前言
Facebook(后面简称fb)是世界最大的社交平台,需要存储的数据时刻都在剧增(占比最大为图片,每天存储约20亿张,大概是微信的三倍)。
那么问题来了,fb是如何存储兆级别的图片?并且又是如何处理每秒百万级别的图片查询?
本文以简单易懂,图文并茂的方式来解释其中的原理,并不涉及空洞,难解的框架,也没有大篇章的废话铺陈,只有痛点与反思;就如同fb的架构师所说:fb的存储架构就像高速公路上换轮胎,没有最完美的设计,我们最求的只是如何让它变得更简单。
短篇介绍
fb的图片存储系统叫做HayStack,目前已存储超过120PB的数据,用户每天会上传20亿张图片。fb图片搜索峰值,需要提供每秒100-200万张的图片搜索。这些数据还再不断地增加。
稍微分析下用户使用场景,图片写入一次,频繁读取,从不修改,很少删除。传统的文件系统:每个图片都会有一些元数据,在我们的需求中,这些信息无用,且浪费存储空间,更大的性能消耗是文件的元数据需要从磁盘读到内存中来定位图片位置,在fb的量级上,元数据的吞吐量便是一个巨大的瓶颈。
高吞吐量,低延迟是HayStack所追求的,所以HayStack希望每个图片读取操作至多需要一个磁盘,并且减少每个图片的必要元数据,并将它们保存至内存中。为了做好容灾,HayStack会将图片复制多张并保存至不通数据中心,以确保不反回404,error给客户。
典型的设计方案
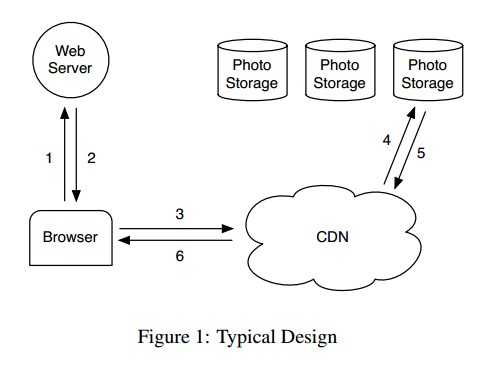
上图为典型的设计方案:
1.用户通过浏览器发送图片信息请求至web server;2.web server 构造一个url,引导浏览器到对应位置下载图片;3.通常这个url指向一个CDN,如果CDN有缓存相关图片的话,它会将图片立刻返回给浏览器;4.否则,会解析url,并在Photo Storage中找到对应的图片;5.6.返回给用户。
NAS-NFS
在fb的服务中,只有CDN不足以解决全部需求,对于新图片,热门图片CDN确实很高效。但是对于一些个人上传的老图片请求,CDN基本上会全部命中失败,又没有办法将图片全部缓存起来。所以这里,可以采用NAS-NFS来解决问题。
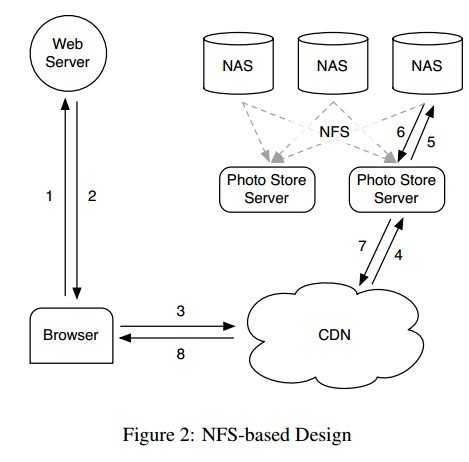
基本操作与上面相同,5.6.photo store server 解析url得出完整的卷和路径信息,在NFS上读取数据,然后返回给CDN。
这种设计的瓶颈:NFS卷的每个目录下存储上千张图片,导致读取时产生了过多的磁盘操作。
HayStack
HayStack架构包含3个核心组件:HayStack Store,HayStack Directory和HayStack Cache。 Store是存储系统,负责管理图片的元数据。不同机器上的物理卷对应一个逻辑卷,HayStack将一个图片保存至一个逻辑卷时,那么图片便对应写入所有物理卷。Directory 维护了逻辑到物理卷的映射以及相应的元数据,例如说,某张图片保存在哪个物理卷里,某个物理卷的存储空间等。Cache的功能,类似内部的CDN,它帮Store挡住热门搜索。
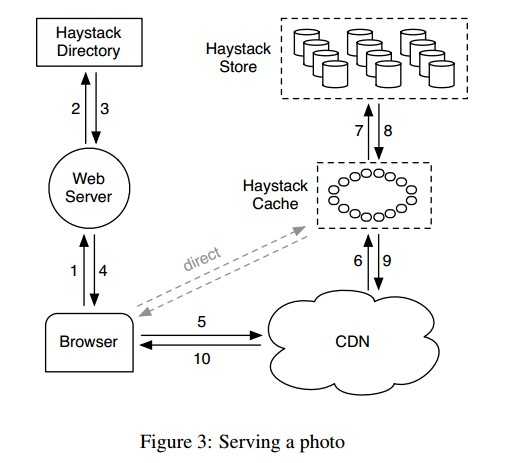
上图描述了3个核心组件的相互作用。在HayStack架构中,浏览器的请求被引导至CDN中(或Cache上),Cache本质就是CDN,为了避免冲突,我们使用CDN来表示外部系统,使用Cache表示内部系统。
1.当用户发出请求给web server,2.web server 使用Directory来构建图片的url,3.4.5.6.7.8.9.10.url包含一段信息,如下:
http(s)://CDN/Cache/machine_id/volume_ID_Photo
一目了然,url包含CDN地址信息,Cache信息,以及保存图片的物理卷ID,以及图片信息。
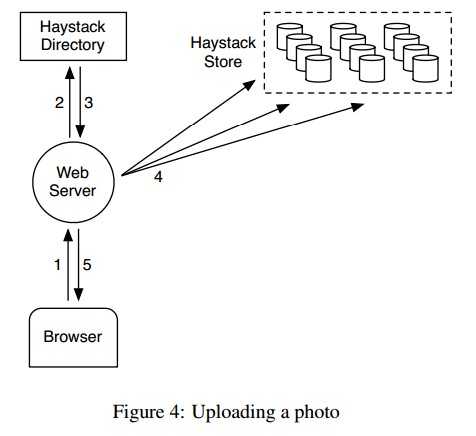
图4,位用户上传图片的流程,1.用户发送请求至web server;2.web server请求Directory一个可用的逻辑卷,物理卷,并将图片信息记录下;3.将相关信息发送至web server;4.web server将图片上传至Store;5.返回成功信息。
Directory
主要有4个功能:
1.它提供了逻辑卷到物理卷的映射,web服务器上传或读取图片时需要使用这个映射。
2.它在分配写请求,读请求到物理卷时,需保证负载均衡。
3.它决定一个图片的请求,是发送至CDN或Cache,这个决定可以动态调整是否依赖CDN。
4.它指定哪些卷是只读的。
当我们增加Store的时候,那些卷都是可写的,可写的机器会收到上传信息。当它们到达容量上限时,标记它们为只读。
Cache
Cache的实现可以理解为一个分布式Hash Table,以图片ID为key,定位缓存的图片数据。如果Cache未命中,那么Cache则根据URL到指定的Store中,读取图片数据。
Store
很简单,根据提供的一些元数据信息,包括图片ID,逻辑卷ID,物理卷ID,找到对应的图片,未找到则返回错误信息。
下面简单描述一下物理卷与映射的结构,一个物理卷可以理解为一个大型文件,包含一系列的needle,每个needle就是一张图片。如下图所示。
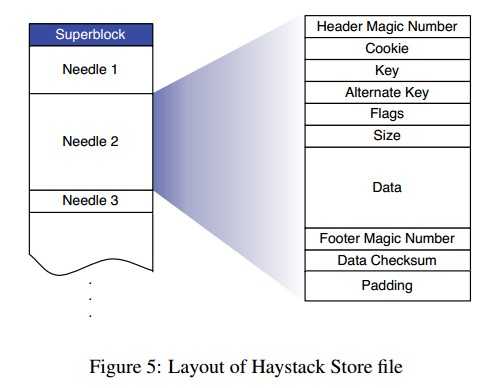
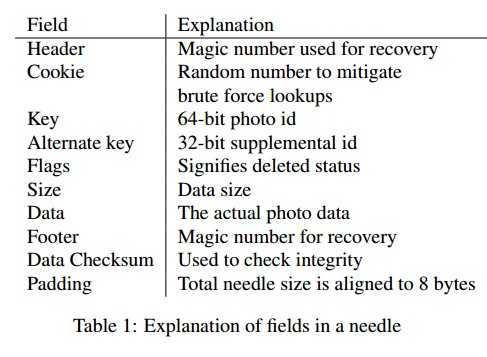
为了快速索引needle,Store需要为每个卷提供一个内存中的key-value映射。
HayStack文件系统
HayStack可以理解成基于Unix文件系统搭建的对象存储架构。Store使用的文件系统是XFS,XFS有两个优点,首先,XFS中的临近大型文件的blockmap很小,可放入内存存储。再者,XFS提供高效的文件预分配,减少磁盘碎片问题。使用XFS,可以完全避免检索文件系统导致的磁盘操作。