这个地方非常感谢此篇作者的帮助 :http://blog.csdn.net/uselym/article/details/52525025
一、建立一个scrapy框架的爬虫
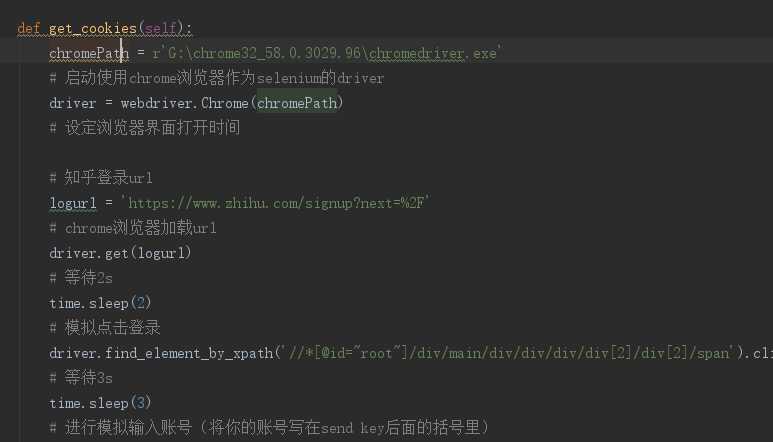
二、在spider中首先构造登录
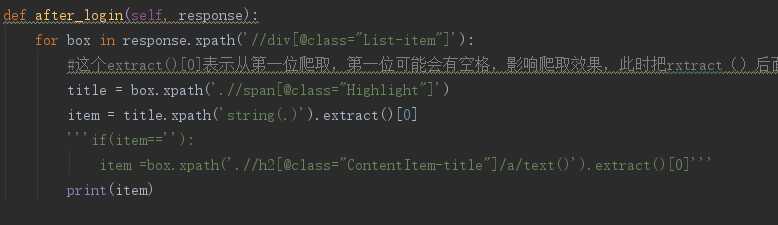
二、使用response构造需要获取到的数据
三、在parse函数中返回request请求。
四、在scrapy.Request()中指定url=“你需要爬取的界面”
总结:对于知乎的动态界面,scrapy爬虫爬取始终没有selenium模拟上下滑动获取的比较完整,望注意。
标签:blog 爬取 res 地方 spider 帮助 gpo post 建立
这个地方非常感谢此篇作者的帮助 :http://blog.csdn.net/uselym/article/details/52525025
一、建立一个scrapy框架的爬虫
二、在spider中首先构造登录
二、使用response构造需要获取到的数据
三、在parse函数中返回request请求。
四、在scrapy.Request()中指定url=“你需要爬取的界面”
总结:对于知乎的动态界面,scrapy爬虫爬取始终没有selenium模拟上下滑动获取的比较完整,望注意。
selenium+scrapy完成爬取特定的知乎界面,比如我爬取的就是搜索“”“某某某东西”
标签:blog 爬取 res 地方 spider 帮助 gpo post 建立
原文地址:https://www.cnblogs.com/rabbit-working/p/8521713.html