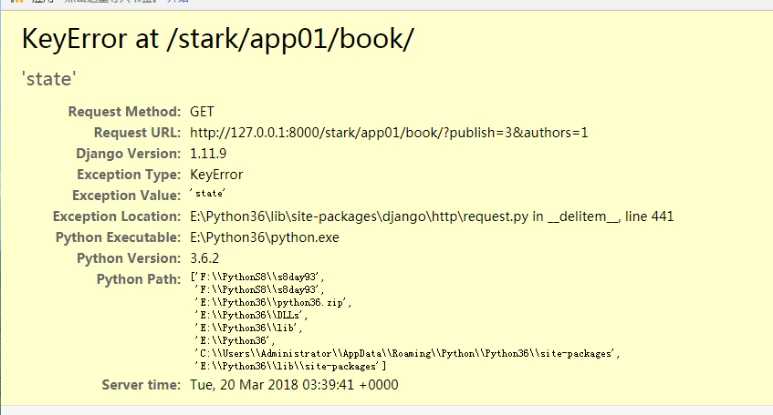
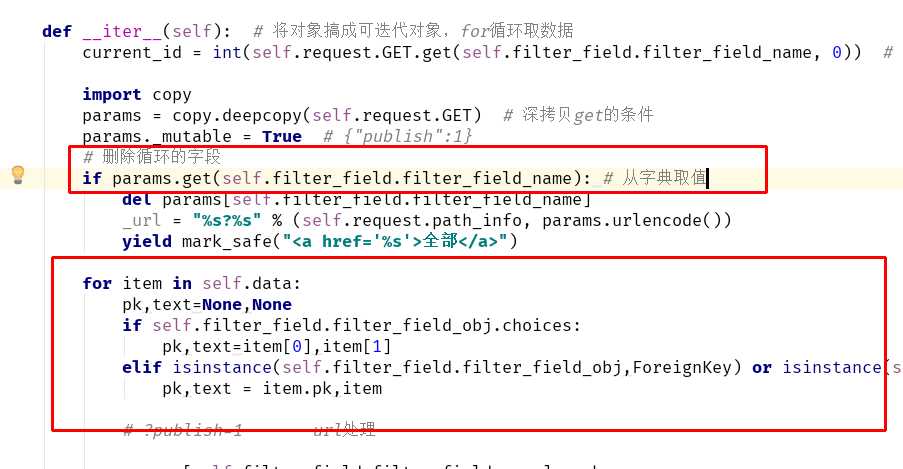
步骤一:渲染标签
双层for循环----
步骤二:进行数据过滤
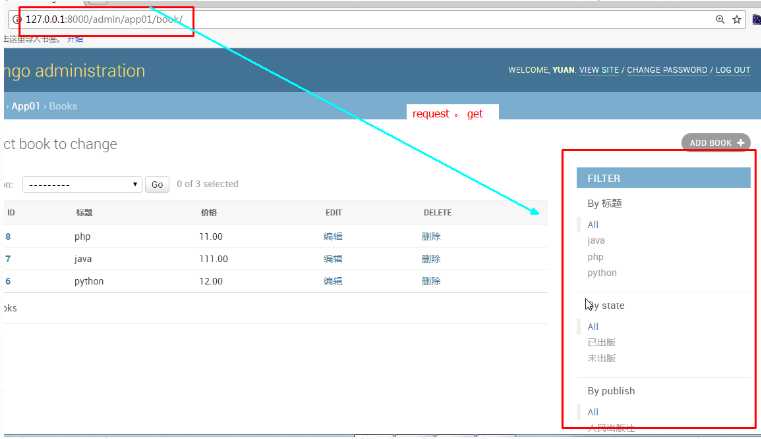
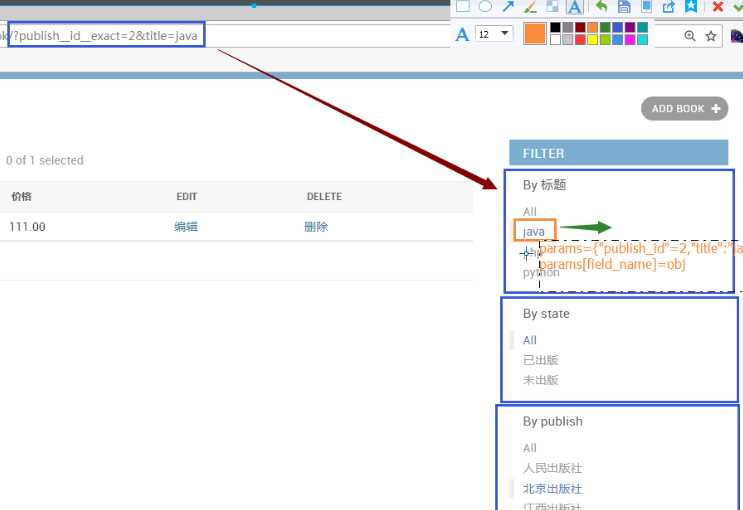
fiter_name=java
知识点:
""" 改为生成器方式: def foo(): temp=[] for i in range(1,100): temp.append(i*i) return temp for i in foo(): print(i) """ # 函数跟生成器就差在yield # 生成器定义式:1:生成器表达式 2:函数加yield, # 现在的foo() ---> 生成器对象 def foo(): for i in range(1,100): print(i) # 没打印 yield i*i ret= foo() print(ret) # <generator object foo at 0x0000000003D9E830> 生成器对象 # for i in foo(): # print(i)
_meta.get_field
取字段里面的属性
from .models import Book def test(request): publish=Book._meta.get_field("publish") # 可以取到publish字段的所有东西 max_length print(publish.rel.to.objects.all()) # <QuerySet [<Publish: 清华出版社>, <Publish: 北京出版社>, <Publish: 南京出版社>]> author=Book._meta.get_field("authors") # 可以取到publish字段的所有东西 max_length print(author.rel.to.objects.all()) # <QuerySet [<Author: 柴静>, <Author: 韩寒>, <Author: 钱钟书>, <Author: 霍金>]> return HttpResponse("666")
url处理
当选中全部:删除原来的url的键
原因:删除的话,需要那个键值原来就有(从字典里取值同理)