1.Scrapy是蜘蛛爬虫框架,我们用蜘蛛来获取互联网上的各种信息,然后再对这些信息进行数据分析处理。
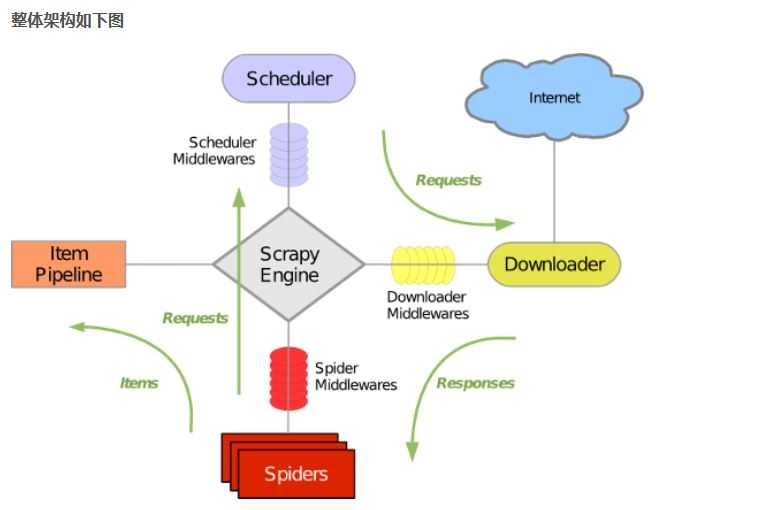
2.Scrapy的组成
引擎:处理整个系统的数据流处理,出发事务
调度器: 接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回
下载器: 下载网页内容,并将网页内容返回给蜘蛛
蜘蛛: 蜘蛛是主要干活的,用来制定特定域名或网页的解析规则
项目管道: 清洗验证存储数据,页面被蜘蛛解析后,被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件: 位于引擎和下载器之间,处理引擎与下载器之间的请求及响应
蜘蛛中间件:位于引擎和蜘蛛之间,处理从引擎发送到调度的请求及响应
3.组件详解