正则表达式:在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。
说明:只有掌握了正则表达式,才能全面地掌握 Linux 下的常用文本工具(例如:grep、egrep、GUN sed、 Awk 等) 的用法。
一、正则表达式分类:
1、基本的正则表达式(Basic Regular Expression 又叫 Basic RegEx 简称 BREs)
2、扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs)
3、Perl 的正则表达式(Perl Regular Expression 又叫 Perl RegEx 简称 PREs)
二、Linux 中常用文本工具与正则表达式的关系:
常握 Linux 下几种常用文本工具的特点,对于我们更好的使用正则表达式是很有帮助的
- grep , egrep 正则表达式特点:
1)grep 支持:BREs、EREs、PREs 正则表达式
grep 指令后不跟任何参数,则表示要使用 ”BREs“
grep 指令后跟 ”-E" 参数,则表示要使用 “EREs“
grep 指令后跟 “-P" 参数,则表示要使用 “PREs"
2)egrep 支持:EREs、PREs 正则表达式
egrep 指令后不跟任何参数,则表示要使用 “EREs”
egrep 指令后跟 “-P" 参数,则表示要使用 “PREs"
3)grep 与 egrep 正则匹配文件,处理文件方法
a. grep 与 egrep 的处理对象:文本文件
b. grep 与 egrep 的处理过程:查找文本文件中是否含要查找的 “关键字”(关键字可以是正则表达式) ,如果含有要查找的 ”关健字“,那么默认返回该文本文件中包含该”关健字“的该行的内容,并在标准输出中显示出来,除非使用了“>" 重定向符号,
c. grep 与 egrep 在处理文本文件时,是按行处理的
- sed 正则表达式特点
1)sed 文本工具支持:BREs、EREs
sed 指令默认是使用"BREs"
sed 命令参数 “-r ” ,则表示要使用“EREs"
2)sed 功能与作用
a. sed 处理的对象:文本文件
b. sed 处理操作:对文本文件的内容进行 --- 查找、替换、删除、增加等操作
c. sed 在处理文本文件的时候,也是按行处理的
- Awk(gawk)正则表达式特点
1)Awk 文本工具支持:EREs
awk 指令默认是使用 “EREs"
2)Awk 文本工具处理文本的特点
a. awk 处理的对象:文本文件
b. awk 处理操作:主要是对列进行操作
三、正则表达式:
基本组成部分
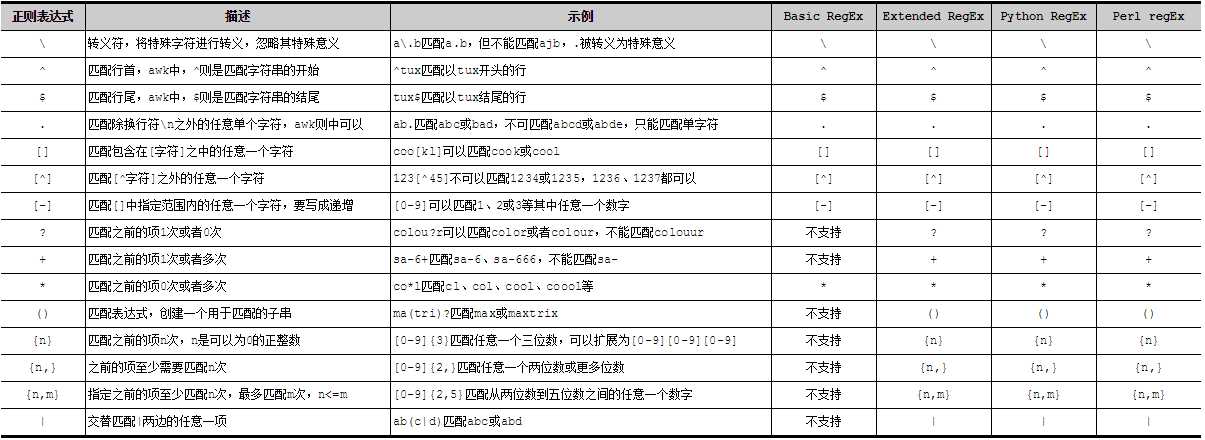
元字符
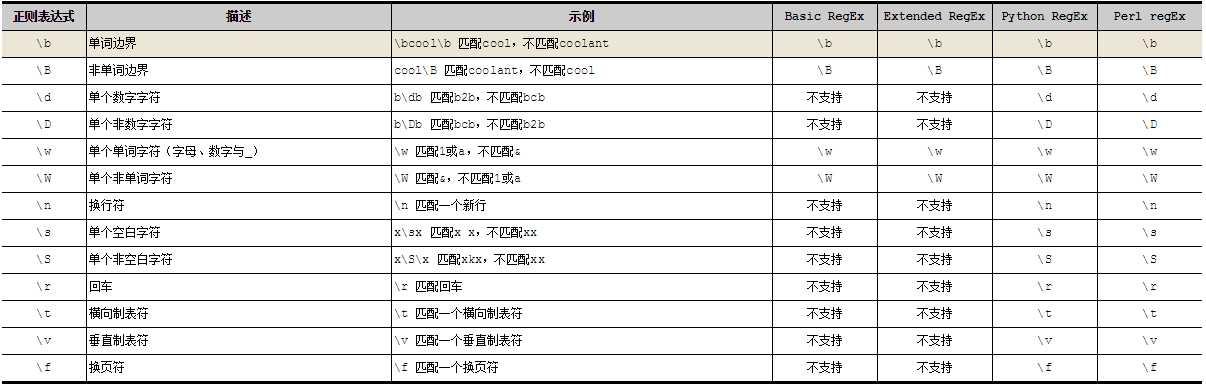
四、常用的正则表达式匹配
1、非负整数:^\d+
2、正整数:^[0-9]*[1-9][0-9]*$
3、非正整数:^((-\d+)|(0+))$
4、负整数:^-[0-9]*[1-9][0-9]*$
5、整数:^-?\d+$
6、非负浮点数:^\d+(\.\d+)?$
7、正浮点数:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)| ([0-9]*[1-9][0-9]*))$
8、非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$
9、负浮点数:^(-((正浮点数正则式)))$
10、英文字符串:^[A-Za-z]+$
11、英文大写串:^[A-Z]+$
12、英文小写串:^[a-z]+$
13、英文字符数字串:^[A-Za-z0-9]+$
14、英数字加下划线串:^\w+$
15、E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
16、URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$ 或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\‘:+!]*([^& lt;>\"\"])*$
17、邮政编码:^[1-9]\d{5}$
18、中文:^[\u0391-\uFFE5]+$
19、电话号码:^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9] \d{6,7}(\-\d{1,4})?$
20、手机号码:^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$
21、双字节字符(包括汉字在内):^\x00-\xff
22、匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)
23、匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>
24、匹配空行:\n[\s| ]*\r
25、提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *(‘|”)?(\w|\\|\/|\.)+(‘|”| *|>)?
26、提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
27、提取信息中的图片链接:(s|S)(r|R)(c|C) *= *(‘|”)?(\w|\\|\/|\.)+(‘|”| *|>)?
28、提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
29、提取信息中的中国手机号码:(86)*0*13\d{9}
30、提取信息中的中国固定电话号码:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8}
31、提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}
32、提取信息中的中国邮政编码:[1-9]{1}(\d+){5}
33、提取信息中的浮点数(即小数):(-?\d*)\.?\d+
34、提取信息中的任何数字 :(-?\d*)(\.\d+)?
35、IP:(\d+)\.(\d+)\.(\d+)\.(\d+)
36、电话区号:/^0\d{2,3}$/
37、腾讯QQ号:^[1-9]*[1-9][0-9]*$
38、帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
39、中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$