Review: LeNet-5
1998 by LeCun, one conv layer.
Case Study: AlexNet [Krizhevsky et al. 2012]

It uses a lot of mordern techniques where is still limited to historical issues (seperated feature maps, norm layers). Kind of obsolete, but it is the first CNN-based winner in ILSVRC.
ZFNet [Zeiler and Fergus, 2013]
Based on AlexNet but:
- CONV1: change from (11x11 stride 4) to (7x7 stride 2)
- CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
Play with hyperparameters. 0.0
ImageNet top 5 error: 16.4% -> 11.7%
After that we have deeper networks.
Case Study: VGGNet [Simonyan and Zisserman, 2014]
Small filters, Deeper networks.
Only use 3 by 3 filters with stride 1, pad 1 and 2 by 2 max pool with stride 2.
Why such setting? Same effective receptive field (after stacks of layers, each nueron actually looks at the same size of pixels as when applying 7 by 7 filters) but can get deeper, thus retain more non-linearities.

Details:
- ILSVRC’14 2nd in classification, 1st in localization
- Similar training procedure as Krizhevsky 2012
- No Local Response Normalisation (LRN)
- Use VGG16 or VGG19 (VGG19 only slightly better, more memory)
- Use ensembles for best results (kind of common practice)
- FC7 features generalize well to other tasks
Case Study: GoogLeNet [Szegedy et al., 2014]
Stacks inception modules and avoids FC layers, faster and smaller.
Inception modules. Concatenate the output of filters with different sizes and max pooling (all padded to make them have the same spacial size), and then use a 1 by 1 filter (called "bottleneck") to reduces channels thus reduces complexity.
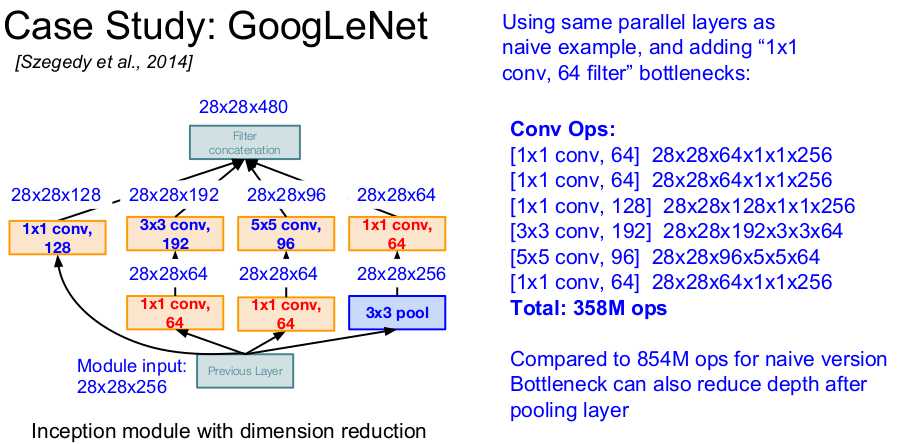
Full GoogLeNet architecture: Stem Network (vanila conv nets to get started) + Stacked Inception Modules + Classifier output (no expensive FC layers). Besides, use auxiliary classification outputs to inject additional gradient at lower layers.
Case Study: ResNet [He et al., 2015]
Very deep networks using residual connections
- 152-layer model for ImageNet
- ILSVRC’15 classification winner (3.57% top 5 error. even better than human) Swept all classification and detection competitions in ILSVRC’15 and COCO’15!
- Use Residual Block to make the optimization easier for deep nets.
- Instead of making the layers to learn to approximate H(x) (e.g. the function for output), try to let them learning to approximate F(x) = H(x) - x, which is called residual mapping. It means we use the layers to learn some delta on top of out input. Why? Their hypothesis... Another explaination: better gradient flow, make shallow layers also update.
- Can use 1 by 1 filters to improve efficiency and padding to make depth wise sum possible.

- Full ResNet architecture
-
Stack residual blocks
-
Every residual block has two 3x3 conv layers
-
Periodically, double # of filters and downsample spatially using stride 2 (/2 in each dimension)
-
Additional conv layer at the beginning
-
No FC layers at the end (only FC 1000 to output classes)
-
- Training ResNet in practice:
-
Batch Normalization after every CONV layer
-
Xavier/2 initialization from He et al.
-
SGD + Momentum (0.9)
-
Learning rate: 0.1, divided by 10 when validation error plateaus
-
Mini-batch size 256
-
Weight decay of 1e-5
-
No dropout used
-
Comparisons
Best: Inception-v4, ResNet + GoogLeNet. Efficient: GoogLeNet. ResNet: Moderate efficiency depending on model, high accuracy.
More architectures
Network in Network (NiN) [Lin et al. 2014]
Precursor to GoogLeNet and ResNet "bottleneck" layers, use micronetwork after conv layer to get more abstract features.
Identity Mappings in Deep Residual Networks [He et al. 2016]
From he again. not very clear...
Wide Residual Networks [Zagoruyko et al. 2016]
Emphersis on residual parts instead of depth, so more filters within a residual block, making the network shallower thus more parallelizable.
Aggregated Residual Transformations for Deep Neural Networks (ResNeXt) [Xie et al. 2016]
From creators again. Increases width of residual block through multiple parallel pathways (“cardinality”) similar to Inception module.
Deep Networks with Stochastic Depth [Huang et al. 2016]
Drop layer outs and bypass with identity function, thus shorter nets and better gradient flow during training.
FractalNet: Ultra-Deep Neural Networks without Residuals [Larsson et al. 2017]
Shallow to deep, and residual mapping is not necessary. Both shallow and deep paths to output.
Densely Connected Convolutional Networks [Huang et al. 2017]
DenseNet. Use Dense blocks where each layer is connected to every other layer in feedforward fashion. Alleviates vanishing gradient, strengthens feature propagation, encourages feature reuse
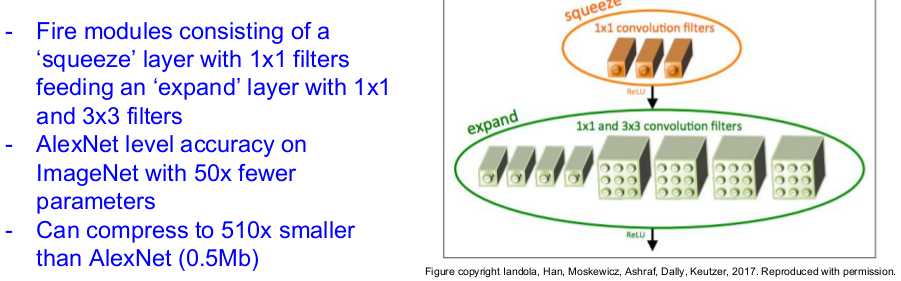
SqueezeNet: AlexNet-level Accuracy With 50x Fewer Parameters and <0.5Mb Model Size [Iandola et al. 2017]