标签:Lucene style blog http color io os 使用 java
Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎 ;Lucene得名于Doug妻子的中名,同时这也她外祖母的姓;目前是Apache基金会的一个顶级项目,同时也是学习搜索引擎入门必知必会。
Lucene 是一个 JAVA 搜索类库,它本身并不是一个完整的解决方案,需要额外的开发工作。
优点:成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索。
缺点:需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善。
对于全文检索一般都由以下3个部分组成:
在接下来的一系列文章中会详细介绍这三个部分,本文将简单介绍lucene环境搭建以及lucene索引初步。
目前基于Lucene的产品有:
Solr,Nutch,Hbase,Katta,constellio,Summa,Compass,Bobo Search,Index Tank,Elastic Search,Hadoop contrib/index ,LinkedIn ,Eclipse,Cocoon
目录最新版的Lucene为4.10.0(今天是2014-09-23 )版,其官方主页为:http://lucene.apache.org/
如果你会使用Maven,那么可以非常简单的将pom.xml中加入以下内容即可:

<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.10.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.10.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>4.10.0</version> </dependency>
如果不会使用Maven,则需要手工下载相应的jar包进行开发。
1、创建Directory
2、创建IndexWriter
3、创建Document对象
4、为Docuemnt添加Field
5、通过IndexWriter添加文档到Document
package com.amos.lucene; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.FieldType; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexableField; import org.apache.lucene.index.IndexableFieldType; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.store.RAMDirectory; import org.apache.lucene.util.Version; import java.io.File; import java.io.FileReader; import java.io.IOException; /** * Created by amosli on 14-9-17. */ public class HelloLucene { static String indexDir = "/home/amosli/developtest/lucene"; public void index() { IndexWriter indexWriter = null; FSDirectory directory = null; try { //1、创建Directory directory = FSDirectory.open(new File(indexDir)); //RAMDirectory directory = new RAMDirectory(); //2、创建IndexWriter IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_4_10_0, new StandardAnalyzer(Version.LUCENE_4_10_0)); indexWriter = new IndexWriter(directory, indexWriterConfig); File file = new File("/home/amosli/developtest/testfile"); for (File f : file.listFiles()) { FieldType fieldType = new FieldType(); //3、创建Docuemnt对象 Document document = new Document(); //4、为Document添加Field document.add(new TextField("content", new FileReader(f)) ); fieldType.setIndexed(true); fieldType.setStored(true); document.add(new Field("name", f.getName(),fieldType)); fieldType.setIndexed(false); fieldType.setStored(true); document.add(new Field("path", f.getAbsolutePath(), fieldType)); //5、通过IndexWriter添加文档索引中 indexWriter.addDocument(document); } } catch (IOException e) { e.printStackTrace(); } finally { if (indexWriter != null) { try { indexWriter.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
注:
1、这里使用的是FSDirectory,是为了方便进行测试,将生成的文件写入到本地硬盘中;
2、Document相当于数据库中的一条记录,field相当数据库中表的一列;
3、使用indexWriter当记录添加到文档索引中;
4、fieldType可以设置是否需要索引和是否需要存储;
5、记得关闭indexWriter
生成的索引文件,如下图所示:
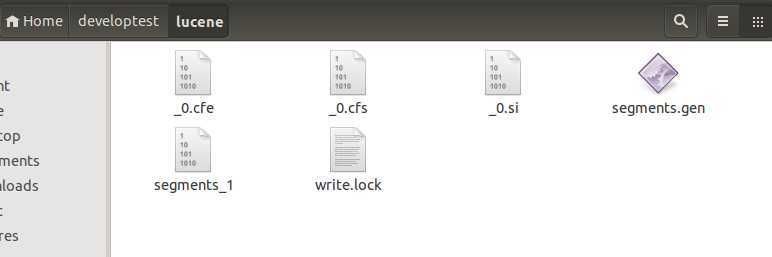
1、创建Directory
2、创建IndexReader
3、根据IndexReader创建IndexSearcher
4、创建搜索的Query
5、根据Searcher搜索并且返回TopDocs
6、根据TopDocs获取ScoreDoc对象
7、根据Seacher和ScoreDoc对象获取具体的Document对象
8、根据Document对象获取需要的值
public void search() { IndexReader indexReader = null; try { //1、创建Directory FSDirectory directory = FSDirectory.open(new File(indexDir)); //2、创建IndexReader indexReader = DirectoryReader.open(directory); //3、根据IndexReader创建IndexSearcher IndexSearcher indexSearcher = new IndexSearcher(indexReader); //4、创建搜索的Query //创建querypaser来确定要搜索文件的内容,第二个参数表示搜索的域 QueryParser queryParser = new QueryParser("content", new StandardAnalyzer()); //创建query,表示搜索域为content中包含java的文档 Query query = queryParser.parse("java"); //5、根据Searcher搜索并且返回TopDocs TopDocs topDocs = indexSearcher.search(query, 100); //6、根据TopDocs获取ScoreDoc对象 ScoreDoc[] sds = topDocs.scoreDocs; //7、根据Seacher和ScoreDoc对象获取具体的Document对象 for (ScoreDoc sdc : sds) { Document doc = indexSearcher.doc(sdc.doc); //8、根据Document对象获取需要的值 System.out.println("name:" + doc.get("name") + "-----> path:" + doc.get("path")); } } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); }finally{ if(indexReader!=null){ try { indexReader.close(); } catch (IOException e) { e.printStackTrace(); } } } }
输出结果:
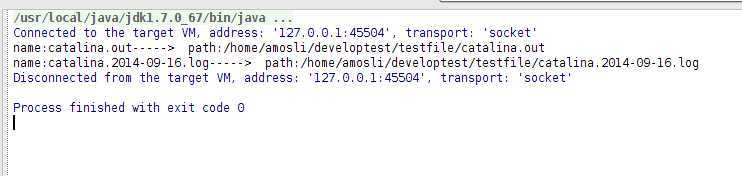
所有源码:HelloLucene.java
 View Code
View CodeTestHelloLucene.java
View Code标签:Lucene style blog http color io os 使用 java
原文地址:http://blog.csdn.net/sxw3718401/article/details/39494319