虚拟化:
计算机:CPU,memory,IO(disk networkk),...
emulation:纯软件方式实现 //模拟
virtulation:把硬件功能分割成多份//拥有一个VMM进行管理分配
完全虚拟化:full-virt
半虚拟化:para-virt
完全虚拟化:
【v1.user】
【v1.ker 】
===========================
|内核| 用户空间|
| | 【硬件】
V1发起的特权指令,不能直接操作硬件//否则会影响其他虚拟机或者物理机
完全虚拟化: 软件模拟特权指令:例如VMM捕获关机指令,关闭虚拟机程,而非物理机
guest不需要任何修改,并且guest认为自己运行在物理平台上
GUEST 在ring 1,host os运行在ring 0半虚拟化:
【v1.user】
【v1.ker】
hyper call //管理单个虚拟机自身的系统调用,对system call进行的重新修改封装
=============================
|内核| 用户空间|
| | 【硬件】
半虚拟化:guest os的内核需要进行修改,知道自己运行在虚拟环境中
需要运行特权指令的时候,向物理机发起请求。发起hyper call调用硬件辅助虚拟化HVM:
早期的CPU是不支持虚拟化的,因为本身性能就很一般,虚拟化的问题更是不敢想象
后期对x86 CPU进行了修改
引入了ring -1 //宿主机的kernel运行在ring -1
guest的kernel运行在ring 0上
CPU: ring -1
Intel:intel vt-x
AMD:amd-v注意:为了区分,host指代为宿主机,guest指代为虚拟机
x86架构CPU敏感指令和特权指令的虚拟化。
使用二进制翻译的全虚拟化; //不需要修改guest os。guest不知自己运行在虚拟环境中,系统敏感指令的调用陷入后再进行二进制翻译。
操作系统辅助或半虚拟化; //需要修改host os
硬件辅助的虚拟化(第一代); //HVM
如图
1.二进制翻译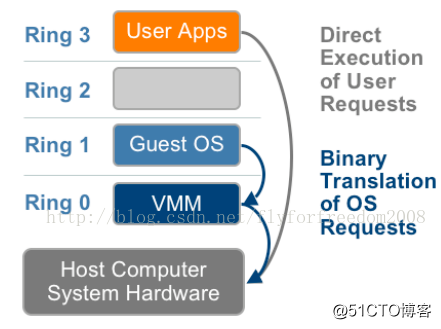
异常 “捕获(trap)-翻译(handle)-模拟(emulate)” 过程:
2.操作系统辅助或半虚拟化;
虚拟机系统和hypervisor通过交互来改善性能和效率。
涉及到修改操作系统内核来将不可虚拟化的指令替换为直接与虚拟化层交互的超级调用(hypercalls)
hypervisor同样为其他关键的系统操作如内存管理、中断处理、计时等提供了超级调用接口。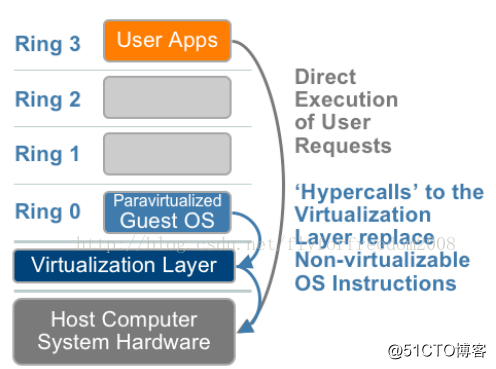
XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。
这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。windows不能需改代码。
3.HVM
VMM运行在ring 0,同时在新增的根模式下。如图7所示,特权和敏感调用自动陷入hypervisor,不再需要二进制翻译或半虚拟化。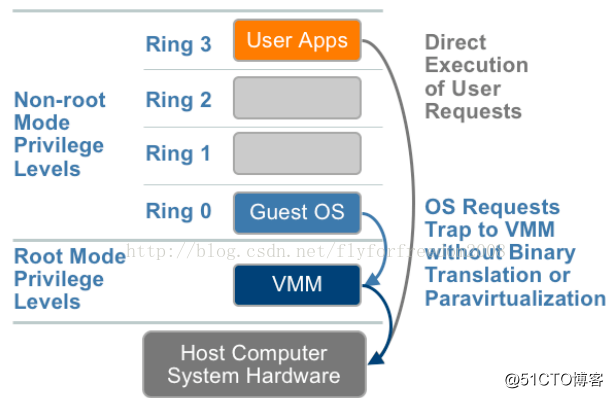
时间片
环:ring0-3
ring 0:特权指令 //内核运行
ring 3:非特权指令 //进行使用的
//进行执行特权指令,需要模式切换,进程运行在用户空间,内核运行在内核空间
软中断:CPU停止执行用户空间代码,转而执行内核代码
CPU三种虚拟化对比图:
图:对比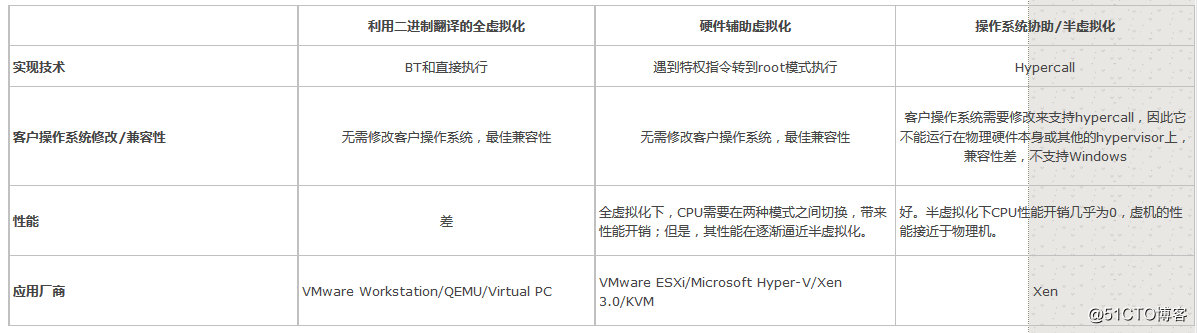
内存在宿主机上已经虚拟化一次了
进程的地址空间:线性地址空间
内存:分割成page,把page映射到进程空间中,每个进程都假设自己有3G(32bit os)可用
进程真实使用的并没有那么多,而且多个进程之间有共享库,而且这些内容都是共享的
MMU:负责线性地址和物理地址映射
内存的虚拟化是最复杂的:再次对内存进行虚拟化:显然不划算
MMU负责转换,TLB负责缓存hit
MMU的虚拟化:
INTEL:EPT,Extended Page Table
AMD:NTP,Nested Page Table
TLB的虚拟化:提高命中率
tagged TLB图:mem 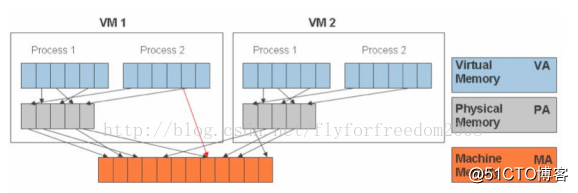
VMM负责将虚拟机物理内存映射到真实的机器内存,并使用影子页表来加速映射过程。
VMM负责将虚拟机物理内存映射到真实的机器内存,并使用影子页表来加速映射过程。
VMM使用硬件中的TLB来直接映射虚拟内存到机器内存以避免每次访问时需要两级转换。当虚拟机改变了虚拟内存到物理内存的映射时,VMM更新影子页表使得后续可以直接查找。
示例:硬盘
模拟:把一个文件当做硬盘来使用
在文件之上附加一层驱动程序,或者附加一个软件,进程通过该 软件/驱动 访问该文件的时候,看到的是一个硬盘
稀疏格式:用多少占用多少,但是看到的是120G
模拟的是IO控制器,让进程看到
IO控制器 //模拟实现,模拟控制器是虚拟机的内核使用的
-------------
【文件[] 】disk //disk具有自己的控制器,host.kernel驱动使用
文件虚拟机进程写入文件:
guest.user-->guest.kernel调度system call-->驱动程序[虚拟的]--->
host.user--->host.kernel-->host.driver--->host的控制器写入 //驱动物理程序
IO设备多数只能模拟
优化方法:
半虚拟化:guest知道自己运行在内核
host.kernel[调度接口]-->物理机的系统调用--->host.driver-->host.控制器写入
IO透传技术
为虚拟机分配独立物理硬盘,例如独立一个硬盘共一个guest使用
IO虚拟化实现方案:
模拟:完全使用软件模拟真实硬件
半虚拟化
IO透传技术:让虚拟机直接使用物理设备,几乎接近于硬件性能,硬件必须要支持透传技术
虚拟和模拟:
虚拟:要求guest.kernel和host.kernel一致,用以提高性能
只需要捕获特权指令,其他非特权指令,直接在CPU上运行即可
模拟:可以不一致,需要进行翻译
需要捕获所有指令,翻译执行
显示设备:
VGA:frame buffer机制===================================
完全虚拟化 半虚拟化
[v1][v2][v3] [v1]
【OS 】 【VMM 】
【硬件 】 【硬件 】
完全虚拟化:host之上的vmm之上guest
半虚拟化:vmm之上的guest
半:VMM需要管理硬件,驱动所有硬件//硬件种类非常多,驱动也需要非常多
需要在虚拟机系统安装虚拟化管理程序和设备驱动,但数据中心必须权衡减少虚拟化代价的优势和运行一个经过修改的虚拟机系统内核来使能半虚拟化所需要的支持维护成本。
xen:半虚拟化和全虚拟化
hypervisor,直接运行在硬件上,xen只驱动cpu和内存,每个guest.kernel都要修改
其他IO设备由host0进行驱动
步骤:硬件:host.OS-->xen[修改OS内核]->重启后,启动的是xen而不再是host.OS
鸠占鹊巢:xen会把host当做虚拟机启动。
每一个虚拟机称为一个domain,domain0是特权域
domain 0对其他虚拟机进行管理,负责驱动IO设备,拥有部分特权
dom 0、dom u
============
xenkvm:全虚拟化,也称为HVM硬件辅助虚拟化,因为需要cpu支持//Intel CPU和具有AMD-V功能的AMD CPU。
红帽之前宠爱xen,红帽后期收购了kvm,后期大力研发kvm
kvm:kernel-base virtual machine
后期redhat不再支持xen,rhel6.x版本中需要自行编译内核,使用xen
xen不敢落后,做好rpm包,提供给centos社区,后来centos被rh收购,RH继续冷落xen,虽然现在不再打压xen了,但是xen显然已经没有那么流行了
kvm变成了内核模块,一旦内核装载了该模块,内核立马被kvm控制,成为hypervisor
原有的内核空间和用户空间变成了虚拟机的控制台,kvm自身既不驱动cpu,也不驱动内存,完全寄生的方式,感染别人。
kvm腐蚀了内核之后,可以为每一个虚拟机虚拟一个cpu和内存,但是不能虚拟出来io设备,借助于qemu-kvm实现
kvm//寄生host.kernel,成为hypervisor
性能:大多数Xen和KVM性能基准的对比都表明Xen具有更好的处理性能(接近于本地处理),
只有在磁盘 I/O方面略逊于KVM。进一步来讲,独立测试表明随着工作负载的增加KVM的性能逐渐下降。
通常情况下,在试图支持四个以上的客体虚拟机时就会崩溃。
Xen支持一个客体虚拟机的数量呈线性增长,可以支持30个以上工作负载同时运行。
Xen:最大的弊端是恰好是Dom0 不能用最新的kernel,需要手动编译
kvm虚拟化cpu和内存,qemu模拟io
【qemu/domain 0】 [v2] [v3]
-----------------------------
【 内核 】
硬件
//v2和v3可以直接访问cpu和内存
访问IO的时候,需要先到domain 0=>内核=>IO硬件
kvm要求cpu必须支持虚拟化,xen没有要求,但要对每一个虚拟机的内核进行修改
xen:半虚拟化
kvm:硬件虚拟化CPU之上容器级别虚拟化//用户空间虚拟化
xen和kvm的目的是为了提供隔离的环境
容器虚拟化也能满足 //在内核级别资源隔离
每个容器就像直接运行在内核之上。
弊端:
1.隔离性能不是很好。虽然没有虚拟机彻底,
2.容器的接口使用不便,
一个容器就是一个独立的用户空间
内核需要支持
1.控制组cgroup
2.名称空间技术虚拟化简史:
虚拟化技术分类:
主机虚拟化
主机虚拟化
完全虚拟化:vmware workstation,kvm,xen(hvm)
半虚拟化:xen,uml
模拟:qemu
用户空间虚拟化(容器)
lxc(linux container),openVZ,solaris containers,FreeBSD jails
docker,
库级别虚拟化:wine,Cywin
应用程序虚拟化:jvm,pvm,...
KVM是基于虚拟化扩展(Intel VT 或者 AMD-V)的 X86 硬件的开源的 Linux 原生的全虚拟化解决方案。
KVM中,虚拟机被实现为常规的 Linux 进程,由标准 Linux 调度程序进行调度;
虚机的每个虚拟 CPU 被实现为一个常规的Linux线程。这使得KVM能够使用Linux内核的已有功能。
KVM 本身不执行任何硬件模拟,需要用户空间程序通过 /dev/kvm 接口设置一个客户机虚拟服务器的地址空间,向它提供模拟 I/O,并将它的视频显示映射回宿主的显示屏。目前这个应用程序是 QEMU。
图:kvm架构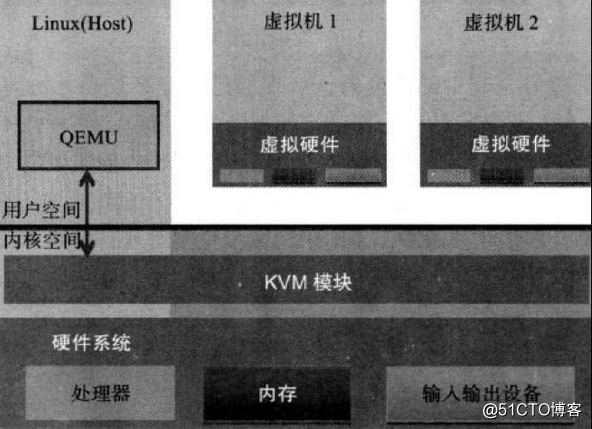
Guest:客户机系统,包括CPU(vCPU)、内存、驱动(Console、网卡、I/O 设备驱动等),被 KVM 置于一种受限制的 CPU 模式下运行。
KVM:运行在内核空间,提供 CPU 和内存的虚级化,以及客户机的 I/O 拦截。Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理。
QEMU:修改过的被 KVM 虚机使用的 QEMU 代码,运行在用户空间,提供硬件 I/O 虚拟化,通过 IOCTL /dev/kvm 设备和 KVM 交互。
Qemu-KVM:纯软件实现的虚拟化系统,主要用于实现IO虚拟化,
VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。当虚机进行 I/O 操作时,KVM 会从上次系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。
除此以外,虚机的配置和创建、虚机运行所依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
KVM模块按需加载到kernel中,KVM 本身不执行任何设备模拟,需要 QEMU 通过 /dev/kvm 接口设置一个 GUEST OS 的地址空间,向它提供模拟的 I/O 设备,并将它的视频显示映射回宿主机的显示屏
KVM模块加载过程:
1.首先初始化内部的数据结构;
2.做好准备后,KVM 模块检测当前的 CPU,然后打开 CPU 控制及存取 CR4 的虚拟化模式开关,并通过执行 VMXON 指令将宿主操作系统置于虚拟化模式的根模式;
3.最后,KVM 模块创建特殊设备文件 /dev/kvm 并等待来自用户空间的指令。
后面需要KVM和QEMU交互完成,两者的通信接口是/dev/kvm的IOCTL调用,
在非根模式下,所有敏感的二进制指令都被CPU捕捉到,CPU 在保存现场之后自动切换到根模式,由 KVM 决定如何处理。
CPU 中的内存管理单元 MMU 是通过页表的形式将程序运行的虚拟地址转换成实际物理地址。在虚拟机模式下,MMU 的页表则必须在一次查询的时候完成两次地址转换。因为除了将客户机程序的虚拟地址转换了客户机的物理地址外,还要将客户机物理地址转化成真实物理地址。
虚拟化技术两种类型
type I:
hypervisor-->vm
type II:
host-->vmm-->vm //virtual machine monitor
kvm: kernel-based virtual machine,Qumranet公司,后来被redhat收购
依赖于HVM机制:
intel: VT-x,flags:(vmx)
cat /proc/meminfo
AMD: AMD-v :(svm)
在vmware启动的时候:设置-->处理器-->虚拟化引擎[intel VT-x/EPT or AMD-V/RVI]
//EPT和RVI是mmu虚拟化
QEMU:主要提供了以下几个组件:
处理器模拟器:
仿真IO设备
关联模拟设备到真实设备
提供调试器
提供与模拟器交互的接口
内核模块:kvm专用于x86架构的cpu
kvm//核心模块,必须安装
kvm-intel,kvm-amd //选择模块,选择一个即可
内核一旦装载kvm,内核成为hypervisor,原有的OS将成为domain 0
domain 0负责提供管理控制台,以及IO设备模拟
domain u访问IO设备需要-->domain 0--->IO设备 //domain u有自己的内核空间和用户空间
domain u访问memory或者cpu-->内存中的kvm模块 //访问/dev/kvm管理接口即可
KVM模块载入后系统的运行模式:
内核模式:GuestOS执行I/O类操作,或其他的特殊指令操作;称为”来宾-内核“模式;
用户模式:代表GuestOS请求I/O操作"host-user"; //domain 0,原有的OS的用户模式
来宾模式:GuestOS的非IO类操作;即“来宾-用户“模式
kvm hypervisor:原来的内核模式"host-kernel"
kvm组件:
两类组件:
1./dev/kvm 接口:工作于hypervisor,在用户空间可通过ioctl() 系统调用来完成vm的管理工作,是一个字符设备
功能:
创建vm,为vm分配内存,读写vcpu的寄存器,向vcpu注入中断,以及运行vcpu等。
2.qemu进程:工作于用户空间,主要用于实现模拟vm的IO设备;
| [guest.Memory] | [VCPU ][VCPU ] | ============= | ||
|---|---|---|---|---|
| thread thread | //hypervisor process | |||
| ----- | ------ | ---------------- | ||
| ===== | ====== | ================ | ||
| [k v m] linux kernel |
=====V======V================
CPU CPU CPU
//每一个虚拟机运行起来,就是一个hypervisor进程,该进程内部有很多线程,用于实现其他功能。
虚拟机的每一个cpu[vcpu],使用一个线程模拟内存管理:
将分配给VM的内存交换到SWAP
支持使用大内存页huge page;//默认每个page 4k
支持使用intel EPT或AMD RVI技术实现内存地址映射,mmu虚拟化
inte EPT/amd RVI//直接映射虚拟机的内存到物理机的内存,否则会需要两级映射,效率较低
MMU虚拟化
TLB虚拟化:缓存转换的结果 //每一个guest的线性空间和物理地址空间的映射都是独立的
在每一个tlb之前添加一个标记,说明是第几个guest的tlb
GVA--->GPA-->HPA, GVA-->HPA
支持KSM(kernel sample-page Merging) //内核相同页面合并
硬件支持:
取决于Linux内核;linux能够驱动的硬件,kvm都能使用
存储:
本地存储;
网络附加存储;
存储区域网路;
分布式存储;GlusterFS等
实时迁移:
live migration //虚拟机不关机,从一个物理机到另外一个物理机上运行
依赖于共享存储实现,//两个物理机之间使用共享存储
支持Guest OS:
linux,windows,OpenBSD,FreeBSD,OpenSolaris
设备驱动:
I/O设备的完全虚拟化:模拟硬件
IO设备的半虚拟化;virto //通用虚拟化技术
virtio-blk,virtio-net,virtio-pci,vitio-console,virtio-ballon[气球]//对内存大小实时调整KVM 所支持的功能包括:
支持 CPU 和 memory 超分(Overcommit)
支持半虚拟化 I/O (virtio)
支持热插拔 (cpu,块设备、网络设备等)
支持对称多处理(Symmetric Multi-Processing,缩写为 SMP )
支持实时迁移(Live Migration)
支持 PCI 设备直接分配和 单根 I/O 虚拟化 (SR-IOV)
支持 内核同页合并 (KSM )
支持 NUMA (Non-Uniform Memory Access,非一致存储访问结构 )
1.Qemu:
qemu-kvm //专用于管理kvm
qemu-img
qemu-io
在Guest上运行qumu进程
qemu-kvm是qemu项目的一个分支,专用于管理kvm,到1.3.0合并到了qemu上
qemu是支持xen和kvm的,但是qemu-kvm是仅仅支持kvm的
2.libvirt=libvirtd: //运行libvirtd服务
libvirt:virsh
libvirt:virtinst //工具包
virt-install
virt-clone
virt-convert
virt-image
libvirt:virtual Machine manager //图形化工具
virt-manager
virt-viewer //python研发的图形界面
//C/S架构,后期 KVM联合其他厂商开发的
创建虚拟机的方式;
qemu
Virtual Machine Manager
virtinst
查看和管理工具
qemu-kvm
virsh libvirt能够管理xen和kvm,通用,现在对xen支持不太好,因为redhat
参考博客: http://www.cnblogs.com/sammyliu/p/4543110.html
原文地址:http://blog.51cto.com/hmtk520/2088221