参考文章
Neural Networks and Deep Learning. Michael A. Nielsen
一文弄懂神经网络中的反向传播法:讲的很详细,用实例演示了反向传播法中权重的更新过程,但是未涉及偏置的更新
假设一个三层的神经网络结构图如下:
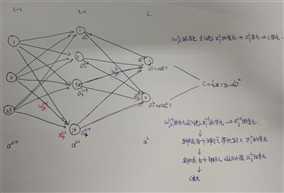
对于一个单独的训练样本x其二次代价函数可以写成:
C = 1/2|| y - aL||2 = 1/2∑j(yj - ajL)2
ajL=σ(zjL)
zjl = ∑kωjklakl-1 + bjl
代价函数C是ajL的函数,ajL又是zjL的函数,zjL又是ωjkL的函数,同时又是akL-1的函数......
证明四个基本方程(BP1-BP4),所有这些都是多元微积分的链式法则的推论
δjL = (?C/?ajL)σ‘(zjL) (BP1)
δjl = ∑k ωkjl+1δkl+1σ‘(zjl) (BP2)
?C/?ωjkl = δjlakl-1 (BP3)
?C/?bjl = δjl (BP4)
1.让我们从方程(BP1)开始,它给出了输出误差δL的表达式。
δjL = ?C/?zjL
应用链式法则,我们可以就输出激活值的偏导数的形式重新表示上面的偏导数:
δjL = ∑k (?C/?akL)(?akL/?zjL)
这里求和是在输出层的所有神经元k上运行的,当然,第kth个神经元的输出激活值akL只依赖于当k=j时第jth个神经元的带权输入zjL。所以当k≠j
时,?akL/?zjL=0。结果简化为:
δjL = (?C/?ajL)(?ajL/?zjL)
由于ajL=σ(zjL),右边第二项可以写成σ‘(zjL),方程变成
δjL = (?C/?ajL)σ‘(zjL)
2.证明BP2,它给出了下一层误差δl+1的形式表示误差δl。为此我们要以δkl+1=?C/?zkl+1的形式重写 δjl = ?C/?zjl
δjl = ?C/?zjl
=∑k (?C/?zkl+1)(?zkl+1/?zjl)
=∑k (?zkl+1/?zjl)δkl+1
这里最后一行我们交换了右边的两项,并用δkl+1的定义带入。为此我们对最后一行的第一项求值,
注意:
zkl+1 = ∑jωkjl+1ajl + bkl+1 = ∑jωkjl+1σ(zjl) + bkl+1
做微分得到
?zkl+1 /?zjl = ωkjl+1σ‘(zjl)
带入上式:
δjl = ∑k ωkjl+1δkl+1σ‘(zjl)
3.证明BP3。计算输出层?C/?ωjkL:
?C/?ωjkL = ∑m (?C/?amL)(?amL/?ωjkL )
这里求和是在输出层的所有神经元k上运行的,当然,第kth个神经元的输出激活值amL只依赖于当m=j时第jth个神经元的输入权重ωjkL。所以当k≠j
时,?amL/?ωjkL=0。结果简化为:
?C/?ωjkL = (?C/?ajL)(?ajL/?zjL)*(?zjL/?ωjkL)
= δjLakL-1
计算输入层上一层(L-1):
?C/?ωjkL-1= (∑m(?C/?amL)(?amL/?zmL)(?zmL/?ajL-1))(/?ajL-1/?zjL-1)(?zjL-1/?ωjkL-1)
= (∑mδmLωmjL)σ‘(zjL-1)akL-2
= δjL-1akL-2
对于处输入层的任何一层(l):
?C/?ωjkl = (?C/?zjl )(?zjl/?ωjkl ) = δjlakl-1
4.证明BP4。计算输出层?C/?bjL:
?C/?bjL = ∑m (?C/?amL)(?amL/?bjL )
这里求和是在输出层的所有神经元k上运行的,当然,第kth个神经元的输出激活值amL只依赖于当m=j时第jth个神经元的输入权重bjL。所以当k≠j
时,?amL/?bjL=0。结果简化为:
?C/?bjL = (?C/?ajL)(?ajL/?zjL)*(?zjL/?bjL)
= δjL
计算输入层上一层(L-1):
?C/?bjL-1= (∑m(?C/?amL)(?amL/?zmL)(?zmL/?ajL-1))(/?ajL-1/?zjL-1)(?zjL-1/?bjL-1)
= (∑mδmLωmjL)σ‘(zjL-1)
= δjL-1
对于处输入层的任何一层(l):
?C/?bjl = (?C/?zjl )(?zjl/?bjl) = δjl