Hadoop架构的初略总结(2)
回顾一下前文,我们总结了以下几个方面。我们为什么需要Hadoop;Hadoop2.0生态系统的构成;Hadoop1.0中HDFS和MapReduce的结构模型。
我们大致了解了1.0,现在我们来说说2.0。
首先,我们需要理清以下几个问题:
1.Hadoop1.0自身有哪些缺陷呢?
解:从两个大的方面来说,HDFS和MapReduce。
HDFS:
1) NameNode中的单点故障问题。
针对Hadoop1.0中HDFS单点故障进行以下解释:
HDFS仿照google GFS实现的分布式存储系统,由NameNode和DataNode两种服务组成,其中NameNode是存储了元数据信息(fsimage)和操作日志(edits),由于它是唯一的,其可用性直接决定了整个存储系统的可用性。因为客户端对HDFS的读、写操作之前都要访问name node服务器,客户端只有从name node获取元数据之后才能继续进行读、写。一旦NameNode出现故障,将影响整个存储系统的使用。
这里需要提到一点,在Hadoop架构的初略总结(2)中提到的SecondaryNameNode,其作用合并NameNode节点中的fsimage和edits。首先,SecondaryNameNode从NameNode中通过网络拷贝一份fsimage(元数据信息)与edits(操作日志)到自己进程的那一块,然后将fsimage与edits进行合并,生成新的fsimage,并将新生成的fsimage推送到NameNode节点中一份,并将NameNode中edits的内容进行清空。
2) 不能进行大量的小文件存取(占用namenode大量内存,浪费磁盘空间)扩展性差。也就是说,Hadoop1.0单NameNode制约HDFS扩展性,因为NameNode含有我们用户存储文件的全部的元数据信息,当我们的NameNode无法在内存中加载全部元数据信息的时候,集群的寿命就到头了,NameNode内存大小限制了从节点的个数,大体为4000个节点个数。
3) 其它缺陷:HDFS中的权限设计不够彻底,即HDFS的数据隔离性不是很好;数据丢失问题,访问效率问题。
改进:略。(了解了一下,看不懂,暂且略过吧,现阶段这不是重点)
MapReduce:
1) 扩展性:集群最大节点数4000(也就是4000节点主机上线);最大并发任务数40000。
2) 可用性,可靠性:JobTracker同时管理作业的调度和计算,在Hadoop1.0中,假设有100个作业,根据Hadoop访问和更新的特性,批处理,一次写入多次读写,JobTracker会同时管理这100个作业,负担太重。其次,存在单点故障,一旦故障,所有执行的任务全部失败。
3) 批处理模式,时效低:仅仅使用MapReduce一种计算方式。
4) 其他缺陷:低效的资源管理。在Hadoop1.0中不支持多框架。
2.说完Hadoop1.0的缺陷,我们来说说Hadoop2.0,Hadoop2.0生态系统的构成在前篇博客中有所提到。这里,我们从以下几个方面进行了解。
解:
在Hadoop2.0中,针对HDFS1.0中NameNode的内存容量不足以及NameNode的单点故障问题,在2.0中分别作了以下的改进:
- 在1.0中,既然一个NameNode会导致内存容量不足,我们引入两个NameNode,组成HDFS联邦,这样NameNode存储的元数据信息就可以翻倍了,所谓HDFS联邦就是有多个HDFS集群同时工作,数据节点DataNode存储的数据是服务于两个HDFS文件系统的,体系结构如下图所示:
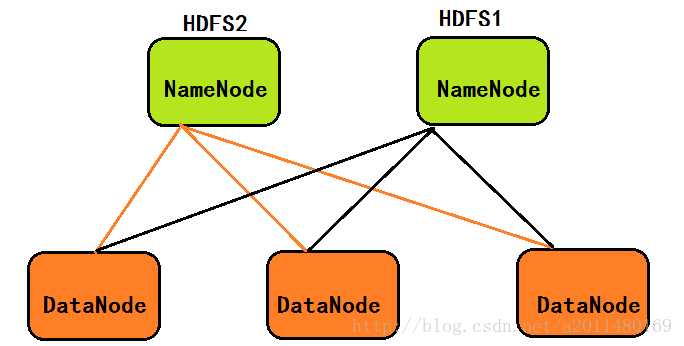
- 在2.0中,针对1.0中NameNode的单点故障问题,在2.0中引入了新的HA机制:即如果Active(活跃的)的NameNode节点挂掉,处于Standby(备份的)的NameNode节点将替换掉它继续工作,下面的图示方便大家的理解:
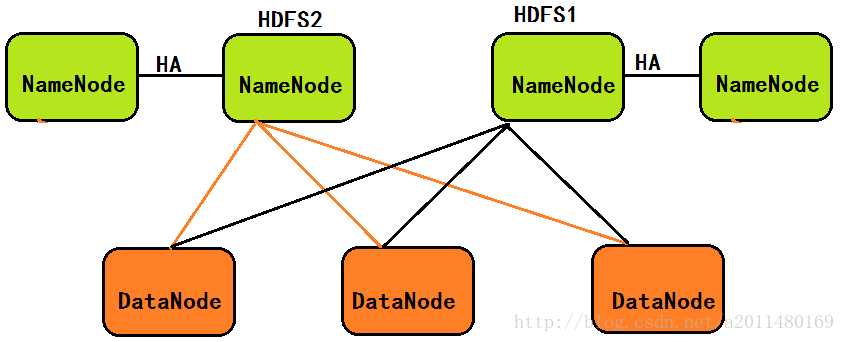
在这里大家一定要注意:2.0中处于HDFS联邦的也是两个NameNode节点,处于HA的也是两个NameNode节点,但是联邦中的两个NameNode节点由于使用的是不同的命名空间(Name Space),因此两个NameNode节点存储的元数据信息并不相同,但是处于HA中的两个NameNode节点由于使用的相同的命名空间,因此两个NameNode节点存储的元数据信息是相同的。
了解了Hadoop2.0中针对Hadoop1.0中HDFS缺陷而改进的联邦和HA,下面了解下MRv1和MRv2。
MRv1和MRv2在前文博客 Hadoop第三课中有所讲解,这里就不重复了。
接下来,了解下在博客Hadoop第三课中提到的HDFS Federation 。
作为这方面的小白,上网搜索了下,有位前辈写的浅显易懂,从很大层次上解决了我的问题。
http://blog.csdn.net/androidlushangderen/article/details/52135506
同样,我们要了解ResourceManager、ApplicationMaster以及Map Task和Reduce Task,这些就不得不说Hadoop2.0中的YARN了。
参考文献:
http://blog.csdn.net/a2011480169/article/details/53647012
https://www.cnblogs.com/sxt-zkys/archive/2017/07/24/7229857.html