不多说,直接上干货!
这是来自FineBI官网提供的帮助文档
http://help.finebi.com/
http://help.finebi.com/doc-view-581.html
目录:
1、描述
Spark是一种通用的大数据快速处理引擎。Spark使用Spark RDD、 Spark SQL、 Spark Streaming、 MLlib、 GraphX成功解决了大数据领域中离线批处理、交互式查询、实时流计算、机器学习与图计算等最重要的任务和问题。Spark除了一站式的特点之外,另外一个最重要的特点,就是基于内存进行计算,从而让 它的速度可以达到MapReduce、Hive的数倍甚至数十倍。本章我们将介绍如何在FineBI中连接Spark数据库。
2、操作
| 驱动 | URL | 支持数据库版本 |
|---|---|---|
| org.apache.hive.jdbc.HiveDriver | jdbc:hive2://ip:port/dbname | 2.2.0 |
2.2 步骤
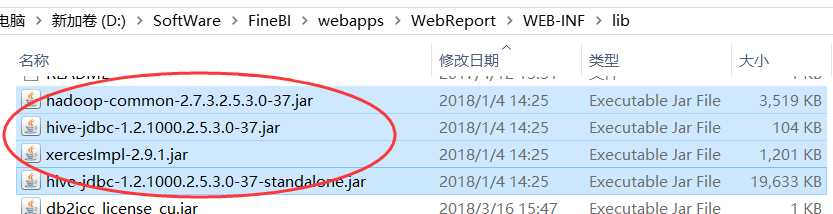
下载Spark的驱动包,并将该驱动包放置到FineBI文件夹%FineBI%\webapps\WebReport\WEB-INF\lib下,重启服务器。
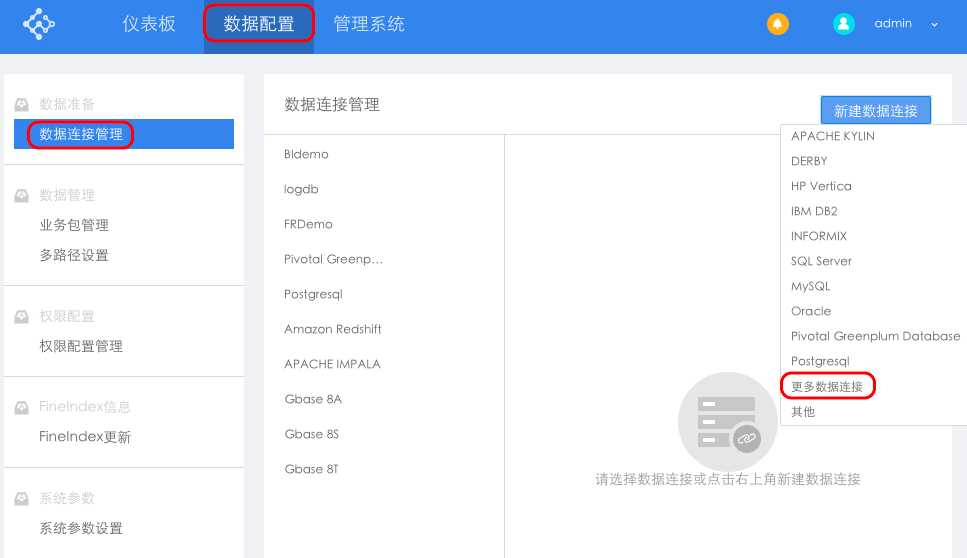
登录FineBI数据决策系统,选择数据配置>数据连接管理,点击“新建数据连接”选择更多数据连接,并在弹出框中选择SPARK,如下图:

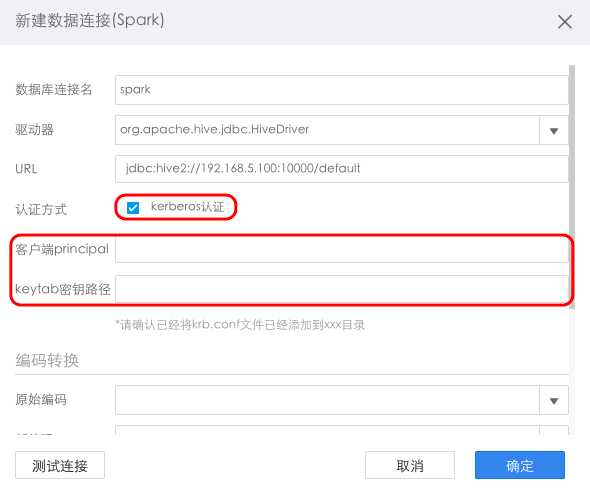
点击“下一步”并按照前面提供的配置信息,输入自身数据库的对应信息,可选择勾选kerberos认证。若勾选kerberos认证,则需填入注册过kdc的客户端名称和keytab密钥路径,如下图:
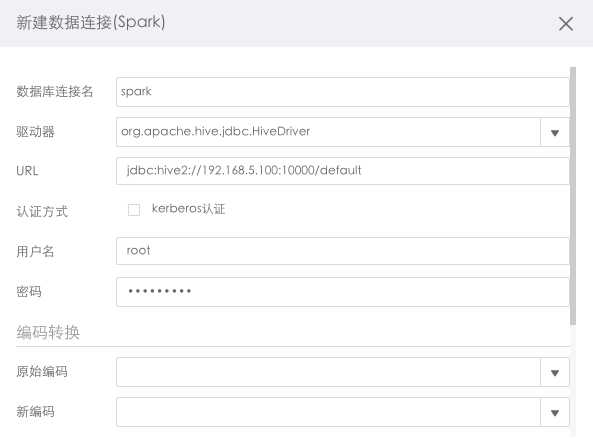
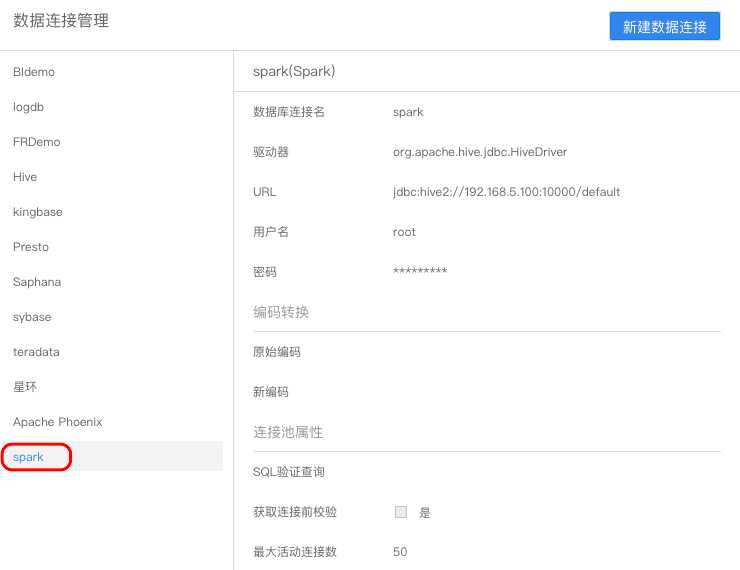
若不勾选kerberos认证,则跟其他数据库设置一致,选择填入编码转换和连接池属性信息即可(编码转换和连接池属性介绍可参考配置数据连接)
如下图:
点击测试连接,若测试连接成功则表示成功连接上数据库,如下图:
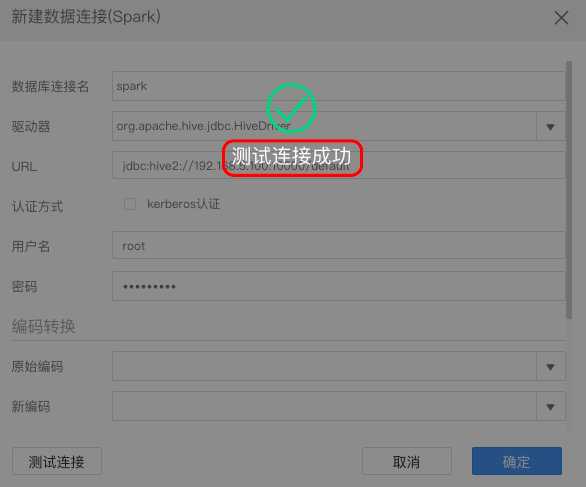
测试连接成功后点击“确定”该数据连接即添加成功。

3、注意事项
FineIndex引擎无法直接取数据库表,目前只能通过sql数据集获取。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)