标签:style blog http color strong 数据 2014 sp on
这篇文章将接着上一篇wordcount的例子,抽象出最简单的过程,一探MapReduce的运算过程中,其系统调度到底是如何运作的。
wordcount这个例子的是hadoop的helloworld程序,作用就是统计每个单词出现的次数而已。其过程是:
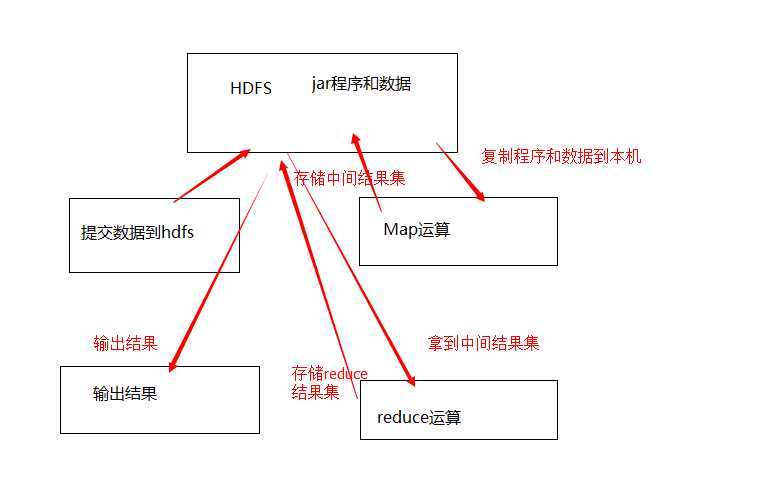
现在我用文字再来描述下这个过程。
1 Client提交一个作业,将Mapreduce程序和数据到HDFS中
2 发起作业,Hadoop根据各机器空闲情况,调度一台(或者N台taskTracker机器,进行Map运算)
3 taskTacker机器将程序和数据拷贝到自己机器上。
4 taskTacker机器启动jvm,进行Map运算
5 taskTacker机器运算完成,将数据存储在本机上,并通知JobTacker节点。
6 JobTacker等待所有机器完成,调度一台空闲的机器,进行Reduce运算,并告知数据存储所在机器。
7 进行Reduce运算的TaskTacker将数据通过RPC拷贝到自己机器上,同时将程序从HDFS中拷贝到自己机器中。
8 启动JVM,加载程序,进行Reduce运算。
9 运算完成,reduce运算的机器将数据存储在HDFS中,并通知JobTacker。
10 JobTacker发现任务完成,通知客户端,你的事干完了。
11 客户端通过访问HDFS,拿到最终运算数据。
为什么Map中间数据会存储本机上而不是HDFS上呢,原因是因为中间的运算可能会失败,如果失败了也没有必要存储在HDFS上,JobTacker会选择另外一台机器完成任务即可。只有最终数据才是有价值的。
真实的情况当然不是情况一,原因是因为: 移动运算比移动数据更经济. 在Hadoop中,往往同一台机器既是DataNode,也是TaskTraker。Hadoop在调度过程中,会优先调度数据所在的机器进行运算,这样数据就不会在机器之间Copy来Copy去,网络带宽就不会成为运算的瓶颈了。这个例子的示意图如下:
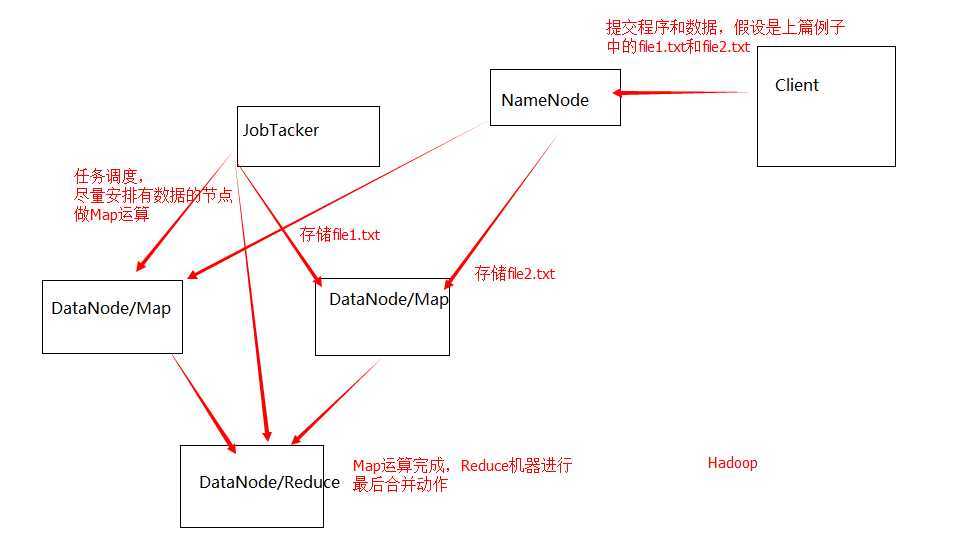
这张图结合上面的描述,我相信大家应该很容易就看懂了。那既然Hadoop的实际过程是情况二,我为什么要先描述情况一呢?原因有两点:
1 情况一更容易理解。
2 情况一更容易实现。
如何根据Hadoop的调度原理,写自己的的集群调度框架,这是我最近在思索和践行的一个事情,有兴趣的同学其实也可以自己写一个,大家多多交流~
标签:style blog http color strong 数据 2014 sp on
原文地址:http://www.cnblogs.com/HouZhiHouJueBlogs/p/3987666.html