事务是将一系列操作作为一个单元执行,要么成功,要么失败,回滚到最初状态。在事务处理术语中,事务要么提交,要么中止。若要提交事务,所有参与者都必须保证对数据的任何更改是永久的。不论系统崩溃或是发生其他无法预料的事件,更改都必须是持久的。只要有一个参与者无法做出此保证,整个事务就会失败。事务范围内的所有数据更改将回滚到特定设置点。
事务将多个操作紧密联系到一起,这样就能保证有联系的两种操作的一致性、以及数据的完整性。
事务的误区
事务有很多优点【原理中已经阐述】,由于它的要求比较高,所以注意事务不能滥用,如果用不好就会造成很大的麻烦。
事务有一个开头和一个结尾,它们指定了事务的边界,事务在其边界之内可以跨越进程和计算机。事务边界内的所有资源都参与同一个事务。要维护事务边界内资源间的一致性,事务必须具备 ACID 属性,即原子性、一致性、隔离性和持续性。这是MSDN的权威说明。
也许针对一般的小逻辑、小数据事务应用非常的高效、可靠。但如果数据量很大,在单个事务中集合的操作繁多而且复杂,事务的致命伤就会暴露出来。一个事务进行时,必须保证边界资源的原子性、一致性、隔离性和持续性。
我曾经设计了一个测试用例,测试事务在执行时对资源的利用情况。测试结果很令人惊讶:在事务执行时,独占事务涉及到的数据表,造成其它操作词表的功能,因等待时间过长,而暴跳“获得数据连接超时”的警告。
语法步骤:
开始事务:BEGIN TRANSACTION --开启事务
事务提交:COMMIT TRANSACTION --提交操作
事务回滚:ROLLBACK TRANSACTION --取消操作
/*
如果只有Begin TransAction和Commit TransAction 就算报错了,也是不会回滚的
Select * From Person
*/
Begin TransAction
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘3‘,‘Name3‘)
Commit TransAction
/*
如果只有Begin TransAction和RollBack TransAction 就算没报错了,还是会回滚的
Select * From Person
*/
--清除数据
Delete Person
Begin TransAction
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘3‘,‘Name3‘)
RollBack TransAction
/*
SET XACT_ABORT ON时,在事务中,若出现错误,系统即默认回滚事务,但只对非自定义错误有效
SET XACT_ABORT OFF,默认值,在事务中,回滚一个语句还是整个事务视错误的严重程序而定,
用户级错误一般不会回滚整个事务
Select * From Person
*/
SET XACT_ABORT ON -- 打开
Begin TransAction
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘3‘,‘Name3‘)
Commit TransAction
SET XACT_ABORT OFF -- 关闭
/*
Try Catch 配合事务使用
Select * From Person
*/
Begin Try
Begin TransAction
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
Insert Into Person(PersonId,PersonName)Values(‘3‘,‘Name3‘)
Commit TransAction
End Try
Begin Catch
Rollback TransAction
End Catch
/*
使用全局变量@@Error 配合事务使用
Select * From Person
*/
DECLARE @tran_error int;
SET @tran_error = 0;
Begin TransAction
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
SET @tran_error = @tran_error + @@ERROR;
print(@tran_error);
Insert Into Person(PersonId,PersonName)Values(‘1‘,‘Name1‘)
SET @tran_error = @tran_error + @@ERROR;
print(@tran_error);
Insert Into Person(PersonId,PersonName)Values(‘3‘,‘Name3‘)
SET @tran_error = @tran_error + @@ERROR;
print(@tran_error);
IF(@tran_error > 0)
BEGIN
--执行出错,回滚事务
ROLLBACK TransAction;
END
ELSE
BEGIN
--没有异常,提交事务
COMMIT TransAction;
END
事务的特性(ACID):
- 原子性(atomicity):一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
操作事务的基本步骤:
- 开启事务:开启事务以后,我们以后的所有操作将都会在同一个事务当中
- 操作数据库:开启事务以后再去操作数据库,所有操作将不会直接提交到数据库中
- 提交事务:将修改应用到数据库
- 回滚事务:数据库操作过程中出现异常了,回滚事务,回滚事务以后,数据库变成开启事务之前的状态
mysql中的事务控制
- 开启事务:START TRANSACTION
- 提交事务:COMMIT
- 回滚事务:ROLLBACK
JDBC中的事务主要通过Connection对象来控制的
- 开启事务
- void setAutoCommit(boolean autoCommit) throws SQLException;
- //设置事务是否自动提交,默认是自动提交
- //设置事务手动提交
- conn.setAutoCommit(false);
- //提交事务
- void commit() throws SQLException;
- //提交事务
- conn.commit()
- 回滚事务
- void rollback() throws SQLException;
- //回滚事务
- conn.rollback()
事务控制的格式:
Connection conn = null;//创建一个Connection
try{
conn = JDBCUtils.getConnection();//获取Connection
conn.setAutoCommit(false);//开启事务
//对数据库进行操作
conn.commit();//操作成功,提交事务
} catch(Exception e){
e.printStackTrace();
//回滚事务
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
} finally{
DBUtil.close(conn, null, null);
}
注意:在同一个事务中使用的数据库连接(Connection)必须是同一个,否则事务不起作用!
//StudentDao类 public static int updateAccount(Connection conn,Integer id,Integer account) { PreparedStatement ps = null; String sql = "update student set account=account+? where id=?"; int i = 0; try { ps = conn.prepareStatement(sql); ps.setInt(1, account); ps.setInt(2, id); i = ps.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } finally{ DBUtil.close(null, ps, null); } return i; } //测试类 @Test public void testTransaction() { Connection conn = DBUtil.getConn();//获取连接Connection try { conn.setAutoCommit(false);//开启事务 StudentDao.updateAccount(conn, 1, -100); int i=10/0; StudentDao.updateAccount(conn, 2, 100); conn.commit();//操作成功,提交事务 } catch (SQLException e) { e.printStackTrace(); //回滚事务 try { conn.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } } finally{ DBUtil.close(conn, null, null); } }
int i=10/0; 处抛出了错误,但是事务没有提交,并进行了回滚,所以数据库中的数据没有变,运行正常的话,可以进行正常转账。
批处理和事务的结合:实际开发中,批处理和事务常常是结合在一起使用。速度会成倍增加
@Test public void testTransBatch() { Connection conn = DBUtil.getConn(); PreparedStatement ps = null; try { conn.setAutoCommit(false);//开启事务 String sql = "INSERT INTO student(NAME) VALUES(?)"; try { ps = conn.prepareStatement(sql); for (int i = 0; i < 1000; i++) { ps.setString(1, "stu"+i); ps.addBatch(); } long start = System.currentTimeMillis(); ps.executeBatch(); long end = System.currentTimeMillis(); System.out.println((end-start)+"ms"); } catch (SQLException e) { e.printStackTrace(); } conn.commit();//提交事务 } catch (SQLException e) { //回滚事务 try { conn.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } e.printStackTrace(); } finally{ DBUtil.close(conn, ps, null); } }
在.net 1.1的时代,还没有TransactionScope类,因此很多关于事务的处理,都交给了SqlTransaction和SqlConnection,每个Transaction是基于每个Connection的。这种设计对于跨越多个程序集或者多个方法的事务行为来说,不是非常好,需要把事务和数据库连接作为参数传入。
在.net 2.0后,TransactionScope类的出现,大大的简化了事务的设计。
static void Main(string[] args)
{
using (TransactionScope ts = new TransactionScope())
{
userBLL u = new userBLL();
TeacherBLL t = new TeacherBLL();
u.ADD();
t.ADD();
ts.Complete();
}
}
只需要把需要事务包裹的逻辑块写在using (TransactionScope ts = new TransactionScope())中就可以了。从这种写法可以看出,TransactionScope实现了IDispose接口。除非显示调用ts.Complete()方法。否则,系统不会自动提交这个事务。如果在代码运行退出这个block后,还未调用Complete(),那么事务自动回滚了。在这个事务块中,u.ADD()方法和t.ADD()方法内部都没有用到任何事务类。
TransactionScope是基于当前线程的,在当前线程中,调用Transaction.Current方法可以看到当前事务的信息。具体关于TransactionScope的使用方法,已经它的成员方法和属性,可以查看 MSDN 。
TransactionScope类是可以嵌套使用,如果要嵌套使用,需要在嵌套事务块中指定TransactionScopeOption参数。默认的这个参数为Required。
static void Main(string[] args)
{
using (TransactionScope ts = new TransactionScope())
{
Console.WriteLine(Transaction.Current.TransactionInformation.LocalIdentifier);
userBLL u = new userBLL();
TeacherBLL t = new TeacherBLL();
u.ADD();
using (TransactionScope ts2 = new TransactionScope(TransactionScopeOption.Required))
{
Console.WriteLine(Transaction.Current.TransactionInformation.LocalIdentifier);
t.ADD();
ts2.Complete();
}
ts.Complete();
}
}
当嵌套类的TransactionScope的TransactionScopeOption为Required的时候,则可以看到如下结果,他们的事务的ID都是同一个。并且,只有当2个TransactionScope都complete的时候才能算真正成功。
如果把TransactionScopeOption设为RequiresNew,则嵌套的事务块和外层的事务块各自独立,互不影响。
TransactionScopeOption设为Suppress则为取消当前区块的事务,一般很少使用。
对于多个不同服务器之间的数据库操作,TransactionScope依赖DTC(Distributed Transaction Coordinator)服务完成事务一致性。
但是对于单一服务器数据,TransactionScope的机制则比较复杂。主要用的的是线程静态特性。线程静态特性ThreadStaticAttribute让CLR知道,它标记的静态字段的存取是依赖当前线程,而独立于其他线程的。既然存储在线程静态字段中的数据只对存储该数据的同一线程中所运行的代码可见,那么,可使用此类字段将其他数据从一个方法传递到该第一个方法所调用的其他方法,而且完全不用担心其他线程会破坏它的工作。TransactionScope 会将当前的 Transaction 存储到线程静态字段中。当稍后实例化 SqlCommand 时(在此 TransactionScope 从线程局部存储中删除之前),该 SqlCommand 会检查线程静态字段以查找现有 Transaction,如果存在则列入该 Transaction 中。通过这种方式,TransactionScope 和 SqlCommand 能够协同工作,从而开发人员不必将 Transaction 显示传递给 SqlCommand 对象。实际上,TransactionScope 和 SqlCommand 所使用的机制非常复杂。
传统SqlTransaction事务和TransactionScope事务
C#——细说事务(上)
一、事务的定义
显式事务:明确指定事务的开始,connection需要打开方可使用,默认为closed,即:显示调用con.BeginTransaction()
隐式事务:无法明确指定事务的开始,默认connection已被打开为open
分布式隐式事务:使用TransactionScope类
分布式显式事务:使用CommittableTransaction类,con.EnlistTransaction(Transaction对象)//将连接登记到事务
一个事务性操作的环境下,操作有着以下的4种特性,被称为ACID特性
| 原子性(Atomicity) | 当事务结束,它对所有资源状态的改变都被视为一个操作,这些操作要不同时成功,要不同时失败 |
| 一致性(Consistency) | 操作完成后,所有数据必须符合业务规则,否则事务必须中止 |
| 隔离性(Isolation) | 事务以相互隔离的方式执行,事务以外的实体无法知道事务过程中的中间状态 |
| 持久性(Durable) | 事务提交后,数据必须以一种持久性方式存储起来 |
二、事务管理器
在软件系统当中可以看到无论在数据库、Web服务、WCF、文件系统都存在着数据参与到事务运作当中,我们把管理这些数据的工具称为资源管理器 RM(Resources Manager)。而事务管理器TM(Transaction Manager)就是协调多个资源管理器的工作,保证数据完整性的工具。
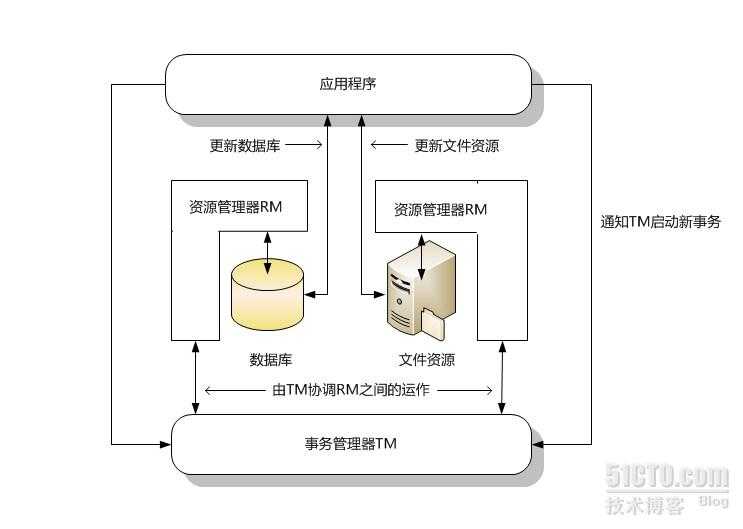
由上图可以看到事务的管理流程,系统通知事务管理器TM来启动事务,事务管理器TM控制向多个资源管理器RM并协调RM之间的事务操作。图中存在两个持久化RM,分别管理数据库和文件系统,这些事务操作要不同时成功,要不同时失败。
事务管理器一般分为三类:轻量级事务管理器(LTM)、核心事务管理器(KTM)、分布式事务协调器(DTC)
1. 轻量级事务管理器 (LTM)
它 是包括在System.Transactions 命名空间内的一个事务管理框架,它只能管理单个应用程序域内的事务。LTM 可以管理多个易变的RM,但只能管理一个持久化RM。若事务试图加入第二个持久化RM,那轻量级事务管理器LTM将提升级别。LTM是性能最高的事务管理 器,在可选择的情况下应该尽可能地使用 LTM 事务管理器。
这里易变RM是指它参与会引发 “未确定状态” 的2PC事务时候,不需要恢复服务,更多时候,易变RM的数据只存储在内存当中。
而持久化RM是指它参与会引发 “未确定状态” 的2PC事务时候,它需要恢复服务,持久化RM管理的数据是在于硬盘当中。所以,参与2PC事务的的持久RM必须有新旧两个版本,如果事务引发 “未确定状态” 的时候,那么它就会联系持久化RM,恢复到其中一个版本。
2PC 是2 Phase Commit的缩写,代表事务的2阶段提交验证算法:在数据提交时,第一阶段:应用程序记录每个数据源并执行更新请求,TM通知每个RM来执行分布式事 务,然后每个RM都对数据执行本地的事务,在事务将提交前,TM会与各个RM进行信息交换,以获知更新是否成功。第二阶段,如果其中任何一个RM表示更新 失败,TM就会通知所有的RM事务操作失败,实现数据回滚。如果所有RM的操作都成功,那么整个TM事务就宣告成功。
2. 核心事务管理器 (KTM)
KTM是用于Windows Vista和Windows Server 2008 系统中的轻量级事务管理器,与LTM相像,它可以管理多个易变的RM,但只能管理一个持久化RM。
3. 分布式事务协调器(DTC)
分 布式事务协调器DTC(Distributed Transaction Coordinator)能管理多个持久化RM中的事务,事务可以跨越应用程序域、进程、硬件、域等所有的边界。在Windows Server 2008当中,DTC支持OleDB、XA、WS-AtomicTransaction、WSCoordination、WS- BusinessActivity等多个协议。由于分布式事务需要在多个参与方之间实现多次通讯,所以是一种巨大的开销,因此,在可以使用LTM和KTM的时候,应该尽量避免使用DTC。在上面图片中的事务同时启动了两个RM分别处理数据库数据与文件数据,当中启动的就是DTC分布式事务。
4.事务类 System.Transactioins.Transaction
Transaction是由Framework 2.0 就开始引入,用于显示管理事务的一个类。通过Transaction可以直接管理事务的中止、释放,也可以获取、克隆当前的环境事务类。
- Transaction的公用属性
其中Transaction.Current 比较常用,它可以指向一个当前运行环境中的事务,如果环境事务不存在,系统将返回一个null
Transaction transaction=Transaction.Current;
| 属性 | 说明 |
|---|---|
| Current | 获取或设置环境事务。 |
| IsolationLevel | 获取事务的隔离级别。 |
| TransactionInformation | 检索有关某个事务的附加信息。 |
- Transaction的常用公用方法
其中Rollback、Dispose方法可以控制事务中止、释放,而Clone、DependentClone方法在多线程操作中经常用到,在 “异步事务” 一节中将详细说明
| 方法 | 说明 |
|---|---|
| Rollback | 中止事务、回滚。 |
| Dispose | 释放事务对象。 |
| Clone | 创建事务克隆 |
| DependentClone | 创建事务的依赖克隆。 |
- Transaction的事件
在事务完成后,会触发TransactionCompleted事件,开发人员可以在此事件的过程监测其状态
| 事件 | 说明 |
|---|---|
| TransactionCompleted |
在事务完成后执行 |