【原创,2018-03-16,15:33:49】
刚开始学习GIT的时候,以为只要掌握几个基本的操作指令就万事大吉了。但是随着GIT使用的深入,如果不了解些原理就会遇到各种各样让人一脸懵逼的问题,所以还是要对GIT原理有一些基本了解,这里默认已经掌握常用的基本指令了。(随便搜教程看下就行,例如clone pull push add commit log reset status branch checkout差不多吧,文末也会记录一些常用命令)
ps. 文中列举了许多英文单词,因为在外文手册和help中经常会看到这些单词,而不容易得知其对应中文意思,所以这里把常用的概念注释了出来。
一、GIT原理
原理先从git-gui版本的visuallize history图开始说起,先举例子上图(win下):
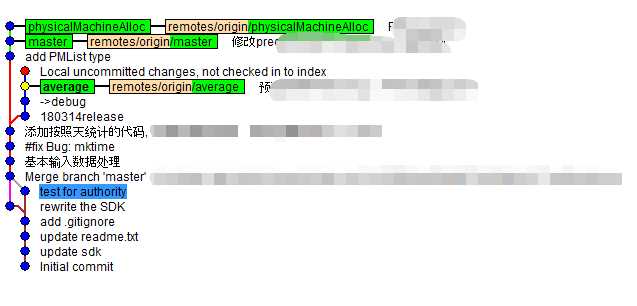
(ps. win版本直接安装git-gui就好,linux上安装gitk,并且shell中用gitk --all & 执行)
这是git中的树状图,表示了版本的演进发展过程,每个节点在英文手册或者help中称为point。下方的节点表示父节点,上面的节点表示子节点,子节点由父节点演化得到。
1、每一个圆点表示一个开发版本,每次commit或者pull、stash等就会出现新的子节点,后面的文字表示commit时写的注释信息
2、左侧方框表示分支branch名称(例如master, average等),连线的节点表示该分支当前的版本。
3、黄色表示HEAD指针指向的point(表示处于当前工作状态下),常说成HEAD指针指向当前工作状态的分支,但是图中有一些节点是没有对应分支的,此时这个节点对应的分支就用hash值表示,哈希值在git-gui中可以查到或者git log中查到。
所以从此处开始,后文中不区分节点和分支的概念,两者是一一对应的,只是有的分支有名字,有的分支没有名字(哈希值,并且git branch 也默认不显示),因此HEAD也可以当做分支名称使用
4、每一个仓库包括三部分:工作区、版本库(暂存区和分支),如图所示(图片来自网络)
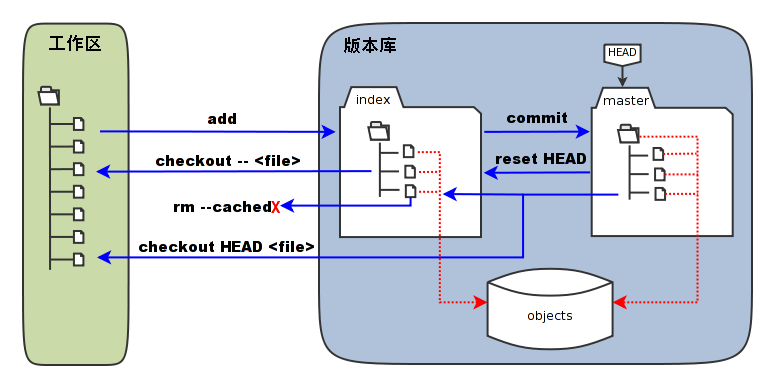
工作区:对应于当前仓库(repository)目录(linux叫目录,win叫文件夹)下除了.git文件夹外其他所有文件
版本库:对用于.git中的文件,包括暂存区(stage/index)的数据 + 各个版本分支(按照上面3的说法就是指各个节点)的数据
5、文件分为三种状态:unstaged, stage, commit之后的文件
git add 命令就是把unstaged的数据提交到缓存区表位staged状态
git commit 命令就是把staged的数据提交,生成一个新的point
git status 命令可以查看处于unstaged, staged 状态的文件,
其中unstaged文件又分为modified(之前存在的文件做出修改), untracked(新建文件)
ps. git status 输出结果中还给出了从stage撤回到unstaged, 从modified恢复修改之前的指令,untracked文件的恢复就是rm删除就可以了
二、常用指令(尽量按照使用GIT时可能碰到的先后顺序写)
1、从零开始
(1)从远程主机下载已有的仓库开始
a)ssh方式(关于SSH公钥秘钥的产生和设置这里就不提了,网上随便一搜就有)
git clone git@域名:用户ID/仓库名称.git
b) https方式
git clone https://域名/用户ID/仓库名称.git
输入用户名和密码
(2)从本地主机新建仓库开始
git init
2、本地分支的操作
git branch 查看本地分支
git branch -a 查看本地分支和远程分支
git checkout -b AAA BBB 在BBB节点上建立名字为AAA的分支并切换到该分支(即移动HEAD指针)
(缺省-b AAA:分支名字使用哈希值表示,只输入哈希值的前几位就可以了 )
(缺省BBB:默认使用HEAD指针的节点)
git branch -d AAA 删除名字为AAA的分支
(ps. 有一些节点没有分支名字并且不是现有分支的父节点,在GIT中会保存一段时间,之后就可能被删除了)
3、完成本次开发准备本地提交
(git status 查看文件状态)
git add 文件名/.(点表示所有unstaged文件)
git commit -m "xxx
4、版本还原(保证不存在unstaged和staged的文件才可以使用还原功能,可以commit,或者撤回add和修改,或者stash把未commit文件加入到栈)
分为两种情况:
a)HEAD指向有名字的分支,可以理解为把该分支移动到HEAD指向节点的父节点,并且移动HEAD指针到该父节点
b)HEAD指向没有名字的分支(哈希值表示),reset等价于移动HEAD指针的checkout指令
这里主要针对a情况
git log -n 查看记录(显示当前节点的所有父节点)
git reset --soft XXX 把当前分支(有名字)移动到历史分支XXX,工作区文件不变,版本库中有差异的文件直接放入到暂存区(index),即staged状态
git reset --mixed XXX (--mixed可缺省) 当前分支(有名字)移动到历史分支XXX,工作区文件不变,版本库中有差异的文件放入到unstaged状态
git reset --hard XXX 当前分支(有名字)移动到历史分支XXX,工作区文件也都全部还原到历史版本
ps1. reset不会立刻把git树中的节点删除掉,而是会保存一段时间
ps2. XXX参数为分支名称,可以是有名字的分支名称,无名字分支的哈希值名称,HEAD指针变形(HEAD^表示上一个父节点,HEAD^^上两个父节点)
5、push(同4)
(origin表示该仓库对应的远程仓库,在clone之后已经默认设置好了,不过可以修改也可以建立新的源)
git push origin AAA:BBB 把AAA分支推到远程BBB分支(缺省 “:BBB”:远程分支和本地分支同名,远程没有同名分支则新建;缺省“AAA”:删除远程BBB分支)
(缺省“AAA:BBB”:push HEAD指针指向的分支,远程分支和本地分支同名)
(缺省 "origin AAA:BBB"): 若源是惟一的,则origin可以省略,指令作用同上
6、pull(同4)
(1)pull = fetch + merge
(2)pull一般用于本地已经存在的分支,用于同步
git pull origin AAA:BBB(AAA是远程分支,BBB是本地分支)
(缺省:BBB表示本地分支和远程分支同名,缺省AAA:BBB表示HEAD分支,origin唯一的时候也可以缺省)
(3)fetch一般用于获得本地不存在的分支,或者已知本地和远程分支有冲突想要先检查区别再合并的情况
fetch会修改FETCH_HEAD指针,记录在本地的一个文件中,指向着目前已经从远程仓库取下来的分支的末端版本。(也当做一个分支名称就可以了)
git fetch origin AAA:BBB(同上)
(这里比较坑的一点即是缺省AAA:BBB表示的是master分支,不!是!HEAD!)
(4)git diff AAA:BBB 比较AAA分支到BBB分支的变化,如果结果太长建议使用重定向,让结果输出到文件(例如git diff AAA:BBB > a.diff )
(缺省:BBB,表示AAA分支到当前HEAD分支的变化,例如git diff FETCH_HEAD)
关于diff输出的标记符号:
参考:http://blog.csdn.net/zcube/article/details/42246331
@@ -AAA分支的起始行号,AAA分支的结束行号(如果之后一行逗号后面省略) +BBB分支的起始行号,BBB分支的结束行号(只有一行逗号后面省略) @@
(5)git merge AAA 表示AAA分支合并到当前分支(缺省AAA表示FETCH_HEAD分支合并到当前分支)
如果发生冲突,需要自己去文件中修改,文件中的标记如下:
<<<<<<<到=======是当前分支的文件内容,=======到>>>>>>>是合并文件的文件内容
7、栈
一般用于两种情况
(1)自己在本地上做了一些修改但由于没完成还不想提交,发现远程也做了一些修改,所以可以先把本地的修改加入到栈中,然后pull,在读出修改信息
(2)在开发中突然发现一个更重要的问题需要修改测试,可以把当前的部分没完成的工作加入到栈中
git stash 把所有unstaged和staged的文件修改加入到栈中
git stash pop 读出栈的修改(如发生冲突需要自己去修改)
git stash drop 扔掉栈中的第一条
git stash clear 清空栈
就先写到这里,其他的补充以后再添加