国外暂时泛读!title(6):Learning random-walk label propagation for weakly-supervised semantic segmentation(学习随机游走标签传播用于弱监督语义分割)---20180201
abstract:由于相对于其他视觉任务而获得用于该任务的训练数据的花费,用于语义分割的大规模训练是具有挑战性的。 我们提出了一种新颖的训练方法来解决这个难题。 鉴于可廉价获得的稀疏图像标签,我们传播稀疏标签来产生猜测密集标签。 一个标准的基于CNN的分割网络被训练来模仿这些标签。 标签传播过程是通过随机行走命中概率来定义的,这会导致可微参数化,其中的不确定性估计被纳入我们的损失。 我们证明通过与分割预测器共同学习标签传播,能够有效地学习没有直接给出边缘监督信息的语义边缘。 实验还表明,以这种方式对分割网络进行训练胜过了原始的方法。
1 introduction
我们考虑语义分割的任务,即学习能够为图像中的每个像素精确分配语义标签的预测器。与许多其他常见视觉问题一样,卷积神经网络(CNN)已成为解决语义分割问题的主要工具,部分原因在于它们能够有效利用大型数据集。然而,语义分割的数据集比分类和检测等任务的数据集要小,这主要是由于这项任务的注释费用高得多。
为了减轻注释的负担,并且与以前的工作保持一致[1,11],我们提出了一种基于CNN的语义分割网络的方法,给出稀疏注释,例如图1所示的涂鸦,它描述了我们提出的训练策略。我们的方法是学习将稀疏标签传播到未标记点的互相一致的网络,并预测给定图像的真实标签。优化相互一致性目标可避免对密集(或完全标记)监督的需求。我们方法的一个关键创新是提出使用稀疏标签传播的特定概率模型,它是语义边界预测的可微函数。由于它是可区分的,尽管没有直接观察语义边缘,但通过基于梯度的方法最小化我们的损失函数,达到同时学习图像到语义边界预测器和图像到语义分割预测器的目的。
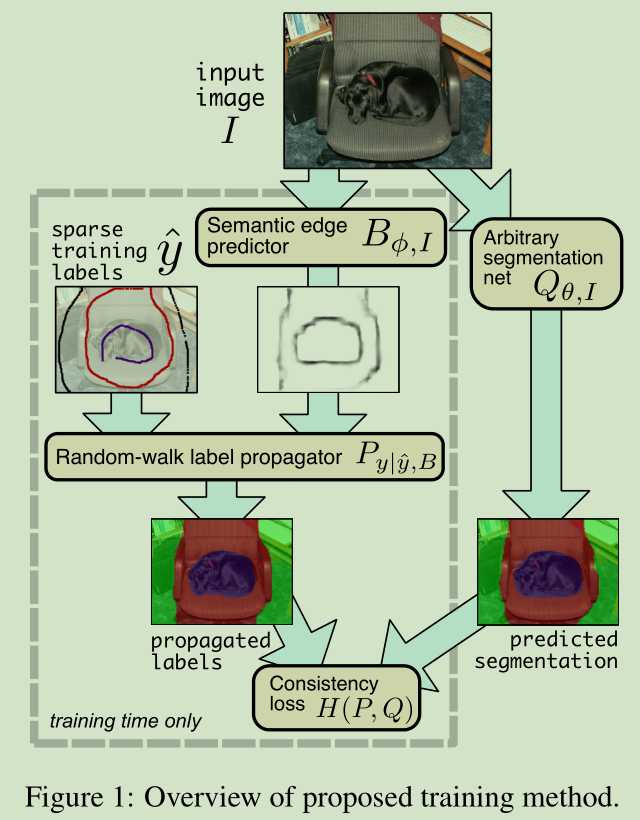
我们的方法可与Lin等人最近的工作相媲美[11]。它提出了使用超像素定义的CRF来传播稀疏标签和训练CNN以预测由此推断出的标签之间的交替。这种方法相对于我们的缺点是[11]采用了非自适应的标签平滑度的概念:具体地说,假设标签在超像素内是恒定的,并且CRF二元电位不被学习。这最终对CNN观察到的训练数据的准确性提出了一个人为的上限 ---随着收集更多数据,上限永远不会提高。相比之下,通过用学习的语义边界预测器表达标签传播,我们能够学习完全由数据驱动的标签传播概念,使我们的方法能够充分利用数据进行扩展。此外,我们的概率本质标签传播方法使我们能够获得直接纳入我们学习过程的不确定性估计,从而减少传播标签上不正确的训练的可能性。
我们方法的一个关键技术部分是用随机游走命中概率来定义标签传播过程[6],这可以实现高效的推理和基于梯度的学习。 出于这个原因,我们将我们的方法称为RAWKS,这是随机游走弱监督分割的缩写。
5 conclusion
我们已经提出了一种新的方法来减少语义分割中标记数据的花费,通过仅使用稀疏点击或涂鸦进行训练的框架。这对语义分割的实施可能性有重大影响 - 对于给定的数据集,可以用一小部分成本获得竞争性标签,相反,对于给定的预算,可以更大规模地获得标记的数据。我们的主要技术贡献是基于随机游走的标签传播机制,该机制在强大的深度神经网络体系结构中显示出可区分性和可用性,以实现语义分割。通过一种新颖的预测 - 传播者范式来实现这一目标,该范式针对给出稀疏标签的推断密集标签产生不确定性估计。我们在具有挑战性的基准测试中证实了鼓舞人心的结果。更重要的是,我们认为我们的框架与先前的工作相比具有固有的优势,因为我们的标签传播并非由超像素基线人为地设定上线,而是可以随着更大规模的训练数据而不断提高。此外,我们注意到,我们的贡献对于任何先进的基于CNN的语义分割引擎同样有效。在未来的工作中,我们将探索其他最先进的分割架构,并纳入其他形式的弱监督,如边界框。
国外暂时泛读!title(7):Learning to Adapt Structured Output Space for Semantic Segmentation(学习适应结构化输出空间进行语义分割)---20180228
abstract:用于语义分割的基于卷积神经网络的方法依赖于像素级地面实况的监督,但可能不能很好地推广到看不见的图像域。由于标注过程繁琐且劳动强度大,开发能够将源ground truth标签适应目标域的算法是非常令人感兴趣的。本文中,我们提出了一种在语义分割背景下的领域适应的对抗学习方法。考虑到语义分割是结构化输出,它包含源域和目标域之间的空间相似性,我们在输出空间采用对抗学习。为了进一步增强适应模型,我们构建了一个多层次的对抗网络,以有效地在不同的特征层面进行输出空间域适应。广泛的实验和消融研究是在不同的领域适应环境下进行的,包括synthetic-to real和cross-city情景。我们证明,所提出的方法在准确性和视觉质量方面超过了最先进的方法。
1 introduction
7 concluding remarks
在本文中,我们利用了这样一个事实,即分割是结构化输出并且在源和目标之间共享许多相似之处。我们通过输出空间中的对抗学习来解决语义分割的领域适应问题。为了进一步提高自适应模型的性能,我们构造了一个多层次的对抗网络,在不同的特征层次上有效地进行输出空间域自适应。实验结果表明,该方法对众多的基线模型和当下最先进的算法都是大有裨益的。我们希望我们提出的方法可以成为广泛的像素级预测任务的通用适应模型。
国内暂时泛读!title(8) :Multi-Evidence Filtering and Fusion for Multi-Label Classification, Object Detection and Semantic Segmentation Based on Weakly Supervised Learning(基于弱监督学习的多标签分类,对象检测和语义分割的多证据过滤和融合)---20180226
abstract:监督对象检测和语义分割需要对象甚至像素级别的注释。当仅存在图像级标签时,弱监督算法实现精确预测是具有挑战性的。顶级弱监督算法所实现的精度仍然明显低于全监督的算法。在本文中,我们提出了一种用于多标签对象识别,检测和语义分割的弱监督课程学习pipeline。在这个pipeline中,我们首先获得训练图像的中间对象定位和像素标记结果,然后使用这些结果以完全监督的方式训练任务特定的深度网络。整个过程包括四个阶段,包括训练图像中的对象定位,对象实例的过滤和融合,训练图像的像素标记以及针对特定任务的网络训练。为了在训练图像中获得干净的对象实例,我们提出了一种用于从多个解决方案机制收集的过滤,融合和分类对象实例的新算法。在这个算法中,我们结合了度量学习和基于密度的聚类来过滤检测到的对象实例。实验表明,我们的弱监督pipeline实现了多标签图像分类和弱监督对象检测方面的最新成果,而且在MS-COCO,PASCAL VOC 2007和PASCAL VOC 2012上的弱监督语义分割方面都获得了非常有竞争力的实验结果。
1 introduction
本文有以下贡献:
我们提出了一种用于多标签物体识别,检测和语义分割的新型弱监督pipeline。在该pipeline中,我们首先获得训练图像的中间标记结果,然后使用这些结果以完全监督的方式训练任务特定的网络;
为了获得训练图像中检测到的干净对象实例,我们提出了一种用于从多个解决方案机制收集的对象实例进行过滤,融合和分类的新算法。在该算法中,我们结合了度量学习和基于密度的聚类来过滤检测到的对象实例。
为了获得每个类别和每个训练图像的相对干净的逐像素概率图,我们提出了一种将图像级别和对象级别注意图与对象检测热图融合的新算法。 融合图用于训练像素标记的完全卷积网络。
6 conclusion
在本文中,我们提出了一个新的pipeline用于弱监督对象识别,检测和分割。 与以往算法不同,我们从不同的技术中融合和过滤对象实例,并执行不确定性的像素标记。我们使用由此产生的像素方向标签来生成用于多标签分类的物体检测和注意图的ground truth边界框。 我们的pipeline在所有这些任务中取得了明显更好的性能。不过,如何简化我们pipeline中的步骤有待进一步探究。
国内泛读!title(9):Self-Learning to Detect and Segment Cysts in Lung CT Images without Manual Annotation(自学习检测和分割肺部CT图像中的囊肿,无需手动注释)---20180125
abstract:图像分割是医学图像分析中的一个基本问题。近年来,深度神经网络通过大量手动注释数据的监督学习在许多医学图像分割任务上实现了令人印象深刻的性能。然而,大型医疗数据集上的专家注释是乏味的,昂贵的或有时不可用。弱监督学习可以减少注解的工作量,但仍需要一定的专业知识。最近,深度学习显示出比原始错误标签更准确的预测。受此启发,我们引入了一种弱监督的学习方法,用于肺部CT图像中的囊性病变检测和分割,而无需任何手动注释。我们的方法以自学习方式工作,在先前的步骤中产生的分割(首先通过无监督分割然后通过神经网络)被用作下一级网络学习的基础事实。对囊性肺病灶数据集进行的实验表明,深度学习可能比初始无监督注释更好,并且在自学习后逐渐改善。
国外暂时泛读!title(10):Simple Does It: Weakly Supervised Instance and Semantic Segmentation(就是这么简单:弱监督实例和语义分割)---20161223
abstract:语义标签和实例分割是需要特别昂贵注释的两个任务。从边界框检测注释形式的弱监督开始,我们提出了一种不需要修改分割训练过程的新方法。我们表明,当仔细设计来自给定边界框的输入标签时,即使是单轮训练也足以改善先前报道的弱监督结果。 总体而言,我们的弱监督方法达到全监督模型质量的95%,无论是语义标注还是实例分割。
国外泛读!title(11):Weakly Supervised Object Boundaries(弱监督的对象边界)---20151224
abstract:基于最先进的学习边界检测的方法需要大量的训练数据。由于标注对象边界是最昂贵的注释类型之一,因此需要放宽精细注释图像的要求,以使得训练更加经济实惠,同时可以扩展训练数据的数量。在本文中,我们提出了一种生成弱监督注释的技术,并且仅显示边界框注释就足以在不使用任何特定对象边界注释的情况下获得高质量的对象边界。利用所提出的弱监督技术,我们是实现了当前目标边界检测任务的最高性能,远远超过当前完全监督方式下的最先进方法。
conclusion:所提出的实验表明,当使用边界框注释来训练物体检测器时,还可以训练高质量的物体边界检测器而无需额外的注释工作。
单独使用边界框时,我们提出的弱监督技术相对于先前报道的完全监督结果针对对象特定边界而言有所改进。当使用通用边界或ground truth注释时,我们也可以实现对象边界检测任务的最高性能,相比以前报告的结果有了大幅度提高。
为了便于未来研究,本项目的所有资源,源代码,训练模型和实验结果将公开发布。