个名字,即给指令和寄存器取个别名;
然后通过汇编器将其转换成机器码,这个转换是1对1等价的;
举个例子:
```
比如cpu规定:
寄存器j1的bitcode是: 00000001
指令set的bitcode是: 00010001
指令set的指令格式是: `set 寄存器 值`
然后执行一条指令: 给寄存器j1赋值3
机器码: `00010001 00000001 00000011`
对应汇编码: `set j1 3`
```
不同cpu有不同的指令集,汇编语言按照指令集,确定自己的汇编语法;
所以一种汇编语言只适配一种CPU;
IR
是什么,为什么需要
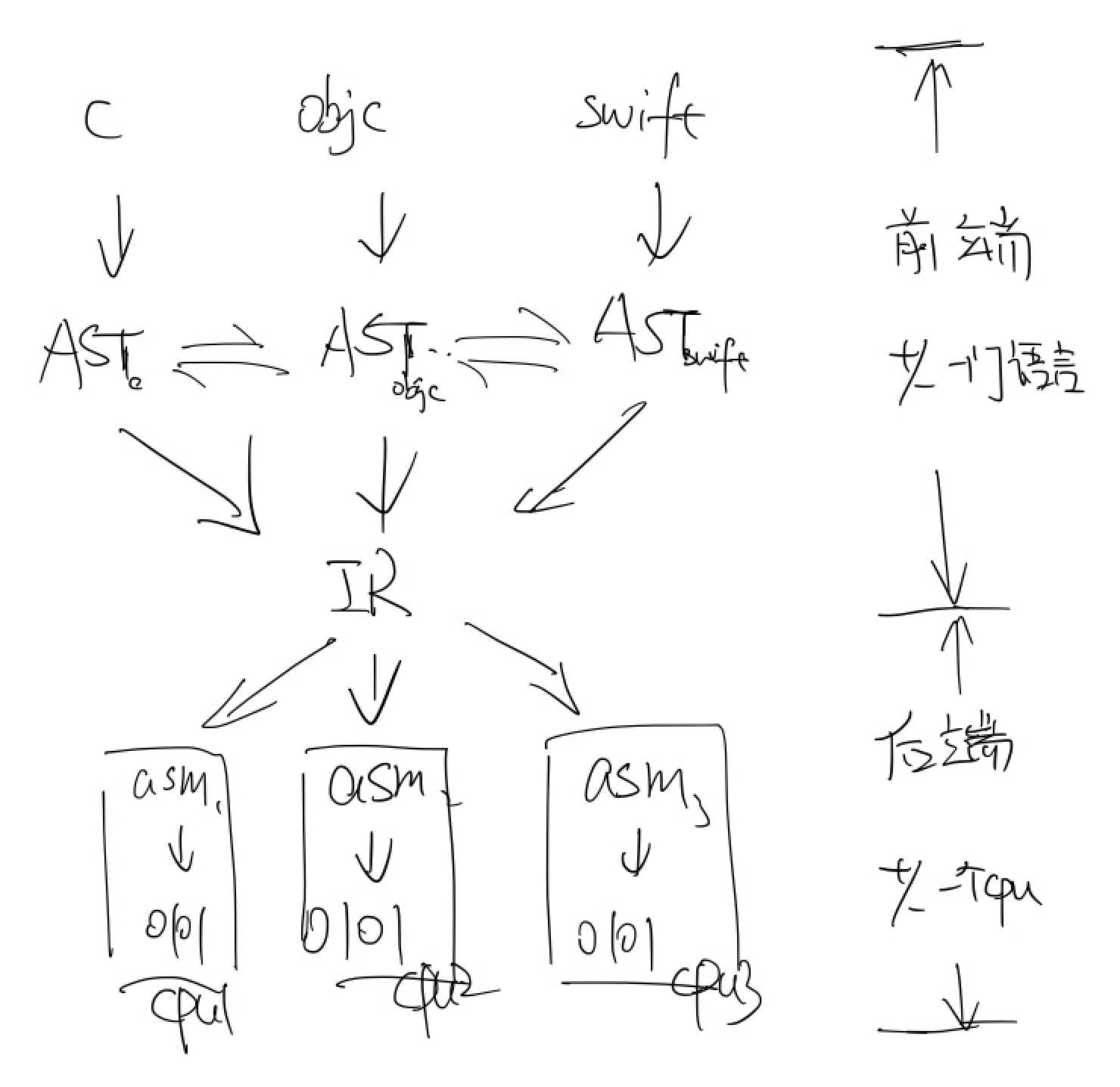
AST 不直接转成特定的汇编,中间还有一层 IR;
IR 是中间语言,或叫平台无关中间指令(Intermediate Representation)
以前,造cpu厂商很多,有不同的指令集,每一种cpu对应一种汇编语言;
要跑在不同机器上,就要兼容各种cpu,需要集成多种汇编语言;
然而一个编译器不可能集成十几个汇编语言生成器,为了复用,他们把编译过程拆成两部分:
- 以IR为分界,IR是平台无关的汇编
- 编译前端: 源码 → AST → IR
- 编译后端: IR → asm → 机器码
- 这样不同的cpu只需换不同的后端,前端可以复用
 ?
?
前端可以升级或支持新的编程语言
后端可以支持不同厂商的cpu
IR生成后,还要对IR做优化,提高运行效率 (属于前端);
为什么编译器选择在IR上做优化:
- 跟前面编程语言语法(AST)无关
- 跟后面特定汇编语法(asm)无关
ABI
什么是 ABI(Application binary interface)?
- 数据类型大小
- 数据在内存中的布局和对齐
- 函数参数/返回值的传递方法,寄存器的保存方案
- 二进制文件的格式
为什么要有这个?
- 两个不同的编程语言,写出可以互相调用的功能,就要遵循同样的ABI;
- 在二进制这一层,对于任何汇编语言,只要遵循同样的ABI,可以跨语言(汇编层)通讯;
谁定ABI?
- cpu,操作系统都能订ABI;
- 一般地,谁拳头大, 谁来造这个平台,所以是操作系统厂商规定 ABI;
- 标准谁都能订,但能不能被大家认可,就看你拳头大不大了;
如何实现
Lexer
Lexer 词法分析器,源码 → tokens 的过程
实现 Lexer 有什么价值
- 没有价值,没难度,就是扫描字符串生成
Token数组的过程 - 但是理解这个过程有用:
- 一个格式的字符串,怎样解析为成电脑可以识别的东西(0101)
- 所有配置文件无非就是一个格式,并无区别:ini,yaml,json,xml
如何实现 Lexer
- 状态机
- 一个全局变量存所有状态,很多个if,if当前状态是全局变量的某个值,执行状态对应的行为;
- 比如读到 字符
",即状态为",就往前推进n个字符直到下一个"; - json lexer 例子
Parser
Parser 语法解析器,tokens → AST 的过程
实现 Parser 有什么价值
- 可以设计一门
DSL,提高解决某领域问题的效率 - 若某领域问题的解决有多种选择/技术方案,可设计一门
DSL作为前端,对接各种实现,降低招人成本- 比如设计一个模板
DSL,可以转化成vue,react栈
- 比如设计一个模板
如何实现 Parser
- 手写 json parser 例子1
- LL(k) json parser 例子2
- Parser Combinator json parser 例子3
- Parser Generator json parser 例子4
Assembler
Assembler 汇编器,汇编码 → 机器码 的过程;
如何实现 Assembler
- 照着 cpu手册翻译,这个翻译过程是 1对1等价的
- 虚拟机例子
其他思考
关于抽象
在计算机这个世界里,没有任何问题是通过加一层抽象解决不了的;
1)上游下游无法调和,那就加一层抽象来隔离,比如:
内存分页,隔离程序与物理内存
- 上游(程序): 程序需要连续的地址空间,写程序逻辑需要
- 下游(内存): 物理内存可用地址无法保证连续性
内存分段,隔离程序间的内存
- 上游(程序): 程序用到内存不要被其他程序干扰,权限保护需要
- 下游(内存): 谁都可以读写
2)上游有无数种,下游有无数种,那就制定和遵守接口(标准);本质是设计一个转接头,把他们接起来,比如:
- IR,隔离了编译器前端和后端;
- 上游(编译前端):编程语言需要发展,会变动语法
- 下游(编译后端):编程语言要跑在不同机器上,要支持不同厂商cpu,要能转成多门汇编
- 冲突:编程语言改一次语法,转成汇编码就要改N次,效率低;
- 所以提出 IR 这层抽象,将编译器分成前后端,这样编程语言改一次语法,后端不需要变动;
- 同时,前端可以升级或支持新的编程语言;后端可以支持不同厂商的cpu;
关于跨语言通讯
AST,可以让不同编程语言互相转换
ABI, 可以让不同的汇编代码可以互相调用,即不同语言可以互相通讯
RPC,打包函数调用格式,通过socket传输,实现不同语言的通讯