Hadoop 概述和结构
1. Hadoop 构成
Hadoop 是有两部分构成一个是分布式计算框架MapReduce另一个是分布式存储框架HDFS.
2.HDSF
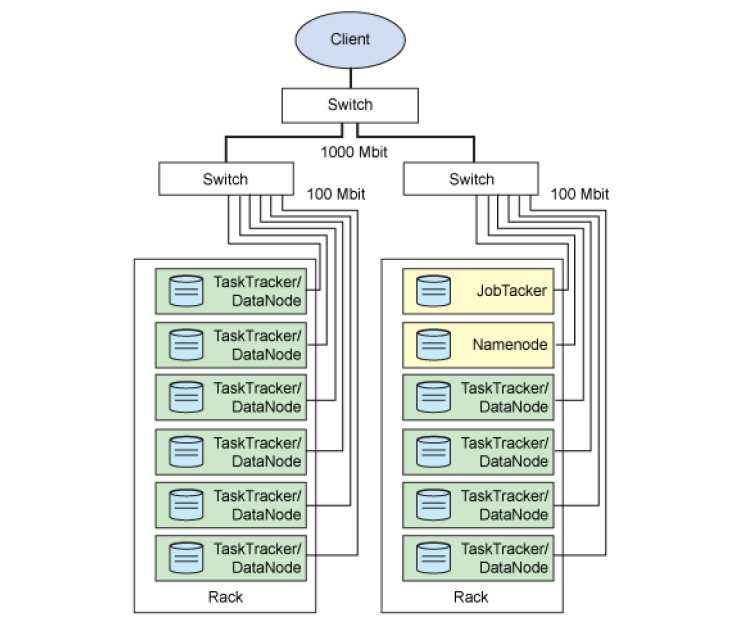
HDFS 是一个Master-Slave结构,其有一个NameNode和多个DataNode,组成,NameNode主要记录HDSF上文件的所在的位置和数据块控制着整个文件系统,并通过NN寻址找到DataNode上的文件,因为NN是一个结果,所以如果HDSF上文件数据量达到一定量之后,会使NN节点崩溃,所以Hadop上存储的文件推荐是大文件,因为如果存储的都是很多小文件很可能将NN内存占满,导致无法向HDFS上写入数据.Client如果向HDFS读取文件会首先访问NN,在NN中找到文件元数据信息(比如:所在节点,每个节点的第几块),之后根据元访问各个DN得到数据.
Secondary NameNode
是辅助名称节点,可以理解成对NN的备份,但又不仅仅是做备份工作,SNN会定期和NN之间做通讯,保存元数据快照.当NN挂掉之后可以启动SNN作为一个临时NN,但是这个过程是管理员手动完成Hadoop并不会自动切换.NN将fsimage读取到内存中,当Hadoop操作文件之后fsimage会更新,未防止数据丢失这些更新会记录到本地一个名位edits的日志文件中,fsimage并不存储数据块的位置,这些数据块其实是DN启动时向NN进行汇报之后存储在内存中.edits用来记录hadoop在运行过程中HDFS上文件的变化情况,当Hadoop重启后edits会和fsimage进行合并,可想而知当hadoop启动时候进行fsimage和edits数据合并这会严重拖慢系统运行,所有这个合并操作就是通过SNN来完成.SNN的任务就是周期性的对NN中的fsimage和edits进行合并,具体合并步骤如下:
1. SNN通知NN要合并镜像文件,此时让NN结果对edits的修改,如果有修改请放到一个新文件中edits.new
2. SNN向NN请求fsimage和edits文件
3. SNN合并fsimage和edits生成新的fsimage
4. NN接受SNN新生成的fsimage后替换当前的fsimage并将之前的新的edits.new 内容替换到edtis中
5. 更新fsimage记录(检查点)
在SNN上重要文件如下:
1. fsimage 镜像文件:记录了文件系统元数据信息
2. edits 修改日志:记录对fsimage元数据修改信息
3. fstime : 最近一次检查点信息
DataNode
数据节点,主要负责对HDFS上文件的读写操作,NN\SNN\DN一同构成了HDFS系统. Hadoop结构图如下:
3. MapReduce
MR是一种编程范式,主要由两个任务构成Map操作和Reduce操作
Map阶段:Map阶段由一系列的MapTask构成,主要流程如下:
1. InputFormat :将数据数据源解析成Key-Value对形式,具体解析方式可以自己定义,Hadoop预定义了几种常见方式
2. Mapper:输入数据处理,对每一对Key-Value进行处理(需要自己编程实现,业务相关)形成新的Key-Value
3. Partitioner:数据分组,将Mapper结果进行分组,确定每一个Key-Value对需要被那个Reduce处理.该步骤可以自定义也可以使用Hadoop内置的Partitioner(Hash 分桶)
4. 将每个节点计算完成的数据输出,如果Map后没有Reduce阶段则直接输出到HDFS,如果有Reduce阶段则输出到NN本地节点以供Reduce阶段读取
Reduce 阶段:Reduce阶段由一系列的ReductTask组成,过程如下:
1. Shuffle:数据远程拷贝,将本节点需要处理的数据通过网络从Map节点拷贝到本地
2. Sort: 把所有数据按照Key排序,提高处理速度和性能
3. Reducer: 业务处理,需要用户自己编程
4. OutputFormat:数据输出将处理的结果输出到HDSF,该过程可以用户自定义也可以使用系统内置输出格式.
具体流程如下:
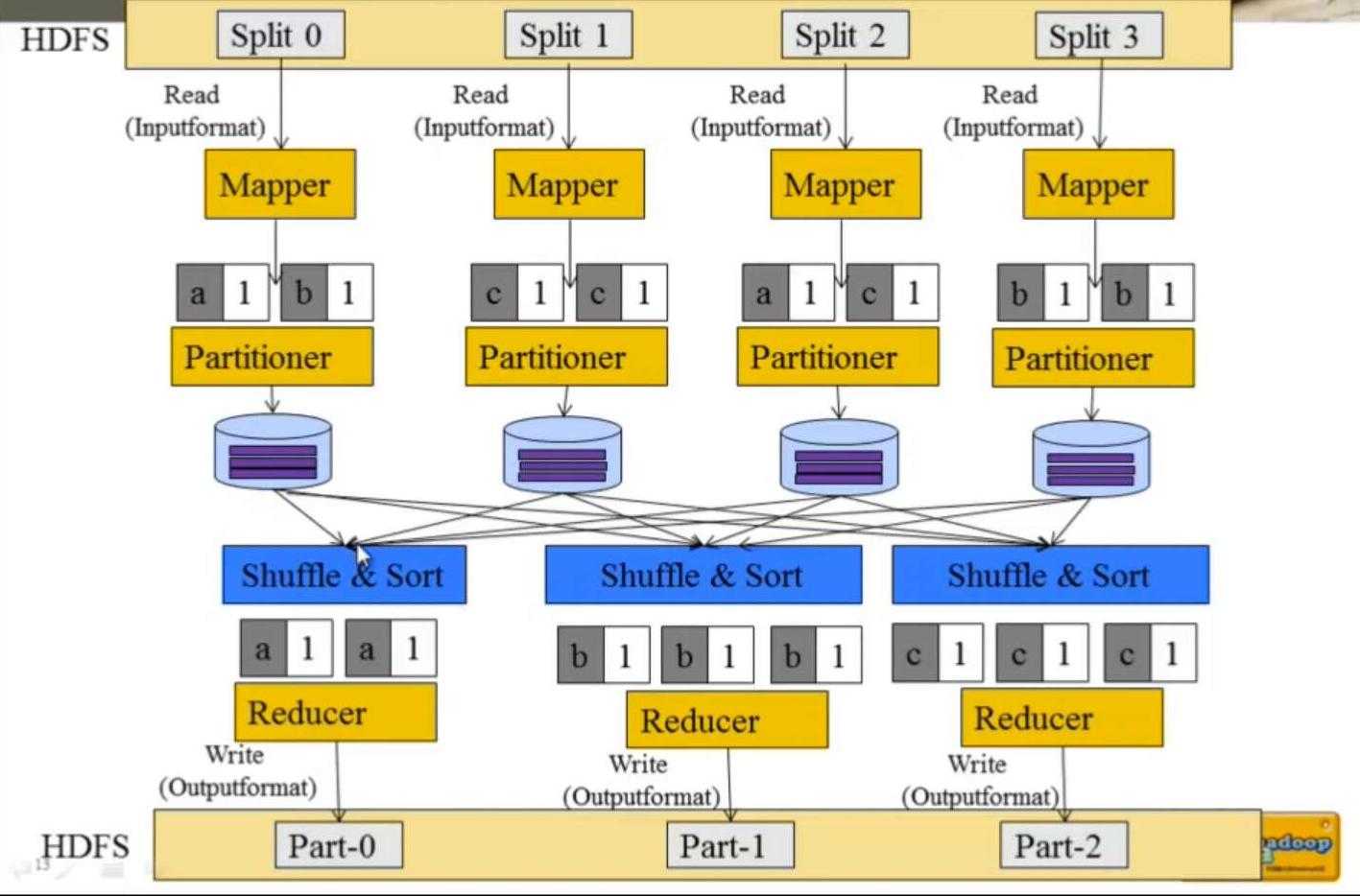
流程解析:
- 将HDFS上的数据以Split的方式输入到MR,Split是MR最小的计算单元,Block是HDFS的存储单元,两个并不矛盾,block只是机械的将数据按照数据块大小进行切分,这样极有可能将一行数据阶段,默认情况一个Split对应一个Block但是这种匹配关系是可以修改的,这种对应关系是有InputFormat决定,所在在InputFormat中会处理数据换行问题.InputFormat将数据处理成多个KeyValue对,之后交给Mapper处理
- 用户对Mapper的输出进行业务处理,之后将其输出成需要的K-V
- Mapper解析的K-V经过Partitioner处理后就会知道需要选择那个Reducer处理K-V对,并保存到本地磁盘
- 每个Reduce都需要从网络拉去需要处理的数据,该阶段称为Shuffle,拉去完成之后对数据进行排序,最后才作为Reduce计算的输入
- 对Reduce的结果通过OutputFormat格式输出到HDFS上
MapReduce计算结构:
MR和HDFS一样也是Master-Slave结构,该图是hadoop 1.0的任务运行图
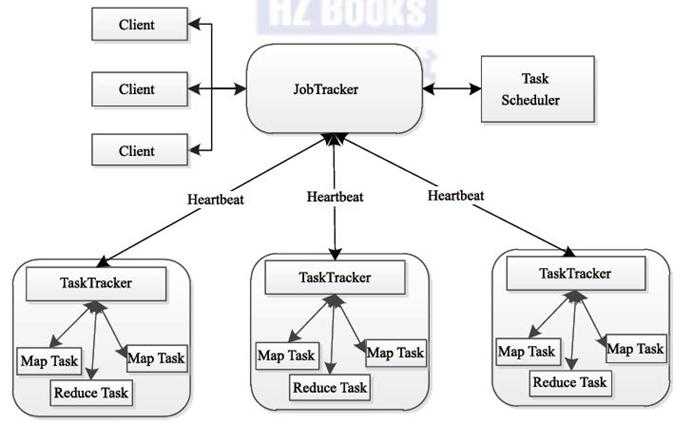
client将任务提交到JobTracker,JobTracker负责集群资源监控和任务调度.JobTracker将任务分割成多个MapTask和ReduceTask.并把这些Task分发到指定的TaskTracker.并监视TaskTracker和Job的运行情况,当发现任务失败后,将其转移到其他节点.JobTascker会监控任务的运行资源和状态信息,并将这些信息通知给任务调度器,而任务调度器会在资源空闲时将这些资源分配其他任务.
TaskTracker:TaskTracker负责通过心跳向JobTracker报告本节点资源情况(CPU\内存\磁盘等),同时还会接受JobTracker发送过来的命令(启动|结束服务等).TaskTracker将资源划分成很多槽位slot(后续介绍),一个任务之后获取到指定的槽位之后才可以运行,hadoop 调度器就是将空闲的槽位分配给等待的Task.
小总结:
JobTracker任务
- MR的Master节点
- 管理所有作业
- 将作业分解成很多任务
- 将任务指派给TaskTracker
- 作业/资源监控,错误处理
TaskTracker任务
- MR的Slave节点
- 运行MapTask和ReductTask
- 和JobTracker交互,执行接收的命令,并汇报任务状态
Task:任务分为MapTask和ReduceTask,Task都是通过TaskTracker启动.
HDFS存储是以block为单位存储的,但是MR是以Split位单位计算,所以就涉及到Split和Block对应的问题,其实在Split中只保存了数据的元数据信息,比如数据的开始位置,长度,数据所在那个节点等信息.其Split的划分方式可以完成由用户指定(自己实现InputFormat),Split的多少就决定了MapTask的数据,因为一个Split只会交给一个Map Task.Split和Block的对应关系如下:
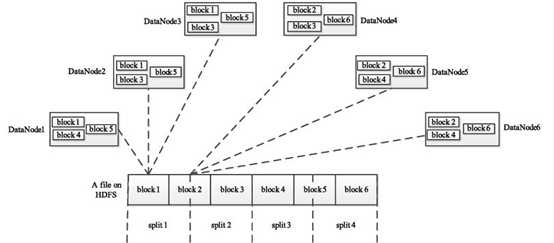
HDSF中每一个block会分散到不同节点上,但是每一个split可以有多个block组成
Map Task执行流程:
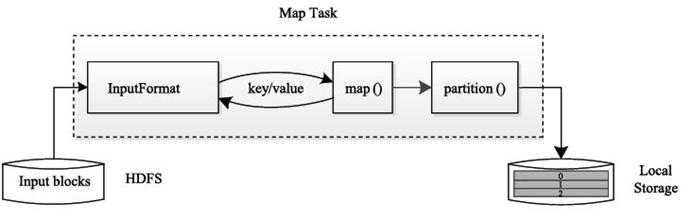
MapTask从HDFS上依次读取各个Split,对每个Split通过InputFormat解析成Key/Value对,之后调用用户自定义map()行函数,将结果调用partition后保存在本地磁盘
Reduct Task执行流程:
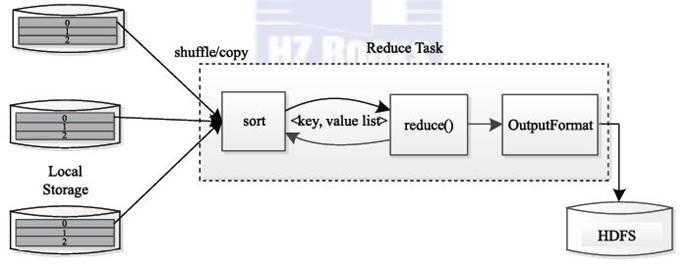
每一个ReductTask从各个Map中拉取需要处理的数据(比如该ReductTask需要处理 分片1,则从Map节点拉取编号为1的数据)到本地,该操作称为Shuffle,之后对所有的数据按照Key排序,将每一个Key和它的所有数据 value list,作为输入调用reduce()函数,最后将结果输出到HDFS上,每一个Reduct对每一个分片都会形成一个 partition-x 的结果.
MapReduct 流程调度图:
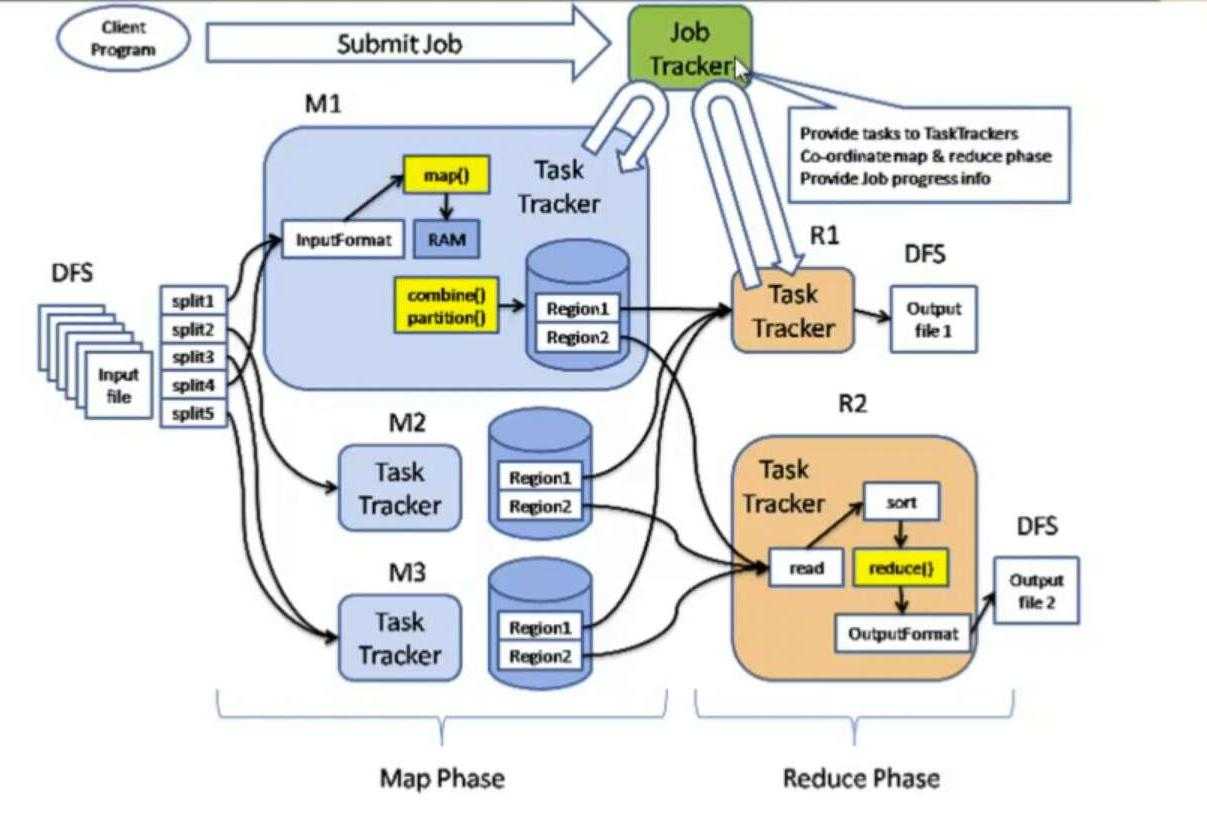
MapReduct 资源管理(1.0)
1.0 的资源管理是通过JobTracker和TaskTracker完成的,1.0 是将任务管理和资源管理都在一个组件中处理(不好). Hadoop 1.0 的资源有两部分组成:资源表示模型和资源分配模型,
其中资源表示模型用于描述资源组织方式,Hadoop1.0 使用槽位组织各个节点资源,而资源分配模型决定如何将资源分配给各个任务.
Hadoop 将各个节点的资源(包括CPU\内存\硬盘)切分成若干份,每一位代表一个槽位,同时规定每一个任务可以占用多个槽位.槽位其实就是任务运行的许可证,一个任务得到槽位后
才能开始执行,否则就要处于等待状态.所以节点上槽位的多少就定了该节点可以并发的个数.槽位也分类型,Map和Reduce都有各自的槽位数,这个数用户可以自定义
mapred.tasktracker.map.tasks.maxinum | mapred.tasktrackerreduce.tasks.maxinum.
hadoop1.0 资源管理的缺点:
1. 静态资源配置:每个节点的资源配置一旦确定,就无法更改
2. 资源无法共享:节点资源被分割成Map槽位和Reduce槽位,两个槽位之间不允许共享,对于一个作业,Map时,Map槽位开始使用,但是Reduce槽位处于空闲状态,这样就降低队了
槽位的利用率
3. 资源划分粒度过大:槽位大小是事先规定好的,比如1个槽位:2G 内存1个CPU, 假如一个任务只需要1G内存,这样就造成了1G内存的浪费,反之依然
4. 资源没有隔离机制:1. 0 采用JVM资源隔离,这样其实在一个节点上并没有对资源进行隔离,可能会导致节点任务之间影响降低效率.
hadoop 2.0 资源管理方案:
hadoop2.0 使用了Yarn对资源进行管理,Hadoop 只有HDS和MapReduce两部分组成,Yarn 负责集群资源的管理和调度,MR只是部署在Yarn上的离线应用,当然Yarn也可以不熟其他应用比如Spark等.如果说2.0 的资源
管理其实就是说Yarn对资源的管理:
资源其实是多个维度,CPU\内存\硬盘等等,如果简单将他们映射成一个维度,就是1.0的槽位就会有1.0 对资源管理的缺点,所以Yarn中对资源的管理并非使用1.0中的槽位,而是使用最直接最简单方式,直接要资源,比如
申请2G内存,1个CPU.Yarn会对任务进行资源的精细分配.
Yarn要求对每一个节点配置其资源使用总量,而中央调度器负责收集各个节点的资源,并将其分配给各个应用程序.节点配置参数如下:
1. 配置物理内存最大使用量
yarn.nodemanager.resource.memory-mb
2. 配置单位物理内存最多可使用虚拟内存的比例
yarn.nodemanager.vmem-pmen-ratio
比如: 2.1 ,代表,1M的物理内存,最多可使用的虚拟内存量位2.1M
3. 可分配虚拟CPU个数
yarn.nodenamager.recource.cpu-vcore
yarn可以对每个节点配置虚拟CPU数
目前Yarn引用cgroup的资源隔离方案降低各任务之间的干扰.