数据分析和判别的过程中,存在数值化特征和非数值化特征。
对非数值化特征,使用人工神经网络或支持向量机则需要对数据进行编码后进行分类,但是分明显编码之后大幅度增加了数据的维度。因此引入决策树的方法。
决策树是一种利用一定的训练样本从数据中学习规则的模型,很明显他是一种有监督学习(supervised learning)
决策树由一系列节点组成,每个节点代表一个特征和相应的决策规则。决策树的构造过程就是选取特征和确定特征规则的过程。决策树的构造分为以下几种方法。
ID3方法(交互式二分法 Interactive Dichotomizer-3)
ID3算法的基础是香浓信息论中定义的信息熵(entropy)
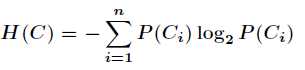
其中C是一个概率向量,表示样本在该属性上的值占样本分类的比率
对于某个节点上的样本,该值成为熵的不纯度,反映了该节点对样本分类的不纯度(impurity)
而该节点相对于全体属性的不纯都减少量为信息增益
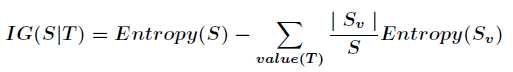
C4.5算法
C4.5算法是ID3算法的改进,区别在于:C4.5算法采用信息增益率替代信息增益
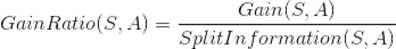
也就是对于每个样本的不纯度以ΔI(N)/I(N)表示
此外C4.5算法增加了处理连续数值的特征(ID3算法只能处理标量数据),具体方法是特征值在训练样本上包含了n个取值,按从小到大的方法排序,再用二分法划分为n-1组取值,每一组计算信息增益率后,按照增益率大的方案将连续特征离散化为二值特征(或多值特征)。
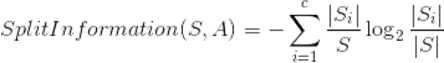
CART算法