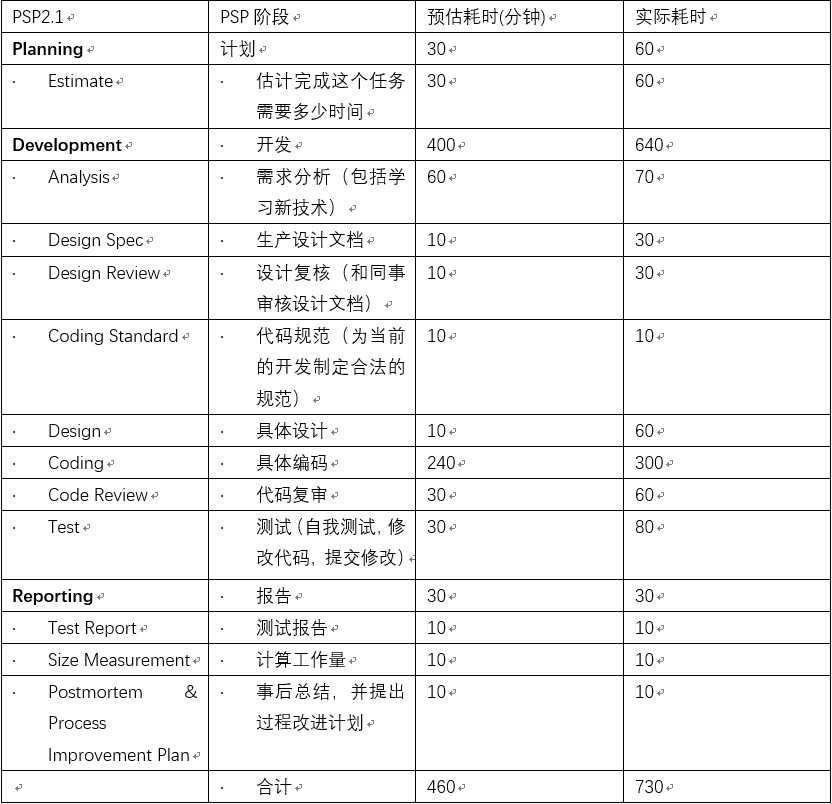
项目地址:https://github.com/evilkant/WordCount
解题思路:
这个项目其实比较基础,功能实现上没什么难度,误以为只能用JAVA语言开发,我花了一个小时回顾JAVA的基础知识【1】,配置JAVA开发环境。然后就开始编程,基础功能很简单,没遇到什么问题。做扩展功能碰到了两个问题,处理通配符时,如果直接从cmd输入*.c的话,cmd会将*.c自动补全成当前目录下后缀为.c的文件路径,折腾了好一会。然后代码行,空行和注释行的定义在我看来根本就不能自洽,我只能认为1)写需求的人逻辑不严谨 2)写需求的人与我存在严重的信息不对称。于是我光吐槽这个需求就吐槽了一个小时,后面等到更新了需求样例我才揣测清了需求完成了该功能。其他的也没什么好说的,就是简单的字符串处理,文件IO操作。
实现过程:
因为这是个小项目,虽然是用JAVA开发,我直接采用面向过程的范式一路平推了。解析输入参数----->(如果需要的话)解析禁用词文件得到禁用词表---->(如果需要的话)递归处理目录得到需要处理的文件列表----->对文件进行统计------->将统计结果写到输出文件。
代码说明:
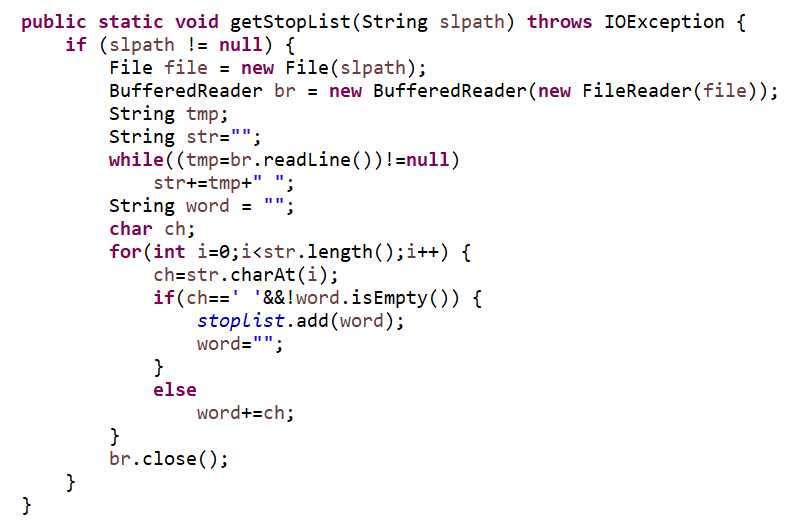
上面是解析禁用词文件的代码,以空格为分隔符将单词提取出来并加入禁用词列表。
其实说实在的没有什么关键的代码,随便贴一个意思意思一下,要说必不可少吧,每个函数少了都不行,要说难以实现吧,也没有那段代码写起来尤其费劲。
测试设计过程:
我主要按照一下三点设计测试用例:
1)划分等价类,同类的输入只取其中典型一个,比如测试字符计数正确性时可设计测试用例: "!aA 1,圗"。
2)注重边界值,这是错误的高发区域,比如空行是行的一种边界情况。
3)测试条件分支的正确性,如是否启用-e,是否启用-s等。
因为我把所有统计功能放在一起做了,也就不单独区分统计单词,统计行数之类的了。
参考文献链接:
【1】http://www.runoob.com/java/java-tutorial.html