搭建Hadoop的分布式集群
Hadoop集群搭建的准备操作:
1、准备四台服务器
四台服务器的主机名分别是:potter2、potter3、potter4、potter5。
对以上四台服务器需要做一下准备操作,这些准备都是为了将来搭建Hadoop集群做准备的。
(1)修改各个服务器的主机名。
第一步:先查看主机名

第二步:永久修改主机名

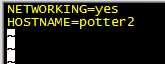
保存退出
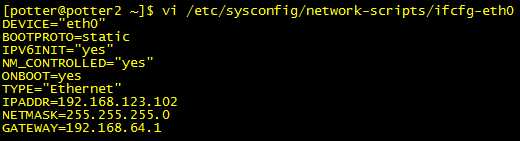
(2)配置各个服务器的IP
第一步:查看服务器ip

第二步:配置ip
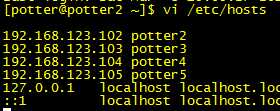
(3)配置各个服务器的主机映射
配置主机映射:
(4)添加potter用户,并且添加sudoer权限
第一步:添加用户
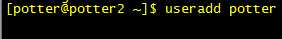
设置密码:
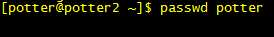
第二步:添加sudoer权限
在root用户下编辑 vi /etc/sudoers
在文件的如下位置,为hadoop添加一行即可
root ALL=(ALL) ALL
potter ALL=(ALL) ALL
然后,hadoop用户和spark用户就可以用sudo来执行系统级别的指令
[hadoop@hadoop01 ~]$ sudo useradd huangxiaoming
(5)关闭防火墙/关闭selinux
第一步:关闭防火墙

设置防火墙开机自启:

查看防火墙状态:

第二步:关闭selinux
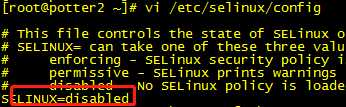
(6)更改系统启动级别为3
第一步:查看系统运行的级别
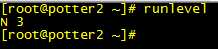
第二步:修改系统默认启动级别

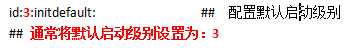
(7)安装JDK
第一步:准备JDK软件
jdk-8u73-linux-x64.tar.gz
第二步:可以通过ftp工具把软件传到linux服务器上面;或者按住键盘上面的ALT+P 直接拖动上去。

第三步:把软件解包解压缩出来到安装路径下去:
tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local/
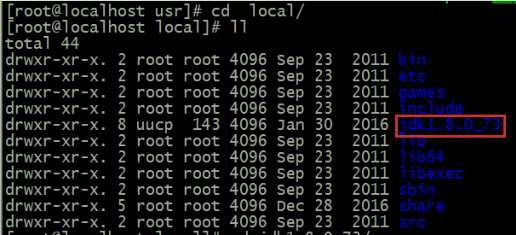
第四步:配置环境变量
1、vi /etc/profile
2、在该文件最后加入两行代码:
export JAVA_HOME=/usr/local/jdk1.8.0_73
export PATH=$PATH:$JAVA_HOME/bin
3、保存退出
4、执行 source /etc/profile
第五步:检测 jdk 是否安装成功,使用命令:java -version

然后进行克隆三台机器,只需要修改IP跟主机名。
(8)四台服务器做时间同步
第一步:使用 date 命令手动简单同步一下
命令:date -s "2016-10-23 11:11:11"
修改时间后,需要写入硬件 bios 才能在重启之后依然生效
命令:hwclock -w
第二步:配置 crontab 服务,用 ntpdate 定时同步时间(推荐方式)
ntpdate 202.120.2.101
第三步:如果类似 202.120.2.101 这种网络时间服务器无法访问,那么请自行搭建时间服务器
以上两种方式不管怎么做,都不要忘记更改时区。
(9)四台服务器配置SSH(免密登录)
第一种方式:手动配置(需要在.ssh文件夹中)命令:cd .ssh
第一步:在potter2中生成密钥对:命令:ssh-keygen
第二步:将potter2自己的公钥放置到授权列表文件authorized_keys
cat id_rsa.pub >> authorized_keys
第三步:在potter3中生成密钥对:命令:ssh-keygen
第四步:将potter2中的authorized_keys发送给potter3对应的文件夹下
scp -r authorized_keys root@192.168.123.103:/root/.ssh/(如果配置了映射文件IP地址可以写成potter3)
第五步:将potter3中的公钥放置到authorized_keys
cat id_rsa.pub >> authorized_keys(这样potter3里面authorized_keys就有了potter2和potter3的公钥,可以用 命令:cat authorized_key 查看)
第六步:将potter3中的authorized_keys发送给potter4对应的文件夹下
scp -r authorized_keys root@192.168.123.104:/root/.ssh/
第七步:将potter4中的公钥放置到authorized_keys
cat id_rsa.pub >> authorized_keys
第八步:将potter4中的authorized_keys发送给potter5对应的文件夹下
scp -r authorized_keys root@192.168.123.105:/root/.ssh/
第九步:将potter5中的公钥放置到authorized_keys
cat id_rsa.pub >> authorized_keys(这样authorized_keys文件里面就有了potter2、potter3、potter4、potter5的公钥,可以用命令:cat authorized_key 查看)
第十步:将potter5中的authorized_keys发送个各个linux服务器
scp -r authorized_keys root@192.168.123.102:/root/.ssh/
scp -r authorized_keys root@192.168.123.103:/root/.ssh/
scp -r authorized_keys root@192.168.123.104:/root/.ssh/
这样每个服务器中就都有了每一个服务器的公钥,配置完成。
第二种方式:
用 SecureCRTPortable这个软件将四台服务器连接好
第一步:点击Window选上TileVertically
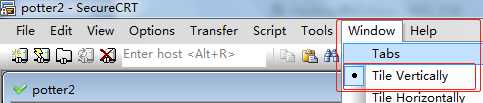
会出现以下界面
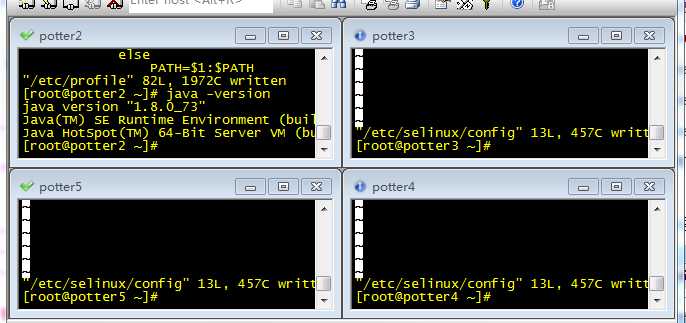
第二步:点击View,选取ChatWindow
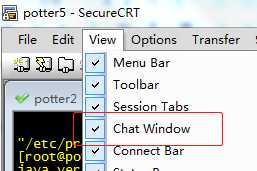
会在下方出现一个输入框
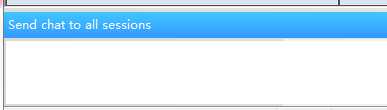
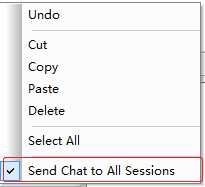
第三步:在空白处右键选择Send Chat to All Sessions,会在空白处上方出现Send Chat to All Sessions这个字样。这样就可以在空白处输入命令一起操控四台服务器。
第三步:在空白处输入命令:ssh-keygen,四台服务器会一起生成密钥对。
第四步:在空白处输入命令:ssh-copy-id potter2,会在potter2服务器上一起生成四个公钥。
第五步:在空白处执行三次分别是:
ssh-copy-id potter3
ssh-copy-id potter4
ssh-copy-id potter5
这样每个服务器上的ssh就配置好了。
以上的实现可以分两步操作,先准备好potter2,先做完1-7步之后,然后克隆出potter3、potter4、potter5。
然后再做8和9操作,这样效率最高。
正式搭建Hadoop的分布式集群
1、获取hadoop安装包
第一种方式:从官网直接下载
hadoop-2.7.5-src.tar.gz 2017-12-17 04:03 45M 源码包
hadoop-2.7.5.tar.gz 2017-12-17 04:03 207M 安装包
第二种方式:自己编译
编译的目的:就是为了获取 跟 当前安装hadoop的操作系统匹配的本地依赖库。
2、服务器的角色规划(分配主从节点)
服务 主节点 从节点
HDFS NameNode DataNode
YARN ResourceManager NodeManager
服务器的数量有四台:
服务 potter2 potter3 potter4 potter5
HDFS namenode datanode datanode datanode
YARN nodemanager nodemanager nodemanager ResourceManager
具体操作步骤:
1、准备好四台服务器,做好规划
服务器
规划安装的用户: potter
规划安装目录:/home/potter/apps
规划数据目录:/home/potter/data
2、获取安装包(最好在家目录下)
按住键盘Alt+p,直接拖入。
3、解压缩(需要解压到apps文件夹下)
tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C ~/apps/
4、修改配置文件(需要在hadoop目录下操作命令:cd apps/hadoop-2.7.5/etc/hadoop/)
(1)hadoop-env.sh
(2)core-site.xml
(3)hdfs-site.xml
(4)mapred-site.xml
(5)yarn-site.xml
(6)slaves
(1)vi hadoop-env.sh
修改JAVA_HOME
把 export JAVA_HOME=${JAVA_HOME}
改成 export JAVA_HOME=/usr/local/java/jdk1.8.0_73
(2)vi core-site.xml 在<configuration> </configuration>里面添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://potter2:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/potter/data/hadoopdata</value>
</property>
(3)vi hdfs-site.xml 在<configuration> </configuration>里面添加
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/potter/data/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/potter/data/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>HDFS 的数据块的副本存储个数, 默认是3</description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>potter3:50090</value>
<description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description>
</property>
(4)mapred-site.xml在<configuration> </configuration>里面添加
需要先复制mapred-site.xml
命令:cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)vi yarn-site.xml在<configuration> </configuration>里面添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>potter5</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
(6)vi slaves
(7)当前的hadoop安装包是存在于hadoop02上的。 但是安装的hadoop是一个分布式的集群。
把安装包分别分发给其他的节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
需要在 apps文件夹下传到另外三台服务器
scp -r hadoop-2.7.5/ hadoop@potter3:~/apps/
scp -r hadoop-2.7.5/ hadoop@potter4:~/apps/
scp -r hadoop-2.7.5/ hadoop@potter5:~/apps/
(8)配置环境变量 需要在家目录下(~)
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。可以用ll -a进行查看.bashrc文件 vi ~/.bashrc 用户变量
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
需要发送到另外三台服务器:
scp -r ~/.bashrc potter3:~
scp -r ~/.bashrc potter4:~
scp -r ~/.bashrc potter5:~
(下面的操作是没有配置环境变量,可以再需要的时候再配)
(9)初始化
需要在bin文件夹下输入命令(已经配置环境变量的命令:)$HADOOP_HOME/bin/hadoop namenode -format
(没有配置环境变量的命令:)[hadoop@hadoop02 bin]$ /home/hadoop/apps/hadoop-2.7.5/bin/hadoop namenode -format
只能在HDFS的主节点进行(主节点就是potter2服务器)
查看初始化:
进入这个目录/home/potter/data/hadoopdata/name 有一个current文件夹,进入current里面有四个文件,说明初始化成功。
(10)启动
可以再hadoop文件夹下查看配置的主节点是哪个服务器
命令:cat yarn-site.xml
第一步:启动HDFS : 不管在集群中的那个节点都可以
[hadoop@hadoop02 bin]$ /home/hadoop/apps/hadoop-2.7.5/sbin/start-dfs.sh
第二步:启动YARN : 只能在主节点中进行启动
[hadoop@hadoop02 bin]$ /home/hadoop/apps/hadoop-2.7.5/sbin/start-yarn.sh
(11)检测 或者 验证是否成功
第一种方式:JPS 命令 查看 对应的守护进行是否都启动成功
第二种方式:启动HDFS和YARN的web管理界面
HDFS : http://hadoop02:50070
YARN : http://hadoop05:8088
(12)简单使用
HDFS :(可以新建任意一个文件进行运行)
上传文件:~/apps/hadoop-2.7.5/bin/hadoop fs -put zookeeper.out /
下载文件:~/apps/hadoop-2.7.5/bin/hadoop fs -get /zookeeper.out
YARN :
新建一个文件: /wc/input/words.txt
hello huangbo
hello xuzheng
hello wangbaoqiang
新建一个文件夹:~/apps/hadoop-2.7.5/bin/hadoop fs -mkdir -p /wc/input
把words.txt上传到HDFS(在家目录下输入命令):
命令:~/apps/hadoop-2.7.5/bin/hadoop fs -put words.txt /wc/input/
查看命令:~/apps/hadoop-2.7.5/bin/hadoop fs -ls /wc/input
进入mapreduce文件夹命令:cd apps/hadoop-2.7.5/share/hadoop/mapreduce/
需要进入到mapreduce文件夹里面,这个文件夹在hadoop文件夹下面,
[potter@potter2 mapreduce]$
运行一个mapreduce的例子程序: wordcount
命令:
~/apps/hadoop-2.7.5/bin/hadoop jar ~/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wc/input /wc/output
查看最终结果:
~/apps/hadoop-2.7.5/bin/hadoop fs -cat /wc/output/part-r-00000
最终完成hadoop的集群搭建!!!