标签:style blog http color os 使用 ar 文件 数据
Storm是一个分布式的、可靠的、容错的数据流处理系统(流式计算框架,可以和mapreduce的离线计算框架对比理解)。 整个任务被委派给不同的组件,每个组件负责一个简单的特定的处理任务。Storm集群的输入流是一个叫spout的组件负责接入处理。spout把数据传 给bolt组件,bolt组件可以对数据完成某种转化。bolt组件可以把数据持久化,或者传送到其他的bolt。可以把Storm集群想象成一个 bolt组件链,每个组件负责对spout流入的数据(也可以是其他bolt流入的数据)进行某种形式的处理。
有个简单的例子可以说明这个概念。昨晚我看新闻,节目中发言人在谈论政治家以及他们在不用领域的立场。他们不停地在重复一些不同的名字,这时我想知道他们提到的每个名字出现的次数是否一样,还是在某些名字被提及次数更多。
把发言人的言语想象成数据的输入流。我们可以定义一个spout从文件(通过socket、HTTP或者其他方式)读取这些输入。当几行文本到来 时,spout把它们传送给bolt,bolt负责把文本分词。接着数据流被传送到另外一个bolt,这个bolt负责在一个已经定义好的政治家名单进行 比对。如果匹配到了,将数据库中对应的名字的计数加1。任何时候你想看结果,只要从数据库中查询就可以,因为当数据到达时整个过程都是实时更新的。这过程 中所有的组件(spout和bolt)以及他们之间的连接被称为拓扑(topology)(见图表 1-1)。
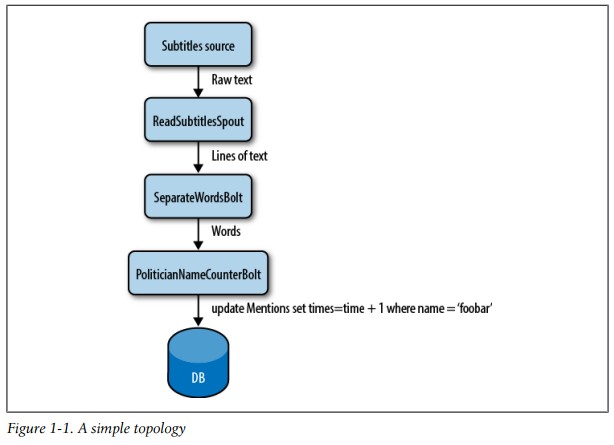
现在很容易想象定义每个bolt和spout并行度,这样可以无限地扩展整个拓扑。很神奇,对吧?尽管前面讲的只是一个简单的例子,不过你大概已经隐约感觉到Storm的强大了。
那么,Storm适用什么应用场景呢?
(补充)从业务场景上,举例说明Storm的可以处理的具体业务(这部分是黄崇远总结的,觉得比较全面,摘抄在此)
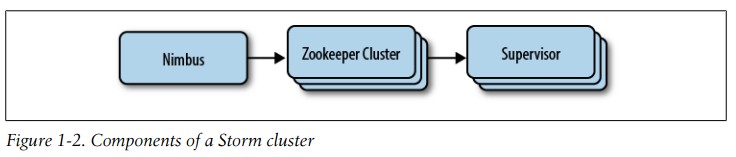
在Storm集群中,节点被一个主控节点管理,并持续运行。
在Storm集群中有两类节点:主控节点和工作节点。主控节点跑一个后台进程Nimbus,它负责在集群中分发代码,把任务安排给工作节点,监控任 务是否失败。工作节点跑后台进程叫Supervisor来执行拓扑的部分功能。Storm的拓扑会在不同机器的工作节点上运行。
因为Storm把集群的状态存在Zookeeper或者本地磁盘,所以后台进程都是无状态的(不需要保存自己的状态,都在zookeeper上),可以在不影响系统健康运行的同时失败或重启。(见图1-2)
在底层Storm使用了zeromq(0mq,zeromq(http://www.zeromq.org)),一个先进的嵌入式的网络通讯库,提供了很棒的功能使得Storm成为可能。以下是zeromq的特点:
 Storm用了push/pull套接字api
Storm用了push/pull套接字api
(补充:Storm组件的命名方式)
Storm暴风雨:其组件大多也以气象名词命名
spout龙卷:形象的理解是把原始数据卷进Storm流式计算中
bolt雷电:从spout或者其他bolt中接收数据进行处理或者输出
nimbus雨云:主控节点,存在单点问题,不过可以用watchdog来保证其可用性,fast-fail后马上就启动
topology拓扑:Storm的任务单元,形象的理解拓扑的点是spout或者bolt,之间的数据流是线,整个构成一个拓扑
所有的设计概念和决策,使得Storm拥有诸多美好的特性,Storm变得独一无二。
《Getting started with Storm》译文HomePage 译文索引
标签:style blog http color os 使用 ar 文件 数据
原文地址:http://my.oschina.net/yjwxh/blog/317312