一、前述
调优对于模型训练速度,准确率方面至关重要,所以本文对神经网络中的调优做一个总结。
二、神经网络超参数调优
1、适当调整隐藏层数
对于许多问题,你可以开始只用一个隐藏层,就可以获得不错的结果,比如对于复杂的问题我们可以在隐藏层上使用足够多的神经元就行了, 很长一段时间人们满足了就没有去探索深度神经网络,
但是深度神经网络有更高的参数效率,神经元个数可以指数倍减少,并且训练起来也更快!(因为每个隐藏层上面神经元个数减少了可以完成相同的功能,则连接的参数就少了)
就好像直接画一个森林会很慢,但是如果画了树枝,复制粘贴树枝成大树,再复制粘贴大树成森林却很快。真实的世界通常是这种层级的结构,DNN就是利用这种优势。
前面的隐藏层构建低级的结构,组成各种各样形状和方向的线,中间的隐藏层组合低级的结构,譬如方块、圆形,后面的隐藏层和输出层组成更高级的结构,比如面部。
仅这种层级的结构帮助DNN收敛更快,同时增加了复用能力到新的数据集,例如,如果你已经训练了一个神经网络去识别面部,你现在想训练一个新的网络去识别发型,你可以复用前面的几层,就是不去随机初始化Weights和biases,你可以把第一个网络里面前面几层的权重值赋给新的网络作为初始化,然后开始训练(整体来看会提高速度)。
这样网络不必从原始训练低层网络结构,它只需要训练高层结构,例如,发型
对于很多问题,一个到两个隐藏层就是够用的了,MNIST可以达到97%当使用一个隐藏层上百个神经元,达到98%使用两
个隐藏层,对于更复杂的问题,你可以逐渐增加隐藏层,直到对于训练集过拟合。(会经常过拟合,因为会不断地调整参数)
非常复杂的任务譬如图像分类和语音识别,需要几十层甚至上百层,但不全是全连接,并且它们需要大量的数据,不过,你很少需要从头训练,非常方便的是复用一些提前训练好的类似业务的经典的网络。那样训练会快很多并且需要不太多的数据
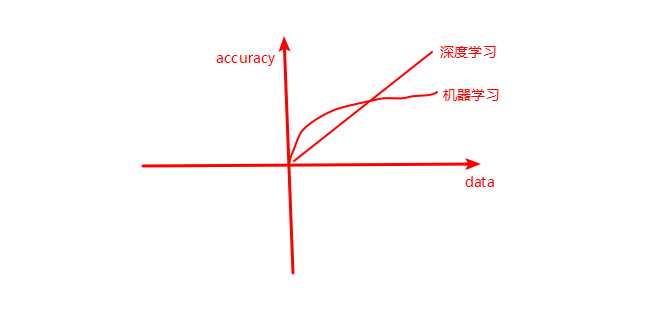
当数据量不大的时候选择机器学习(浅层模型)准确率好,数据量大的时候选择深度学习。
2、每个隐藏层的神经元个数
输入层和输出层的神经元个数很容易确定,根据需求,比如MNIST输入层28*28=784,输出层10
通常的做法是每个隐藏层的神经元越来越少,比如第一个隐藏层300个神经元,第二个隐藏层100个神经元,可是,现在更多的是每个隐藏层神经元数量一样,比如都是150个,这样超参数需要调节的就少了,正如前面寻找隐藏层数量一样,可以逐渐增加数量直到过拟合,找到完美的数量更多还是黑科技。
简单的方式是选择比你实际需要更多的层数和神经元个数(很容易过拟合),然后使用early stopping去防止过拟合,还有L1、L2正则化技术,还有dropout
三、防止过拟合技术
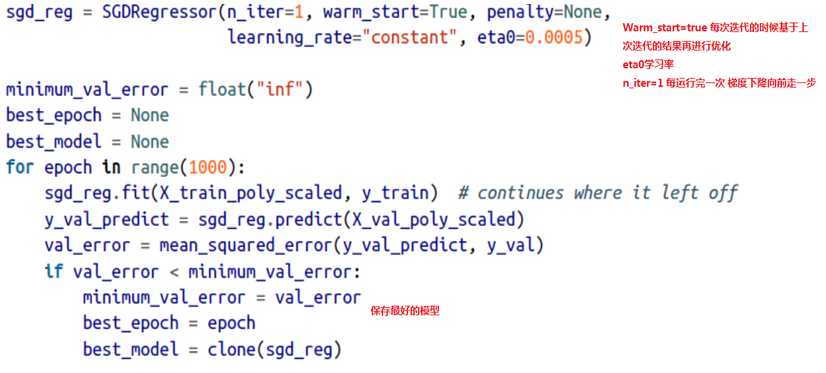
1、Early stopping(需要验证集)
去防止在训练集上面过拟合,
1.1 一个很好的手段是early stopping,
当在验证集上面开始下降的时候中断训练,一种方式使用TensorFlow去实现,是间隔的比如每50 steps,在验证集上去评估模型,然后保存一下快照如果输出性能优于前面的快照,记住最后一次保存快照时候迭代的steps的数量,当到达step的limit次数的时候,restore最后一次胜出的快照。
尽管early stopping实际工作做不错,你还是可以得到更好的性能当结合其他正则化技术一起的话
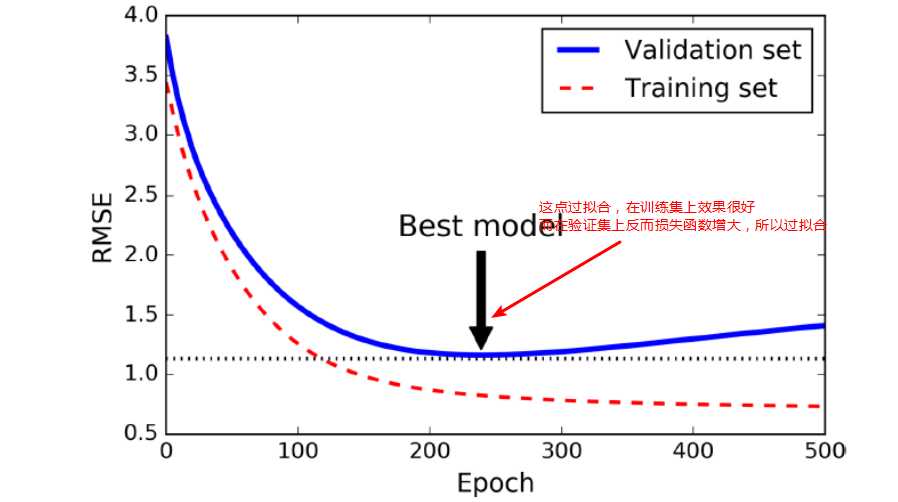
上图中则需要当迭代次数运行完后,resotore损失函数最小的w参数。
1.2、代码示范: