原文地址:https://blog.csdn.net/actsai/article/details/24256987
|
eclipse 中遇到了Syntax error on token "Invalid Character", delete this token的错误提示,看代码是完全没有问题,上网查了半天发现遇到这个问题的好像不太多,总结一下问题原因和解决方案吧。 看到这个提示首先想到的是标点符号不是不是中文,或者全角半角的问题了,通过检查,这种问题并不存在。 然后看到一个帖子说用Android Studio引入eclipse项目时遇到了同样的错误,原因是eclipse和idea对同样编码utf-8的细节不一致,一个有BOM,一个没有。 什么是BOM呢?BOM的全称是:Byte order mark。UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。 UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
通过UE查看文件的16进制形式,发现开头包含EF BB BF串,eclipse不对其做识别而作为普通的字符处理,因此报错。 |
把报错文件使用notepad打开,右下方显示文件编码并不是单纯的utf-8,
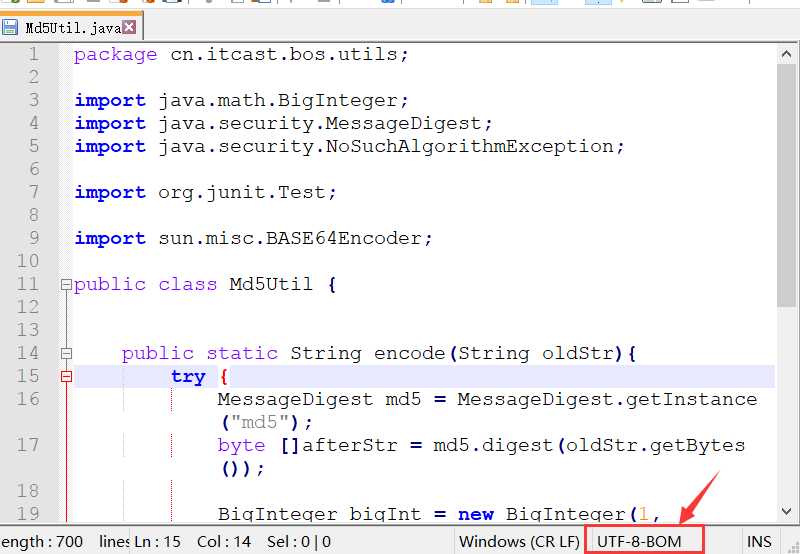
参考上文
解决办法:
解决方法:
1.使用UE或者其他文本工具,将有问题的java文件另存为UTF-8,无BOM,替换原来的java文件。
2.使用eclipse自建的文件编码,尽量不要从其他地方拷贝代码