序言
去年7月刚过了日语N2,想着今年考个N1,为了加深日语文化的了解,还有学习日语,平时免不了经常上日语网站。
但是毕竟水平有限,所以不免遇到不认识的单词,日语单词的一个特点就是很多单词你知道是什么意思,但是不知道怎么读。
比如:“簡素な構造” 中的第一个词:“簡素”,很显然就是“简单,朴素的意思”,但是你肯定不知道它的读音是:“[かんそ]①”。
以前遇到这样的词的时候,就会在沪江小D网页版上面查询,但是这样特别麻烦,你要跳转到别的网站,更别提沪江每次进去弹出来的广告了。
所以呢,就想找一个能不能弄一个划词翻译的Chrome插件,能够标注出读音,怎么详细怎么来,这样便于学习。
开始折腾
因为之前写过一些过滤广告和网页辅助排序的Chrome扩展,作为一个爱折腾的开发者。当然是自给自足风衣足食啦。
百度翻译API
首先想到的是,直接使用翻译API来进行翻译,然后把翻译的结果在当前页面加一个提示框显示出来。
首先是百度翻译API:http://api.fanyi.baidu.com/api/trans/product/apidoc 官方文档很简单,只需要注册一个appid,然后HTTP请求即可。百度翻译API每个月有200W字符的免费使用资源,所以可以随便用。
注册开发者账号,申请了appid,然后照着它的文档模拟请求,因为签名方式很简单,而且官方给出了demo,很轻松就获取到了返回数据。
然而,返回的数据格式有点不对。
{
"from": "jp",
"to": "zh",
"trans_result": [
{
"src": "合格",
"dst": "合格"
}
]
}。。。这翻译很直接,只有翻译结果,什么读音都没有,很绝望,PASS.
没办法,只能使用其他平台的API了,另外一个就是有道云的翻译API。和百度API一样,注册账号,创建应用。正打算使用的时候,发现有道云的翻译API是收费的,不过不用紧张,只要注册就送100元,够你翻译几千万字符了。
有道翻译API
有道云翻译API文档:http://ai.youdao.com/docs/doc-trans-api.s#p02,我发现一个有意思的事情,百度翻译API和有道云翻译API的调用方式几乎一模一样,两个平台给出的Demo中,什么数据签名方式,数据请求方式,几乎都是一样的。唯一需要注意的是,百度请求的应用标识参数是: appid,有道云的是: appKey,要小心一点。
很快,获取到百度翻译API的返回结果如下。
{
"tSpeakUrl": "http:\/\/openapi.youdao.com\/ttsapi?q=%E5%90%88%E6%A0%BC&langType=zh-CHS&sign=3118EBCD5EC1D0A416EF32032FE55FAF&salt=1521012839301&voice=4&format=wav&appKey=3a72ad95fe43ac83",
"query": "合格",
"translation": [
"合格"
],
"errorCode": "0",
"dict": {
"url": "yddict:\/\/m.youdao.com\/dict?le=jap&q=%E5%90%88%E6%A0%BC"
},
"webdict": {
"url": "http:\/\/m.youdao.com\/dict?le=jap&q=%E5%90%88%E6%A0%BC"
},
"l": "ja2zh-CHS",
"speakUrl": "http:\/\/openapi.youdao.com\/ttsapi?q=%E5%90%88%E6%A0%BC&langType=ja&sign=3118EBCD5EC1D0A416EF32032FE55FAF&salt=1521012839301&voice=4&format=wav&appKey=3a72ad95fe43ac83"
}相比于百度,有道云增加单词的读音地址这一项,但是还是没有标注出片假名。
另外还有Google翻译的API没有测试,不过这个时候得转化一下思路,先去Chrome扩展商店看看是否已经有类似的插件。
Chrome应用商店
首先在Chrome扩展应用商店搜索“划词翻译”,有一些评分很高的插件。
我装了几个,这些插件确实做的比较好,我需要的划词功能都有,能中文翻译英文,能中文翻译日文,有的还有读音。
但是有一点,这些插件都没有标注出我要查询的单词的片假名读音,这可不行。
对于使用习惯了沪江小D查词的我来说,作为学习需求,查询一个单词,应该有各种读音,各种释义,各种词性和用法还有例句。
我找了很多插件,结果都是没有,就在我快要放弃的时候,我试着搜索了一下“沪江”。
居然有一个沪江小D的插件,虽然只有一个评论,还是个中评。我还是下载安装了,结果各种疯狂报错,无法使用。
迂回:挣扎
事情终于又回到了起点,我习惯于使用沪江小D的翻译结果,那么可不可以在沪江小D的翻译中寻找答案呢?
分析沪江小D
沪江小D翻译页面:https://dict.hjenglish.com/jp/jc/簡素
我最开始的想法:打开调试窗口,然后观察它查询单词的Ajax请求,模拟查询。然而,沪江小D查询单词并不是使用Ajax异步查询结果,(失望,不能看到接口)。
很容易发现,沪江小D查单词就是请求一个页面,把单词拼接在类似于:https://dict.hjenglish.com/jp/jc/ 这样的页面后面,所以我就想在插件里面构造这个url,然后使用ajax请求获取HTML数据,解析HTML数据。然而这个页面是禁止跨域请求的,也就是说服务端设置了禁止跨域请求,option不通过。我又把这个页面放在一个 iframe 里面,然而
Refused to display 'https://dict.hjenglish.com/jp/jc/%E7%B0%A1%E7%B4%A0' in a frame because it set 'X-Frame-Options' to 'sameorigin'.该网页禁止iframe访问。崩溃!
这个时候我猛然想到沪江小D不是有手机APP吗,那肯定会请求服务端API啊!所以我立马使用Fiddler抓包,我激动地输入单词,点击查询按钮,Fiddler中果然出现了查询请求。是压缩过的,解压之后是json格式的返回值,data里面是一大堆乱七八糟的鬼东西。呵呵哒,加密过的。
我这儿不得不佩服沪江做得真是好!
使用服务器转发
然而我是不会放弃的,不就是跨域的问题,你再怎么禁止跨域,也是浏览器能访问的嘛!对吧!在Postman中模拟请求不需要额外的cookie信息后。我在服务器写了一个转发器,请求页面数据,然后返回给插件客户端。由于我的服务器主要是PHP环境,所以用了PHP写的转发器。主要代码如下:
// 允许跨域>_<
header('Access-Control-Allow-Origin:*');
header('Access-Control-Allow-Methods:POST,GET');
header("Access-Control-Allow-Headers: Origin, X-Requested-With, Content-Type, Accept");
header('Content-Type:application/json;charset=UTF-8');
class HujianTranslate
{
protected $base_api = [
'Japanese_Chinese' => 'https://dict.hjenglish.com/jp/jc/', // from Japanese to Chinese
'Chinese_Japanese' => 'https://dict.hjenglish.com/jp/cj/', // from Chinese to Japanese
'Chinese_English' => 'https://dict.hjenglish.com/w/', // from Chinese to English
'English_Chinese' => 'https://dict.hjenglish.com/w/', // from English to Chinese
];
// 根据查询语言转换url
protected function buildUrl($query, $from, $to)
{
$url = $this->base_api[$from . '_' . $to];
$url = $url . rawurlencode($query);
return $url;
}
public function translate($query, $from, $to)
{
$url = $this->buildUrl($query, $from, $to);
$response = $this->curlCall($url, '', 'GET');
return $response;
}
// curl模拟发送http请求
public function curlCall($url, $params = null, $method="post", $withCookie = false, $timeout = CURL_TIMEOUT, $headers=array())
{
$ch = curl_init();
$data = '';
$params && $data = http_build_query($params);
if($method == "post" || $method == "POST")
{
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
curl_setopt($ch, CURLOPT_POST, 1);
}
else
{
if ($data) {
stripos($url, "?") > 0 ? $url .= "&$data" : $url .= "?$data";
}
}
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// UserAgent 模拟
$useragent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36';
curl_setopt($ch, CURLOPT_USERAGENT, $useragent);
// 绕过SSL认证
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
// 设置请求头部
$headers && curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
// 设置cookie
$withCookie && curl_setopt($ch, CURLOPT_COOKIEJAR, $_COOKIE);
$response = curl_exec($ch);
if (false === $response) {
die(curl_error($ch));
}
curl_close($ch);
return $response;
}
}
$translator = new HujianTranslate();
echo $translator->translate($_GET['query'], $_GET['from'], $_GET['to']);
exit();页面修改
终于能够成功获取了页面数据,但是这个时候我遇到了一个抉择,在哪儿解析
- 在服务端解析好页面数据,然后把结果转发给插件客户端
- 服务端不做任何数据处理,在客户端解析页面数据
开始我是想在服务端解析的,PHP的自带解析器用于XML,用来解析HTML的时候出现了一大堆报警,虽然可以正常跑,但是很不爽,又不太想重新用Python写一遍,而且服务器资源有限。后来就把这个解析的任务交给客户端了,毕竟JavaScript解析HTML很方便!
下面是对查询url:https://dict.hjenglish.com/jp/jc/上 的HTML内容解析函数
function parseHTML(data) {
var parser = new DOMParser(),
doc = parser.parseFromString(data, 'text/html'),
details = [], items,
word_details = doc.getElementsByClassName('word-details-pane');
// 遍历每种解释含义
for (var i = 0; i < word_details.length; i++) {
details[i] = {};
var word = word_details[i],
detail = {},
pronounces = word.getElementsByClassName('pronounces')[0],
word_text = word.getElementsByClassName('word-text')[0],
simple = word.getElementsByClassName('simple')[0],
detail_group = word.getElementsByClassName('detail-groups')[0];
// word text 解析
detail.text = word_text.getElementsByTagName('h2')[0].innerHTML;
// pronounces 发音解析
detail.pronounce = {};
items = pronounces.getElementsByTagName('span');
detail.pronounce.kana = items[0].innerHTML;
detail.pronounce.roma = items[1].innerHTML;
detail.pronounce.accent = items[2].innerHTML;
detail.pronounce.audio = items[3].getAttribute('data-src');
// simple 词意解析
detail.meaning = {};
detail.meaning.pos = []; // 词性
detail.meaning.means = []; // 词义
var poses = simple.getElementsByTagName('h2');
for (var j = 0; j < poses.length; j++) {
detail.meaning.pos[j] = poses[j].innerHTML; // 词性
// 词义li列表
var lis = poses[i].nextSibling.nextSibling.getElementsByTagName('li');
for (var k = 0; k < lis.length; k++) {
detail.meaning.means[j] = [];
detail.meaning.means[j][k] = lis[k].textContent; // 带序号的词义
}
}
// 解析详细释义
detail.meaning.detail = detail_group;
}
return detail;
}弄好解析函数之后,犯难了,我该怎么展示这么多的数据呢?回到沪江小D的查询展示页面,最后的展示效果不也就和这个差不多嘛!
所以最后,我放弃了使用解析函数,而是直接截取页面中的翻译结果节点,然后重新调整了样式。
function parseResponse(data) {
var parser = new DOMParser(),
doc = parser.parseFromString(data, 'text/html'),
content = doc.getElementsByClassName('word-details')[0];
// content 为主要内容区域
document.body.appendChild(content);
}对内容的重新修改包括:
- 调整间距,重新设置样式
- 去掉广告内容
- 因为一个词有多种读音,添加tab
- 限制内容显示区域,隐藏进度条
- 高亮标记例句中的查询单词
- 完善音频播放
放一下音频播放器的代码:
// 音频播放器
function AudioPlayer() {
var audio = document.createElement('audio');
audio.setAttribute('controls', 'controls');
audio.style.display = 'none';
// audio.setAttribute('src', src);
document.body.appendChild(audio);
this.play = function(src) {
audio.setAttribute('src', src);
audio.play();
return this;
};
this.stop = function() {
audio.pause();
return this;
};
// 播放结束回调
this.end = function(callback) {
var repeat = setInterval(function() {
if (audio.ended) {
clearInterval(repeat);
callback && callback();
}
}, 100);
setTimeout(function() {
clearInterval(repeat);
}, 5000);
};
return this;
}最后如愿了,将沪江翻译的内容成功改装到一个小窗口中。接下来就是将内容封装到Chrome插件中就可以了。最后的效果如下:
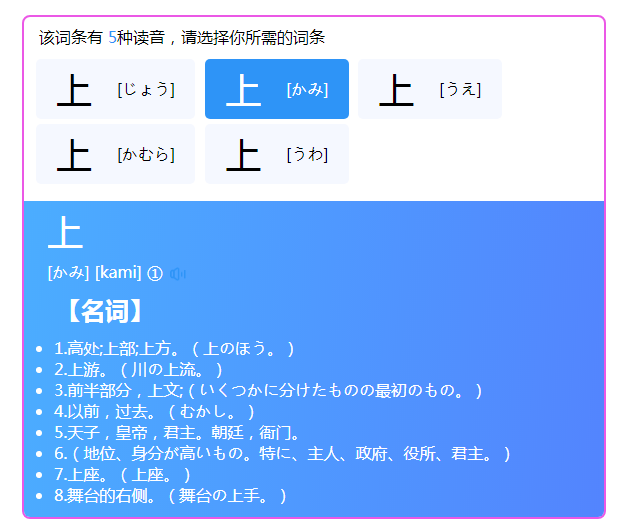
可以下拉显示例句,点击小喇叭可以发音,点击开始的词条可以切换不同发音。
对比沪江小D页面可以点击这儿
最后:放弃
封装成插件之后,只能我自己用啊,毕竟版权是沪江的,那么可不可以联系沪江的官方,获得授权什么的呢?
所以我就联系了沪江的客服,了解了几个事情
- 之前那个在Chrome上面的插件不是官方的
- 我如果要共享插件代码的话,得和他们合作部门谈
- 沪江已经在制定计划开发Chrome插件
- 沪江的客服态度很好
而且,我还发现了一个很恶心的事情,在沪江翻译的页面里面,自带划词翻译,而且效果挺好的,标注了读音。效果图如下,双击单词会在单词下面出现翻译按钮,双击翻译会在小窗口显示读音和释义。这个过程是一个ajax请求,不过呢,需要appid和签名。
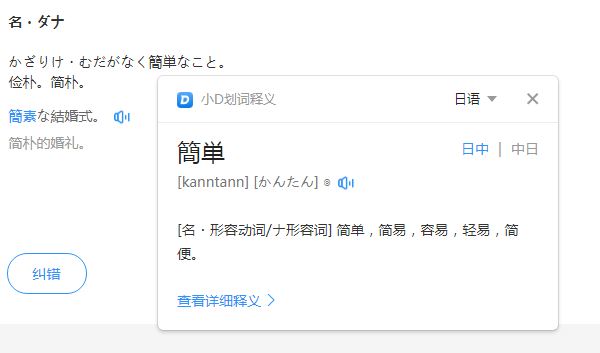
所以,我所做的工作根本没有什么用处。
所以我泪流满面的。。。久久不能言语。
相信沪江小D能够使用自己的API的话,开发的插件一定类似于这个小D划词释义一样,可以看假名。
完败收获
- PHP 有相关的库可以像jQuery一样解析HTML,可用于爬虫
- 服务端解析时,正则表达式可以用平衡组类似于堆栈匹配标签
- CSS中使用counter等函数可以为li列表自动添加序号
- 服务端跨域的破解方法是请求转发
- 复习了一波CSS样式和布局
- 我就是一个傻逼(私は馬鹿な人だ)
个人博客原文:不想说